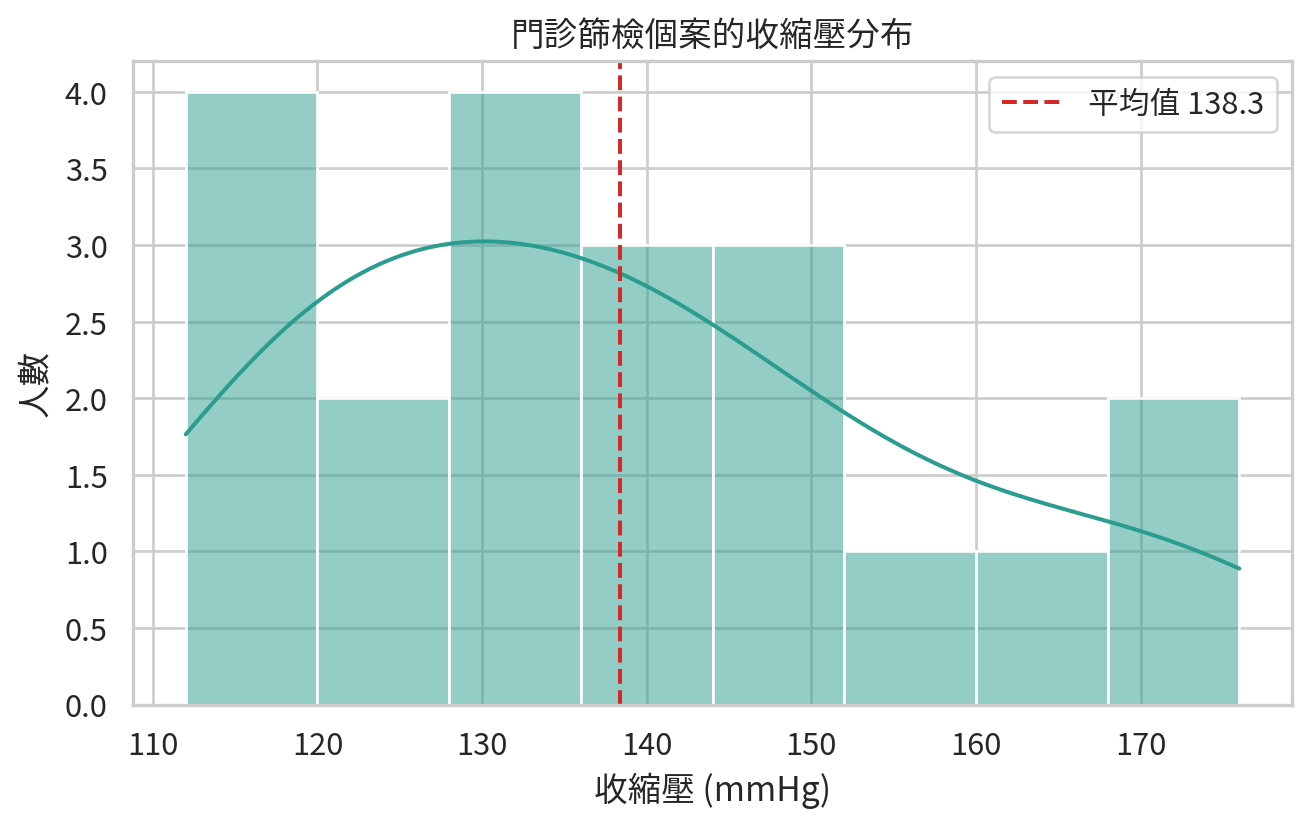
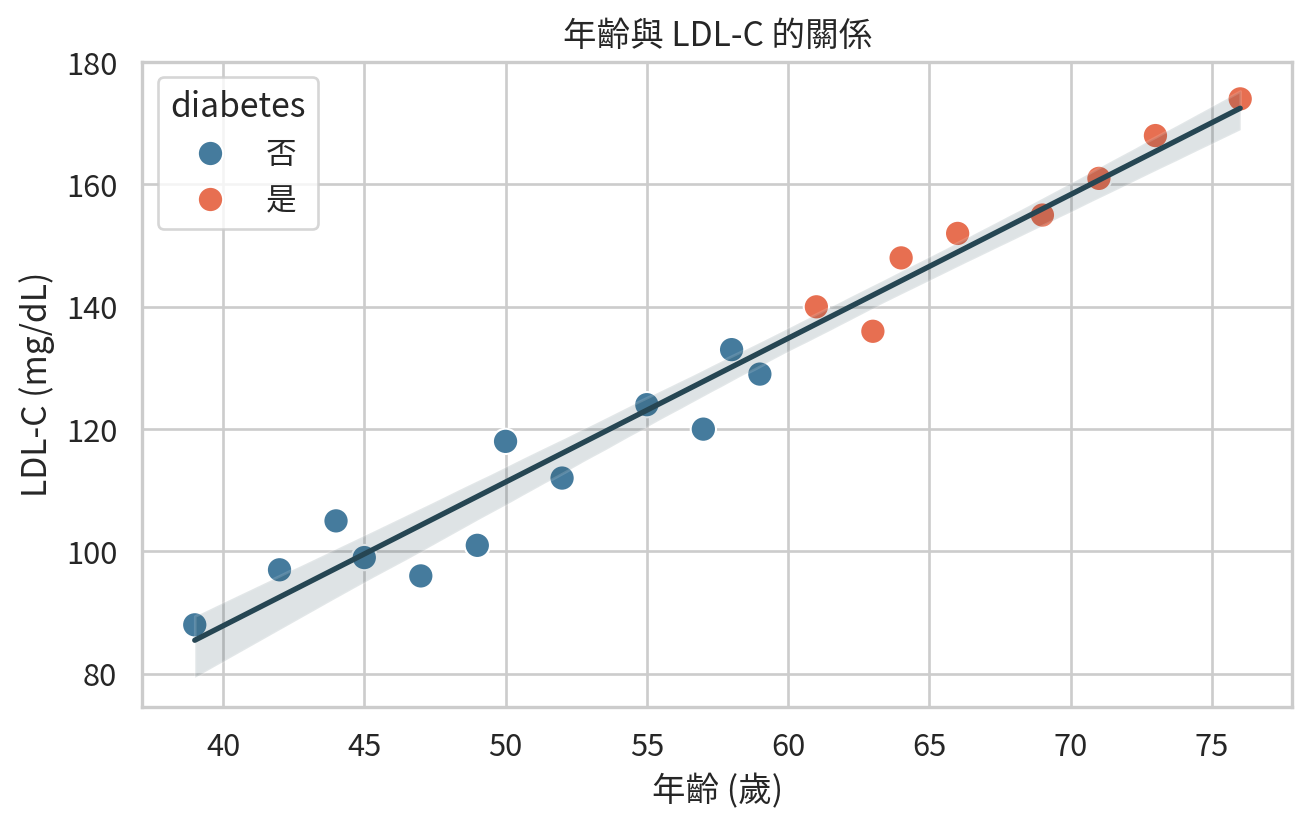
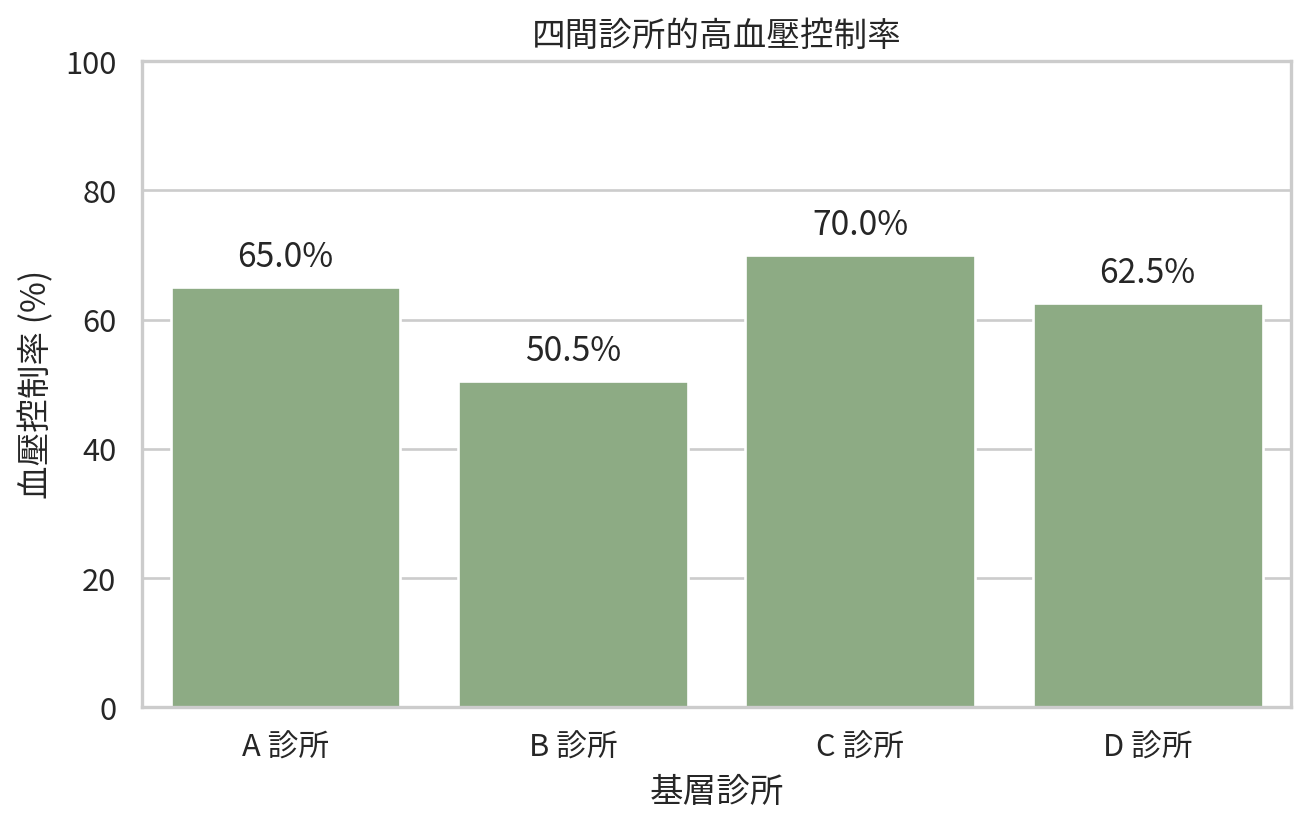
screening = pd.DataFrame(
{
"id": range(1, 21),
"sex": [
"女", "男", "女", "男", "女",
"女", "男", "男", "女", "男",
"女", "女", "男", "女", "男",
"女", "男", "女", "男", "女",
],
"age": [52, 64, 47, 71, 58, 39, 66, 55, 44, 73, 61, 49, 57, 69, 42, 63, 50, 76, 45, 59],
"sbp": [128, 151, 116, 166, 137, 112, 149, 134, 121, 172, 145, 119, 132, 158, 123, 141, 130, 176, 118, 139],
"ldl": [112, 148, 96, 161, 133, 88, 152, 124, 105, 168, 140, 101, 120, 155, 97, 136, 118, 174, 99, 129],
"diabetes": [
"否", "是", "否", "是", "否",
"否", "是", "否", "否", "是",
"是", "否", "否", "是", "否",
"是", "否", "是", "否", "否",
],
}
)
screening.head()