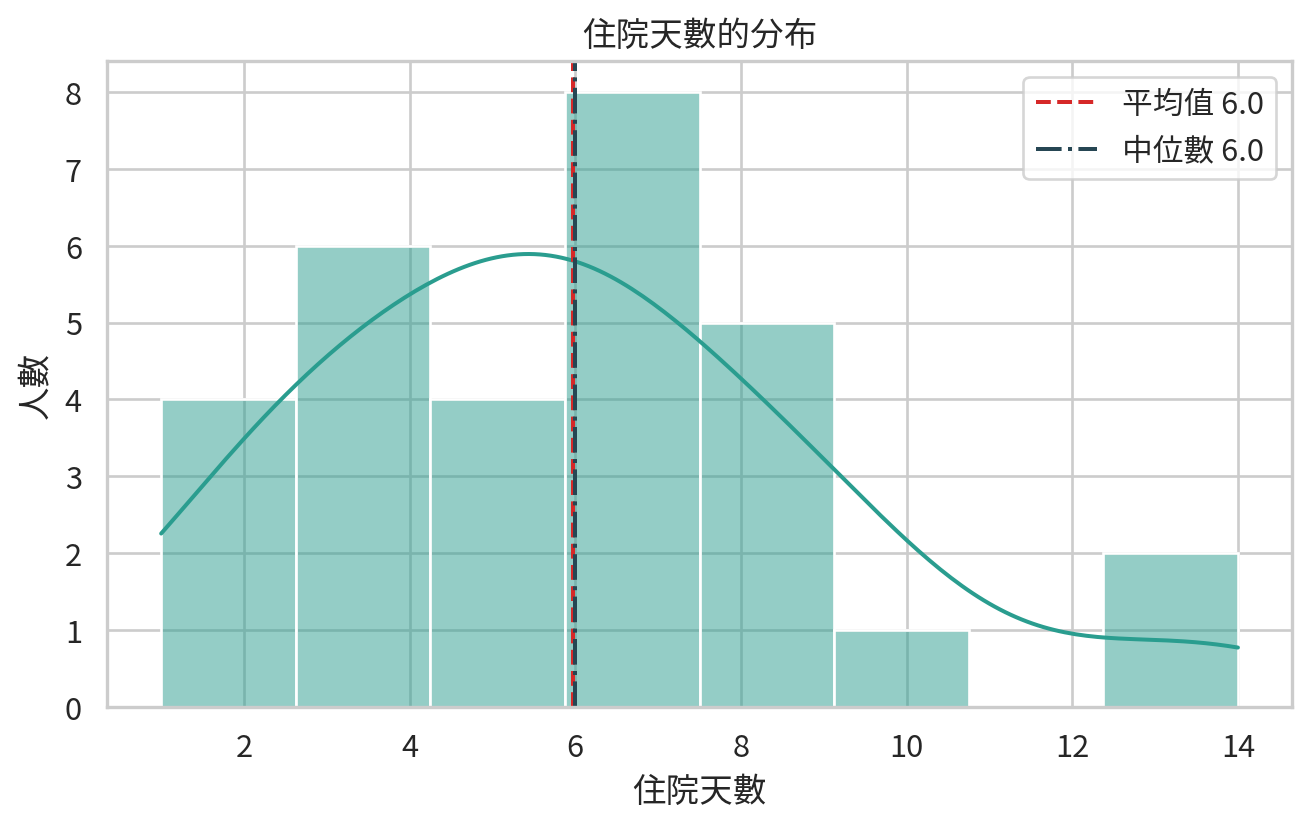
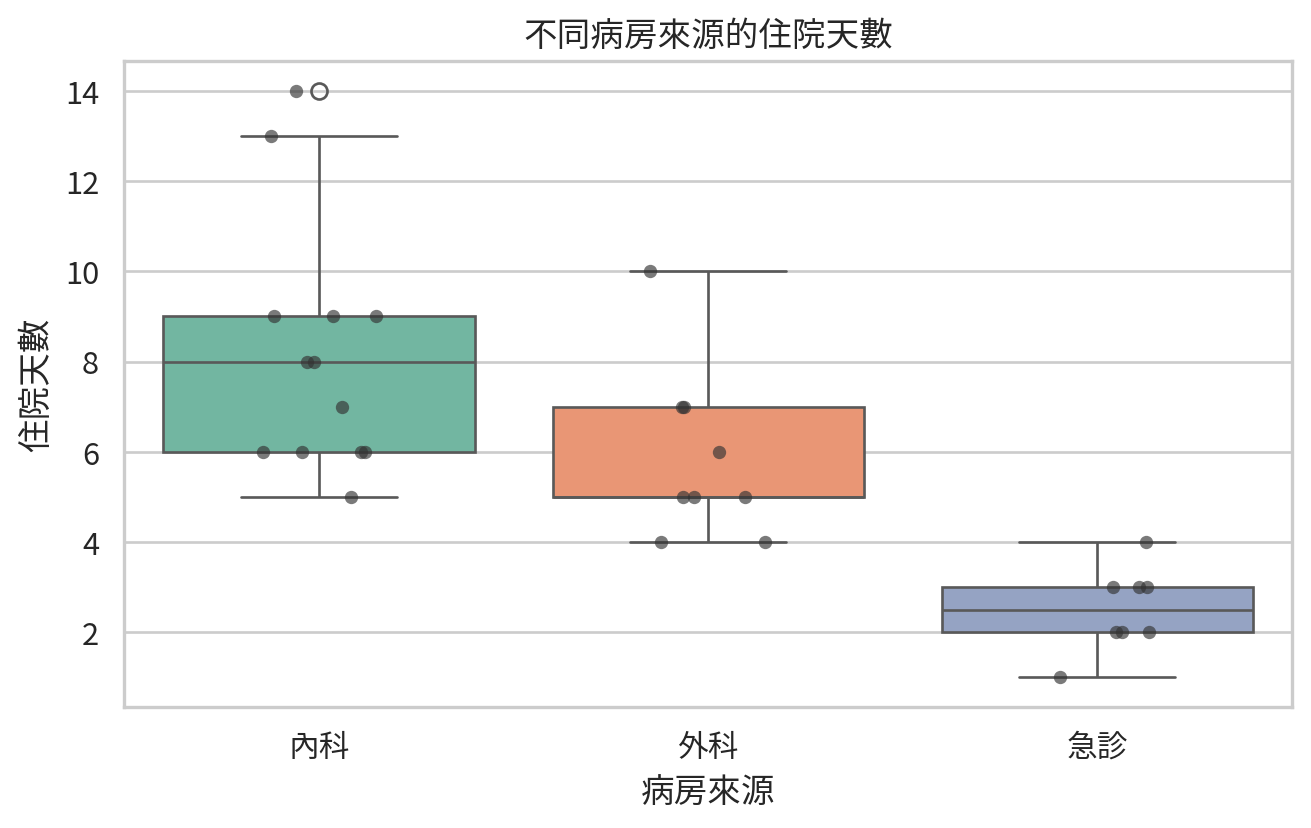
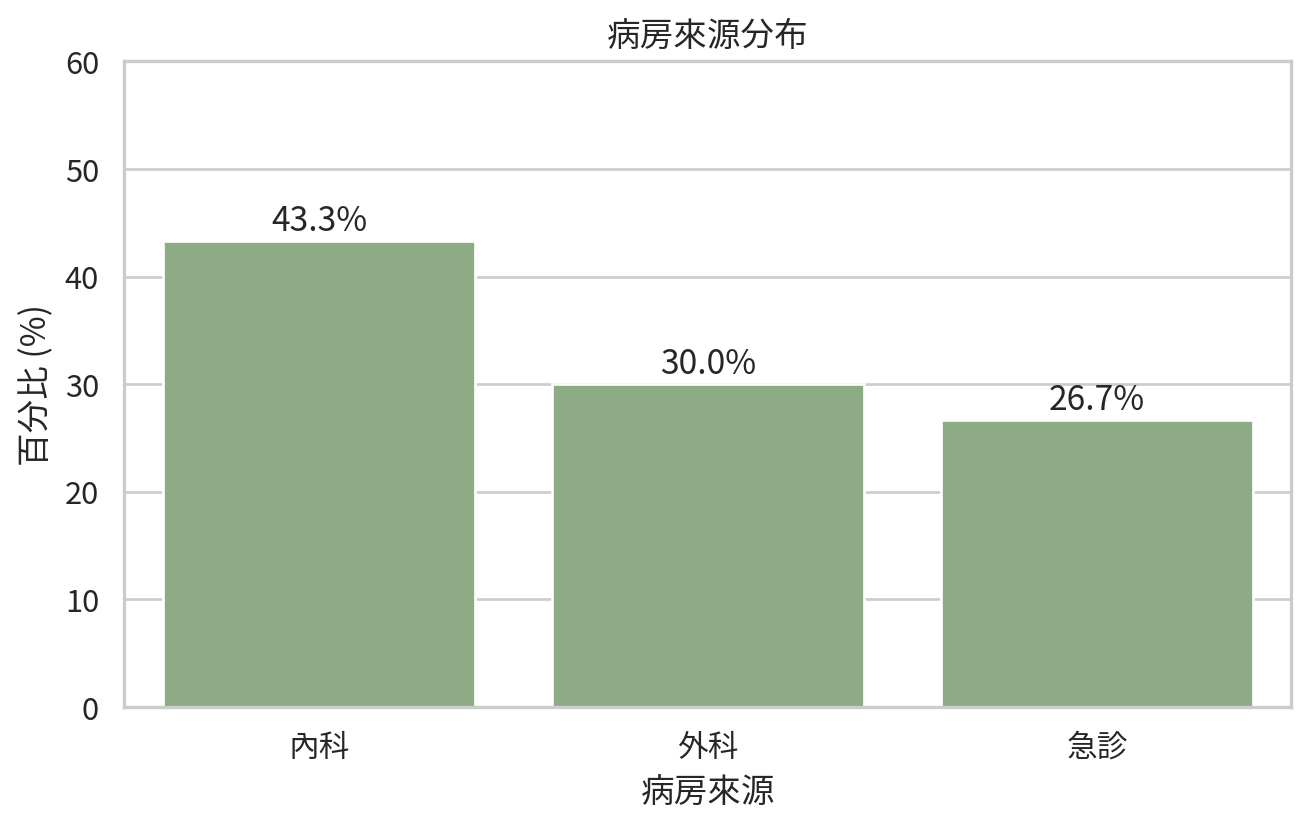
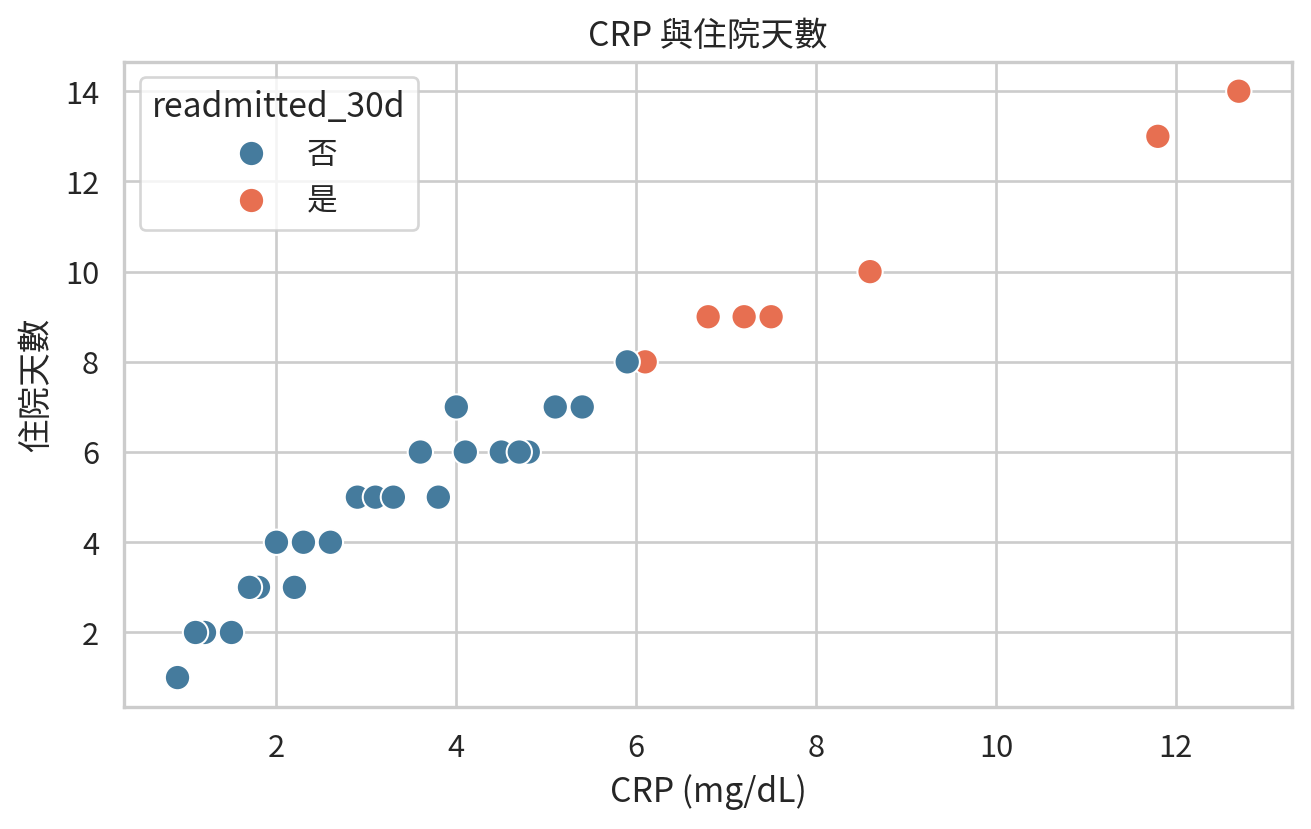
patients = pd.DataFrame(
{
"id": range(1, 31),
"ward": [
"內科", "內科", "外科", "內科", "急診", "外科", "內科", "急診", "外科", "內科",
"急診", "外科", "內科", "內科", "急診", "外科", "內科", "急診", "外科", "內科",
"內科", "外科", "急診", "內科", "外科", "急診", "內科", "外科", "急診", "內科",
],
"sex": [
"女", "男", "男", "女", "男", "女", "女", "男", "女", "男",
"女", "男", "男", "女", "男", "女", "女", "男", "男", "女",
"男", "女", "男", "女", "男", "女", "女", "男", "女", "男",
],
"age": [72, 65, 58, 80, 44, 69, 76, 51, 62, 70, 39, 73, 68, 85, 47, 60, 78, 55, 66, 74, 71, 64, 42, 83, 59, 49, 77, 61, 53, 69],
"los": [6, 5, 4, 9, 2, 7, 8, 3, 5, 6, 1, 10, 6, 14, 2, 5, 9, 4, 7, 8, 6, 5, 2, 13, 4, 3, 9, 6, 3, 7],
"crp": [4.1, 3.8, 2.0, 7.5, 1.2, 5.4, 6.1, 1.8, 2.9, 4.8, 0.9, 8.6, 4.5, 12.7, 1.5, 3.1, 7.2, 2.3, 4.0, 5.9, 4.7, 3.3, 1.1, 11.8, 2.6, 1.7, 6.8, 3.6, 2.2, 5.1],
"readmitted_30d": [
"否", "否", "否", "是", "否", "否", "是", "否", "否", "否",
"否", "是", "否", "是", "否", "否", "是", "否", "否", "否",
"否", "否", "否", "是", "否", "否", "是", "否", "否", "否",
],
}
)
patients.head()