本章學習目標
上一章我們處理一個樣本與一個基準值的比較。臨床與公衛研究更常見的問題是兩組比較:新治療與標準治療哪個好?介入前後是否改善?兩種照護模式的再住院率是否不同?這些都屬於兩樣本推論 (two-sample inference)。
讀完本章後,你應該能夠:
- 區分獨立樣本 (independent samples) 與配對樣本 (paired samples)。
- 執行兩獨立樣本 t 檢定 (two-sample t-test) 與 Welch t 檢定 (Welch's t-test)。
- 執行配對 t 檢定 (paired t-test)。
- 比較兩個母群體比例 (two population proportions)。
- 建立平均差 (mean difference)、比例差 (risk difference) 與相對風險 (relative risk) 的估計與信賴區間。
- 從效果大小、信賴區間與臨床意義一起解讀兩組比較。
兩組比較先問:獨立還是配對?
兩組資料最重要的第一個問題不是「要按哪個軟體按鈕」,而是資料結構。若兩組來自不同個體,例如標準照護組與介入照護組各自收案不同病人,這通常是獨立樣本。若兩個測量值來自同一個人,例如治療前與治療後血壓,這是配對樣本。
獨立樣本與配對樣本的分析方法不同。配對資料的核心是每個人的前後差異,而不是把治療前與治療後當成兩群陌生人。若忽略配對,會浪費資訊,甚至得到錯誤結論。統計方法很重視資料關係;資料之間若本來有牽手,請不要硬把它們拆散。
兩獨立樣本平均值比較
兩獨立樣本平均值比較常用於比較兩組病人的連續結果,例如收縮壓、LDL-C、住院天數或疼痛分數。令 \(\mu_1\) 與 \(\mu_2\) 為兩組母群體平均值,常見雙尾假設為:
\[
H_0: \mu_1 - \mu_2 = 0
\]
\[
H_1: \mu_1 - \mu_2 \ne 0
\]
若兩組變異數可視為相等,可使用 pooled two-sample t-test。但醫療資料中兩組變異數常不同,Welch t 檢定較穩健,通常是很好的預設選擇。
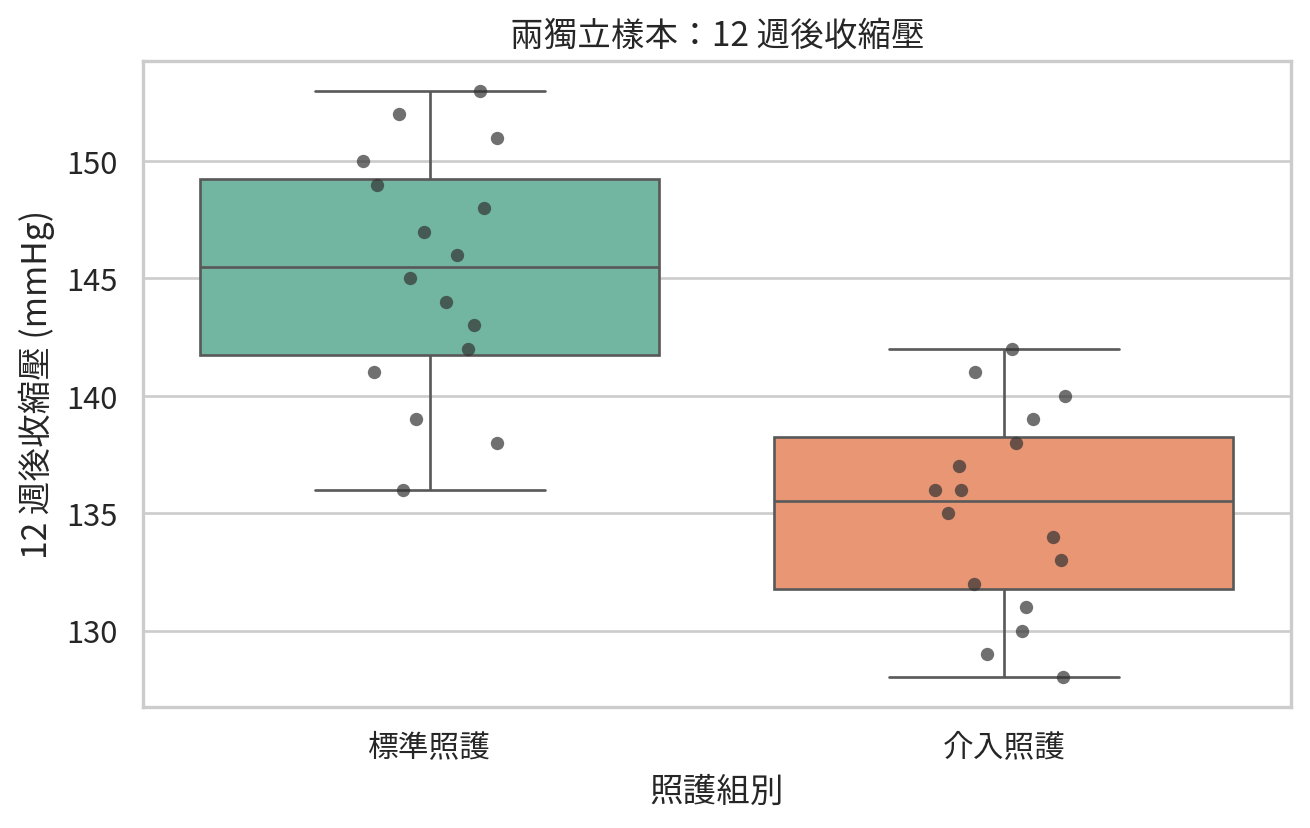
範例 1:兩組照護模式的收縮壓
假設某研究比較標準照護與介入照護在 12 週後的收縮壓。兩組病人互相獨立。
standard = np.array([148, 142, 151, 139, 145, 150, 136, 144, 147, 153, 141, 149, 146, 138, 152, 143])
intervention = np.array([136, 132, 141, 129, 135, 138, 131, 134, 137, 140, 133, 139, 130, 128, 142, 136])
bp_groups = pd.DataFrame(
{
"sbp": np.r_[standard, intervention],
"group": ["標準照護"] * len(standard) + ["介入照護"] * len(intervention),
}
)
bp_groups.groupby("group")["sbp"].agg(["count", "mean", "std"]).round(2)
| group |
|
|
|
| 介入照護 |
16 |
135.06 |
4.33 |
| 標準照護 |
16 |
145.25 |
5.16 |
plt.figure(figsize=(7, 4.5))
sns.boxplot(data=bp_groups, x="group", y="sbp", hue="group", palette="Set2", legend=False)
sns.stripplot(data=bp_groups, x="group", y="sbp", color="#333333", alpha=0.7, jitter=0.12)
plt.xlabel("照護組別")
plt.ylabel("12 週後收縮壓 (mmHg)")
plt.title("兩獨立樣本:12 週後收縮壓")
plt.tight_layout()
plt.savefig(FIG_DIR / "ch08_independent_sbp_boxplot.png", dpi=300)
plt.show()
welch_result = ttest_ind(intervention, standard, equal_var=False)
mean_diff = intervention.mean() - standard.mean()
se_welch = np.sqrt(intervention.var(ddof=1) / len(intervention) + standard.var(ddof=1) / len(standard))
df_welch = (intervention.var(ddof=1) / len(intervention) + standard.var(ddof=1) / len(standard)) ** 2 / (
(intervention.var(ddof=1) / len(intervention)) ** 2 / (len(intervention) - 1)
+ (standard.var(ddof=1) / len(standard)) ** 2 / (len(standard) - 1)
)
ci_mean = t.interval(0.95, df=df_welch, loc=mean_diff, scale=se_welch)
pd.DataFrame(
{
"quantity": ["平均差:介入-標準", "Welch t 統計量", "自由度", "p 值", "95% CI 下限", "95% CI 上限"],
"value": [mean_diff, welch_result.statistic, df_welch, welch_result.pvalue, ci_mean[0], ci_mean[1]],
}
).round(4)
| 0 |
平均差:介入-標準 |
-10.1875 |
| 1 |
Welch t 統計量 |
-6.0526 |
| 2 |
自由度 |
29.1220 |
| 3 |
p 值 |
0.0000 |
| 4 |
95% CI 下限 |
-13.6294 |
| 5 |
95% CI 上限 |
-6.7456 |
平均差為負值,代表介入組平均收縮壓較低。p 值與信賴區間都提供證據支持兩組平均值不同。不過,接著仍要問:下降幅度是否達到臨床上重要?是否有副作用、成本或可行性問題?統計顯著是門票,不是整場演出。
Pooled t 檢定與 Welch t 檢定
Pooled t 檢定假設兩組母群體變異數相同,會把兩組變異合併估計共同變異。Welch t 檢定不要求兩組變異數相等,並使用調整後自由度。實務上,若不確定變異數是否相等,Welch t 檢定通常較安全。
假設變異數相等與否不應只靠「看起來差不多」。更重要的是研究設計與資料來源是否支持這個假設。醫療資料裡,不同病情嚴重度、不同治療路徑常讓變異不一樣。
pooled_result = ttest_ind(intervention, standard, equal_var=True)
pd.DataFrame(
{
"method": ["Pooled t-test", "Welch t-test"],
"t_statistic": [pooled_result.statistic, welch_result.statistic],
"p_value": [pooled_result.pvalue, welch_result.pvalue],
}
).round(4)
| 0 |
Pooled t-test |
-6.0526 |
0.0 |
| 1 |
Welch t-test |
-6.0526 |
0.0 |
配對樣本平均值比較
配對 t 檢定適用於同一個體的前後測量,或自然配對的資料,例如左右眼、同一病人兩種檢驗方法、同一社區介入前後。配對 t 檢定的關鍵不是比較兩組原始平均值,而是比較「差值」的平均是否為 0。
令 \(D_i = X_{after,i} - X_{before,i}\),假設為:
\[
H_0: \mu_D = 0
\]
\[
H_1: \mu_D \ne 0
\]
若差值平均顯著小於 0,代表治療後數值下降。
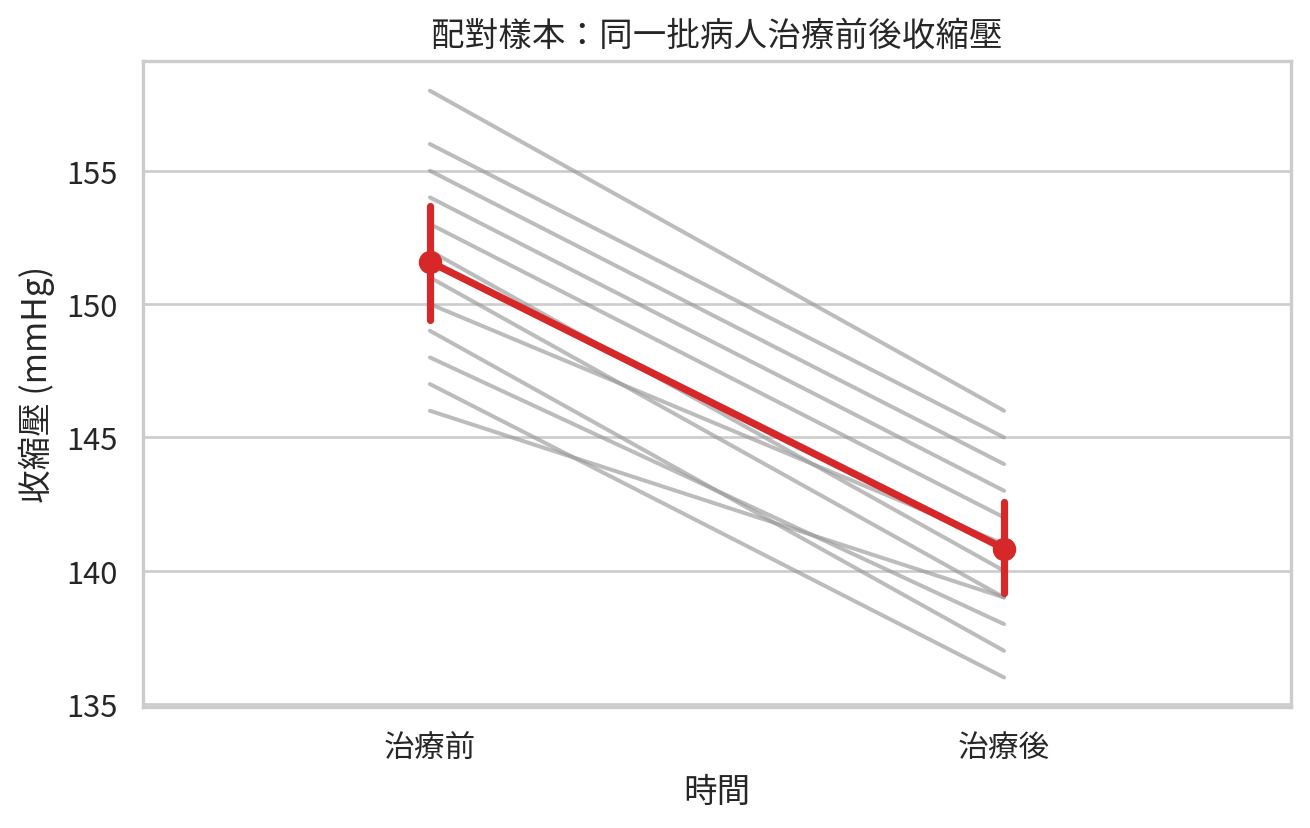
範例 2:同一批病人治療前後收縮壓
before = np.array([152, 148, 155, 146, 150, 158, 149, 153, 147, 156, 151, 154])
after = np.array([140, 138, 144, 139, 141, 146, 137, 142, 136, 145, 139, 143])
paired_df = pd.DataFrame({"id": np.arange(1, len(before) + 1), "before": before, "after": after})
paired_df["difference"] = paired_df["after"] - paired_df["before"]
paired_df[["before", "after", "difference"]].agg(["mean", "std"]).round(2)
| mean |
151.58 |
140.83 |
-10.75 |
| std |
3.75 |
3.21 |
1.48 |
paired_long = paired_df.melt(id_vars="id", value_vars=["before", "after"], var_name="time", value_name="sbp")
paired_long["time"] = paired_long["time"].map({"before": "治療前", "after": "治療後"})
plt.figure(figsize=(7, 4.5))
for _, row in paired_df.iterrows():
plt.plot(["治療前", "治療後"], [row["before"], row["after"]], color="#999999", alpha=0.65)
sns.pointplot(data=paired_long, x="time", y="sbp", errorbar=("ci", 95), color="#d62828", markers="o")
plt.xlabel("時間")
plt.ylabel("收縮壓 (mmHg)")
plt.title("配對樣本:同一批病人治療前後收縮壓")
plt.tight_layout()
plt.savefig(FIG_DIR / "ch08_paired_sbp_lines.png", dpi=300)
plt.show()
paired_result = ttest_rel(after, before)
diff_mean = paired_df["difference"].mean()
diff_se = paired_df["difference"].std(ddof=1) / np.sqrt(len(paired_df))
diff_ci = t.interval(0.95, df=len(paired_df) - 1, loc=diff_mean, scale=diff_se)
pd.DataFrame(
{
"quantity": ["平均差:後-前", "配對 t 統計量", "p 值", "95% CI 下限", "95% CI 上限"],
"value": [diff_mean, paired_result.statistic, paired_result.pvalue, diff_ci[0], diff_ci[1]],
}
).round(4)
| 0 |
平均差:後-前 |
-10.7500 |
| 1 |
配對 t 統計量 |
-25.0807 |
| 2 |
p 值 |
0.0000 |
| 3 |
95% CI 下限 |
-11.6934 |
| 4 |
95% CI 上限 |
-9.8066 |
配對分析通常比把前後資料當獨立樣本更有效率,因為每位病人都作為自己的對照。個體間差異被抵消後,治療前後差異更容易被看見。
兩比例比較
若結果是二元事件,例如再住院、有無感染、是否達標,常比較兩組比例。常見效果量包括比例差、相對風險與勝算比。本章先聚焦比例差與相對風險。
比例差又稱風險差 (risk difference):
\[
\hat{p}_2 - \hat{p}_1
\]
相對風險 (relative risk, RR) 為:
\[
RR = \frac{\hat{p}_2}{\hat{p}_1}
\]
比例差回答「絕對差多少」,相對風險回答「相對於原本是多少倍」。臨床與公衛決策常需要兩者一起看。
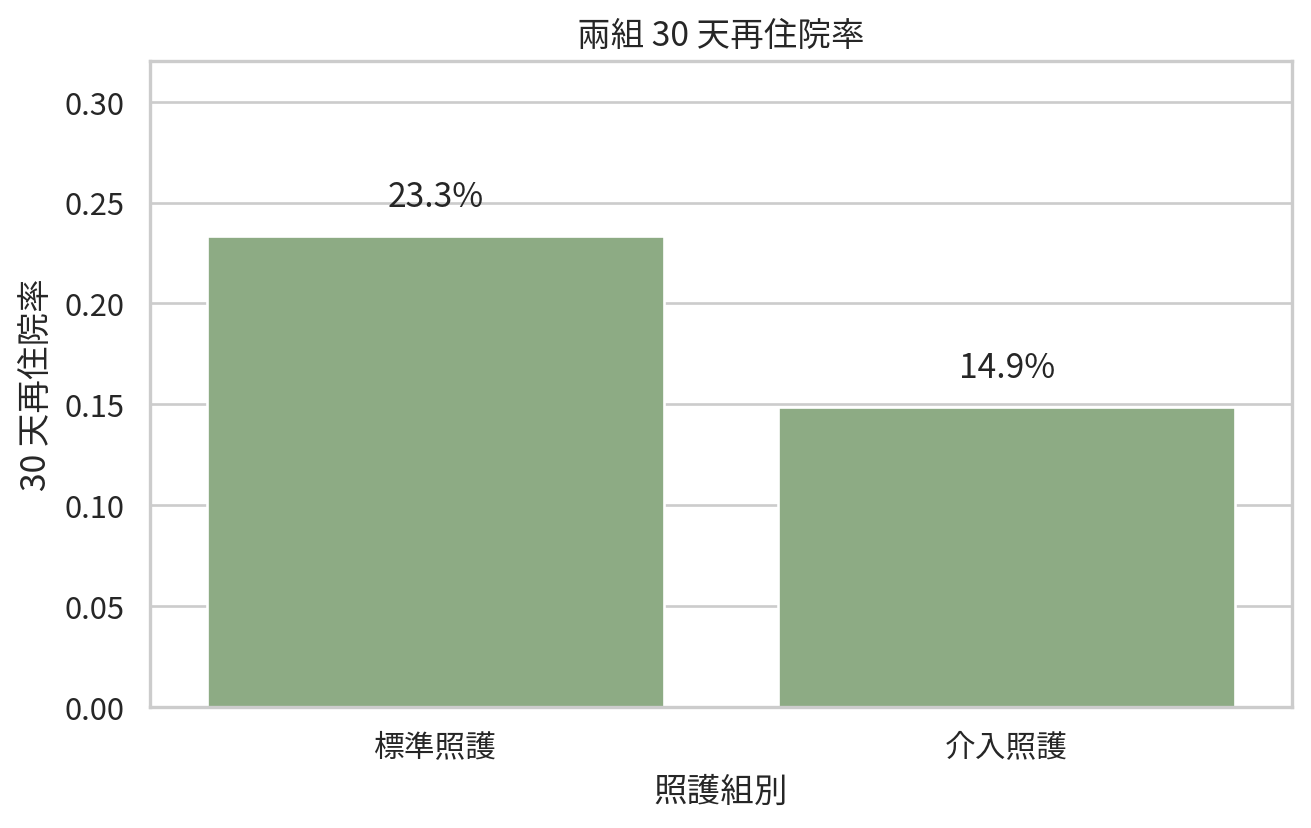
範例 3:兩組 30 天再住院率
prop_df = pd.DataFrame(
{
"group": ["標準照護", "介入照護"],
"n": [180, 175],
"readmit": [42, 26],
}
)
prop_df["rate"] = prop_df["readmit"] / prop_df["n"]
prop_df
| 0 |
標準照護 |
180 |
42 |
0.233333 |
| 1 |
介入照護 |
175 |
26 |
0.148571 |
plt.figure(figsize=(7, 4.5))
sns.barplot(data=prop_df, x="group", y="rate", color="#8ab17d")
plt.ylim(0, 0.32)
plt.xlabel("照護組別")
plt.ylabel("30 天再住院率")
plt.title("兩組 30 天再住院率")
for index, row in prop_df.iterrows():
plt.text(index, row["rate"] + 0.015, f"{row['rate']:.1%}", ha="center")
plt.tight_layout()
plt.savefig(FIG_DIR / "ch08_two_proportion_readmission.png", dpi=300)
plt.show()
x1, n1 = prop_df.loc[0, ["readmit", "n"]]
x2, n2 = prop_df.loc[1, ["readmit", "n"]]
p1 = x1 / n1
p2 = x2 / n2
pooled_p = (x1 + x2) / (n1 + n2)
se_null = np.sqrt(pooled_p * (1 - pooled_p) * (1 / n1 + 1 / n2))
z_stat = (p2 - p1) / se_null
p_value = 2 * min(norm.cdf(z_stat), 1 - norm.cdf(z_stat))
diff_prop = p2 - p1
se_diff_prop = np.sqrt(p1 * (1 - p1) / n1 + p2 * (1 - p2) / n2)
ci_prop = (diff_prop - norm.ppf(0.975) * se_diff_prop, diff_prop + norm.ppf(0.975) * se_diff_prop)
relative_risk = p2 / p1
pd.DataFrame(
{
"quantity": ["比例差:介入-標準", "比例差 CI 下限", "比例差 CI 上限", "z 統計量", "p 值", "相對風險"],
"value": [diff_prop, ci_prop[0], ci_prop[1], z_stat, p_value, relative_risk],
}
).round(4)
| 0 |
比例差:介入-標準 |
-0.0848 |
| 1 |
比例差 CI 下限 |
-0.1660 |
| 2 |
比例差 CI 上限 |
-0.0036 |
| 3 |
z 統計量 |
-2.0290 |
| 4 |
p 值 |
0.0425 |
| 5 |
相對風險 |
0.6367 |
比例差為負值,表示介入照護組再住院率較低。相對風險小於 1,也支持介入組風險較低。實務上,比例差常更直觀,因為它可以轉成每 100 位病人少幾位再住院。
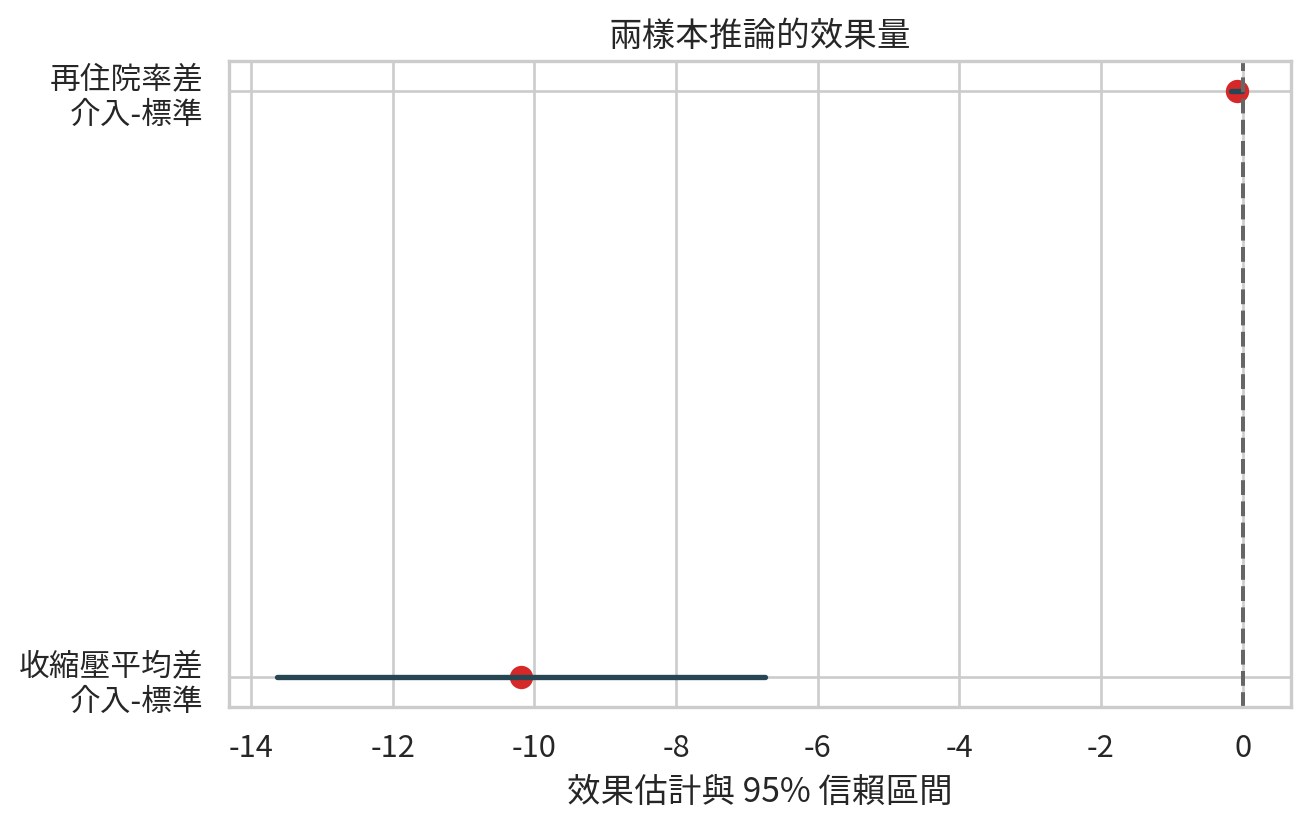
效果量與信賴區間
兩樣本推論的重點不只是 p 值,而是效果大小與不確定性。平均差、比例差、相對風險都可以搭配信賴區間呈現。
effect_df = pd.DataFrame(
{
"outcome": ["收縮壓平均差\n介入-標準", "再住院率差\n介入-標準"],
"estimate": [mean_diff, diff_prop],
"lower": [ci_mean[0], ci_prop[0]],
"upper": [ci_mean[1], ci_prop[1]],
}
)
plt.figure(figsize=(7, 4.5))
for index, row in effect_df.iterrows():
plt.plot([row["lower"], row["upper"]], [index, index], color="#264653", linewidth=2)
plt.scatter(row["estimate"], index, color="#d62828", s=60)
plt.axvline(0, color="#666666", linestyle="--")
plt.yticks(range(len(effect_df)), effect_df["outcome"])
plt.xlabel("效果估計與 95% 信賴區間")
plt.title("兩樣本推論的效果量")
plt.tight_layout()
plt.savefig(FIG_DIR / "ch08_effect_estimates_ci.png", dpi=300)
plt.show()
這張圖的尺度不同,主要用來示範概念:效果量最好搭配信賴區間一起報告。若信賴區間很寬,代表不確定性大;若信賴區間跨過 0,代表資料仍與沒有差異相容。
常見陷阱
- 把配對資料當獨立資料分析:會浪費資訊,甚至錯估標準誤。
- 只報 p 值不報平均差或比例差:讀者不知道差異大小。
- 忽略基準風險:相同相對風險在不同基準風險下,絕對影響不同。
- 未檢查變異數與分布形狀:極端偏態或離群值會影響 t 檢定。
- 把統計顯著當成治療值得採用:仍需考慮副作用、成本、可行性與病人偏好。
本章重點整理
- 兩組比較前先判斷資料是獨立樣本或配對樣本。
- Welch t 檢定適合兩獨立樣本平均值比較,且不要求兩組變異數相等。
- 配對 t 檢定分析的是同一個體的差值。
- 兩比例比較可用比例差、相對風險與 p 值描述。
- 效果大小與信賴區間比單獨 p 值提供更多臨床資訊。
- 統計顯著不等於臨床顯著,兩者應分開討論。
小練習
- 說明獨立樣本與配對樣本的差異,並各舉一個醫學例子。
- 某研究兩組平均 LDL-C 分別為 108 與 121 mg/dL,你會如何定義平均差方向?
- 若兩組再住院率分別為 12% 與 18%,計算比例差與相對風險。
- 說明為何配對 t 檢定通常比未配對分析更有效率。
- 解釋「p 值顯著但比例差只有 1%」在臨床上可能代表什麼。
p_standard = 0.18
p_intervention = 0.12
practice_risk_difference = p_intervention - p_standard
practice_relative_risk = p_intervention / p_standard
pd.DataFrame(
{
"quantity": ["比例差:介入-標準", "相對風險:介入/標準"],
"value": [practice_risk_difference, practice_relative_risk],
}
).round(4)
| 0 |
比例差:介入-標準 |
-0.0600 |
| 1 |
相對風險:介入/標準 |
0.6667 |
Glossary
| 兩樣本推論 |
two-sample inference |
比較兩組母群體參數的推論方法。 |
| 獨立樣本 |
independent samples |
兩組觀察值來自不同個體且彼此獨立。 |
| 配對樣本 |
paired samples |
兩個觀察值具有自然配對關係,例如同一人前後測。 |
| 兩獨立樣本 t 檢定 |
two-sample t-test |
比較兩獨立樣本平均值的 t 檢定。 |
| Welch t 檢定 |
Welch's t-test |
不假設兩組變異數相等的兩樣本 t 檢定。 |
| Pooled t 檢定 |
pooled t-test |
假設兩組變異數相等並合併變異估計的 t 檢定。 |
| 配對 t 檢定 |
paired t-test |
比較配對差值平均是否為 0 的 t 檢定。 |
| 平均差 |
mean difference |
兩組平均值之差。 |
| 比例差 |
risk difference |
兩組事件比例之差,也稱風險差。 |
| 相對風險 |
relative risk |
兩組事件比例的比值。 |
| 效果量 |
effect size |
差異或關聯大小的量化指標。 |
| 信賴區間 |
confidence interval |
量化估計不確定性的區間。 |
| 統計顯著性 |
statistical significance |
結果達到預設顯著水準的狀態。 |
| 臨床顯著性 |
clinical significance |
結果是否具有實際臨床重要性。 |