本章學習目標
前一章我們學會估計參數與建立信賴區間。這一章進入假設檢定 (hypothesis testing):當研究者有一個明確主張時,資料是否提供足夠證據反對「沒有差異」或「沒有效果」的說法?
假設檢定很像臨床診斷,但也不完全一樣。醫師不會只因為單一檢驗稍微異常就宣布診斷;統計也不應只因為 p 值小於 0.05 就停止思考。p 值是證據的一部分,不是研究的結局字幕。
讀完本章後,你應該能夠:
- 說明虛無假設 (null hypothesis) 與對立假設 (alternative hypothesis)。
- 解釋檢定統計量 (test statistic),p 值 (p-value),顯著水準 (significance level) 與拒絕域 (rejection region)。
- 區分單尾檢定 (one-sided test) 與雙尾檢定 (two-sided test)。
- 執行單一樣本 t 檢定 (one-sample t-test)。
- 執行單一比例檢定 (one-sample proportion test)。
- 說明第一型錯誤 (type I error)、第二型錯誤 (type II error)、檢定力 (power) 與臨床顯著性 (clinical significance)。
假設檢定的基本架構
假設檢定從兩個互相競爭的假設開始。虛無假設通常代表「沒有差異」、「沒有改善」、「等於某個基準值」。對立假設代表研究者想找證據支持的方向。
例如某診所導入居家血壓管理計畫後,想知道平均收縮壓是否低於 135 mmHg:
\[
H_0: \mu = 135
\]
\[
H_1: \mu < 135
\]
其中 \(\mu\) 是母群體平均收縮壓。注意,假設是針對母群體參數,不是只針對這次樣本。樣本只是我們手上的證據。
假設檢定的邏輯是:先暫時假設 \(H_0\) 為真,然後問「若 \(H_0\) 真的成立,觀察到目前這麼極端或更極端資料的機率有多大?」這個機率就是 p 值。
p 值是什麼?
p 值是在虛無假設為真時,觀察到目前資料或更極端資料的機率。p 值越小,表示目前資料在 \(H_0\) 下越不尋常,因此我們越有理由懷疑 \(H_0\)。
常見錯誤解讀包括:
- p 值不是 \(H_0\) 為真的機率。
- p 值不是結果由偶然造成的機率。
- p 值不是效果大小。
- p 值小不代表臨床上重要。
- p 值大不代表完全沒有差異。
如果 p 值是一位住院醫師,它會說:「如果沒有差異,這份資料看起來有多奇怪。」它不會說:「真相就是這樣。」真相需要效果量、信賴區間、研究設計與臨床脈絡一起判讀。
單尾與雙尾檢定
單尾檢定 (one-sided test) 用於研究問題有明確方向時,例如「是否低於 135」或「是否高於 15%」。雙尾檢定 (two-sided test) 用於關心是否不等於某值,方向不限,例如「平均收縮壓是否不同於 135」。
雙尾檢定通常較保守,也較常用,因為研究結果可能往意料外方向出現。若在看完資料後才決定用單尾檢定,這就像看到考題才改讀書計畫,不太公平。方向性假設應在分析前設定。
範例 1:單一樣本 t 檢定
某診所追蹤 15 位參加居家血壓管理計畫的病人,收集計畫後收縮壓。研究問題是:平均收縮壓是否低於 135 mmHg?
sbp_after = np.array([132, 128, 136, 125, 130, 134, 129, 127, 131, 126, 133, 124, 135, 129, 128])
mu0 = 135
bp_test_summary = pd.DataFrame(
{
"statistic": ["樣本數", "樣本平均值", "樣本標準差", "虛無假設平均值"],
"value": [len(sbp_after), sbp_after.mean(), sbp_after.std(ddof=1), mu0],
}
)
bp_test_summary.round(2)
| 0 |
樣本數 |
15.00 |
| 1 |
樣本平均值 |
129.80 |
| 2 |
樣本標準差 |
3.65 |
| 3 |
虛無假設平均值 |
135.00 |
單一樣本 t 檢定適用於母群體標準差未知,且我們要比較單一樣本平均值與某個基準值。檢定統計量為:
\[
t = \frac{\bar{x} - \mu_0}{s/\sqrt{n}}
\]
其中 \(\bar{x}\) 是樣本平均值,\(\mu_0\) 是虛無假設下的平均值,\(s\) 是樣本標準差,\(n\) 是樣本數。
t_result = ttest_1samp(sbp_after, popmean=mu0, alternative="less")
se = sbp_after.std(ddof=1) / np.sqrt(len(sbp_after))
t_manual = (sbp_after.mean() - mu0) / se
pd.DataFrame(
{
"quantity": ["t 統計量", "p 值", "手算 t 統計量"],
"value": [t_result.statistic, t_result.pvalue, t_manual],
}
).round(4)
| 0 |
t 統計量 |
-5.5194 |
| 1 |
p 值 |
0.0000 |
| 2 |
手算 t 統計量 |
-5.5194 |
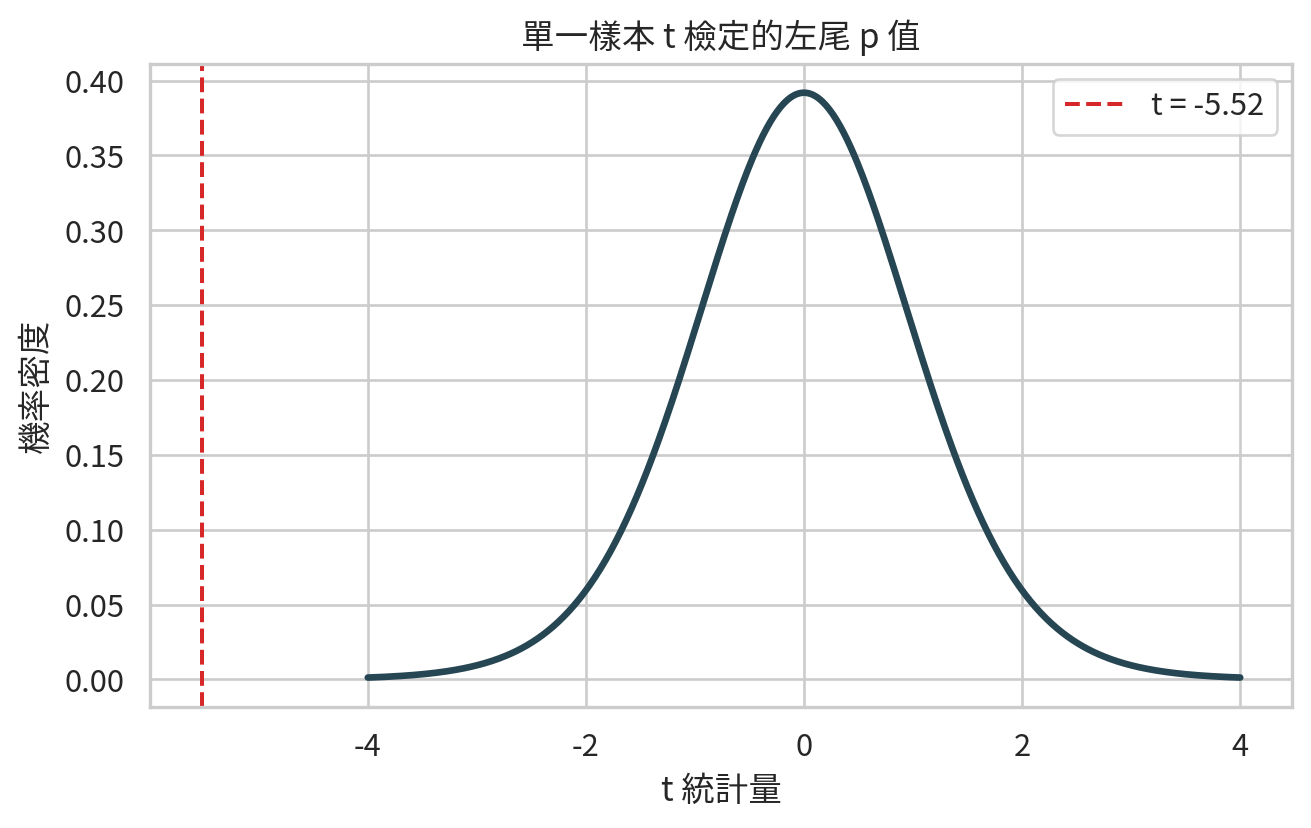
若顯著水準 \(\alpha = 0.05\),且 p 值小於 0.05,我們拒絕虛無假設,認為資料提供證據支持平均收縮壓低於 135 mmHg。若 p 值不小於 0.05,我們不拒絕虛無假設,但這不等於證明平均值就是 135。
x_grid = np.linspace(-4, 4, 500)
df = len(sbp_after) - 1
t_df = pd.DataFrame({"t_value": x_grid, "density": t.pdf(x_grid, df=df)})
plt.figure(figsize=(7, 4.5))
sns.lineplot(data=t_df, x="t_value", y="density", color="#264653", linewidth=2.5)
plt.fill_between(x_grid, 0, t_df["density"], where=x_grid <= t_result.statistic, color="#e76f51", alpha=0.35)
plt.axvline(t_result.statistic, color="#d62828", linestyle="--", label=f"t = {t_result.statistic:.2f}")
plt.xlabel("t 統計量")
plt.ylabel("機率密度")
plt.title("單一樣本 t 檢定的左尾 p 值")
plt.legend()
plt.tight_layout()
plt.savefig(FIG_DIR / "ch07_one_sample_t_pvalue.png", dpi=300)
plt.show()
假設檢定與信賴區間的關係
雙尾假設檢定與信賴區間有密切關係。若 95% 信賴區間不包含虛無假設值,雙尾檢定在 \(\alpha = 0.05\) 下通常會拒絕 \(H_0\)。若信賴區間包含虛無假設值,通常不拒絕。
但信賴區間更有資訊,因為它顯示效果大小與不確定範圍。p 值只告訴你資料和 \(H_0\) 相容程度,信賴區間還告訴你差異可能有多大。臨床研究中,請優先看效果量與信賴區間,再看 p 值。p 值可以坐副駕,但別讓它單獨開車。
alpha = 0.05
critical_t = t.ppf(1 - alpha / 2, df=df)
ci_lower = sbp_after.mean() - critical_t * se
ci_upper = sbp_after.mean() + critical_t * se
pd.DataFrame(
{
"quantity": ["平均值差異", "95% CI 下限", "95% CI 上限"],
"value": [sbp_after.mean() - mu0, ci_lower - mu0, ci_upper - mu0],
}
).round(3)
| 0 |
平均值差異 |
-5.200 |
| 1 |
95% CI 下限 |
-7.221 |
| 2 |
95% CI 上限 |
-3.179 |
第一型錯誤、第二型錯誤與檢定力
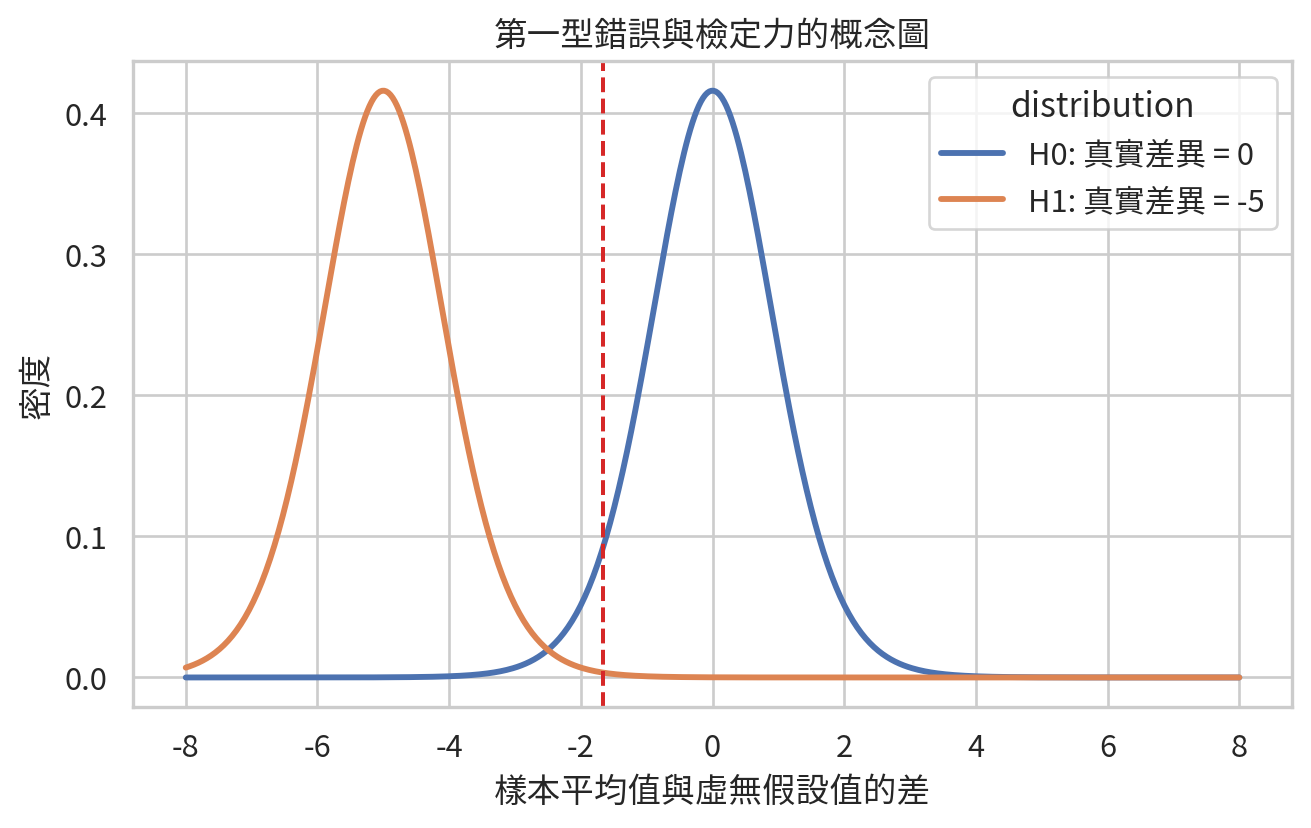
第一型錯誤是虛無假設其實為真,卻錯誤拒絕它。第一型錯誤機率通常記為 \(\alpha\),也就是顯著水準。第二型錯誤是對立假設其實為真,卻沒有拒絕虛無假設,通常記為 \(\beta\)。檢定力是正確拒絕錯誤虛無假設的機率:
\[
\text{Power} = 1 - \beta
\]
醫學研究常希望檢定力至少 80% 或 90%。檢定力受樣本數、效果大小、變異程度與顯著水準影響。效果越大、樣本數越多、變異越小,通常越容易偵測到差異。
effect_grid = np.linspace(-8, 8, 500)
se_effect = sbp_after.std(ddof=1) / np.sqrt(len(sbp_after))
critical_left = t.ppf(0.05, df=df)
null_density = t.pdf(effect_grid / se_effect, df=df) / se_effect
alt_mean = -5
alt_density = t.pdf((effect_grid - alt_mean) / se_effect, df=df) / se_effect
error_df = pd.DataFrame(
{
"effect": np.r_[effect_grid, effect_grid],
"density": np.r_[null_density, alt_density],
"distribution": ["H0: 真實差異 = 0"] * len(effect_grid) + ["H1: 真實差異 = -5"] * len(effect_grid),
}
)
plt.figure(figsize=(7, 4.5))
sns.lineplot(data=error_df, x="effect", y="density", hue="distribution", linewidth=2.2)
plt.axvline(critical_left * se_effect, color="#d62828", linestyle="--", label="拒絕域界線")
plt.xlabel("樣本平均值與虛無假設值的差")
plt.ylabel("密度")
plt.title("第一型錯誤與檢定力的概念圖")
plt.tight_layout()
plt.savefig(FIG_DIR / "ch07_type_error_power_concept.png", dpi=300)
plt.show()
單一比例檢定
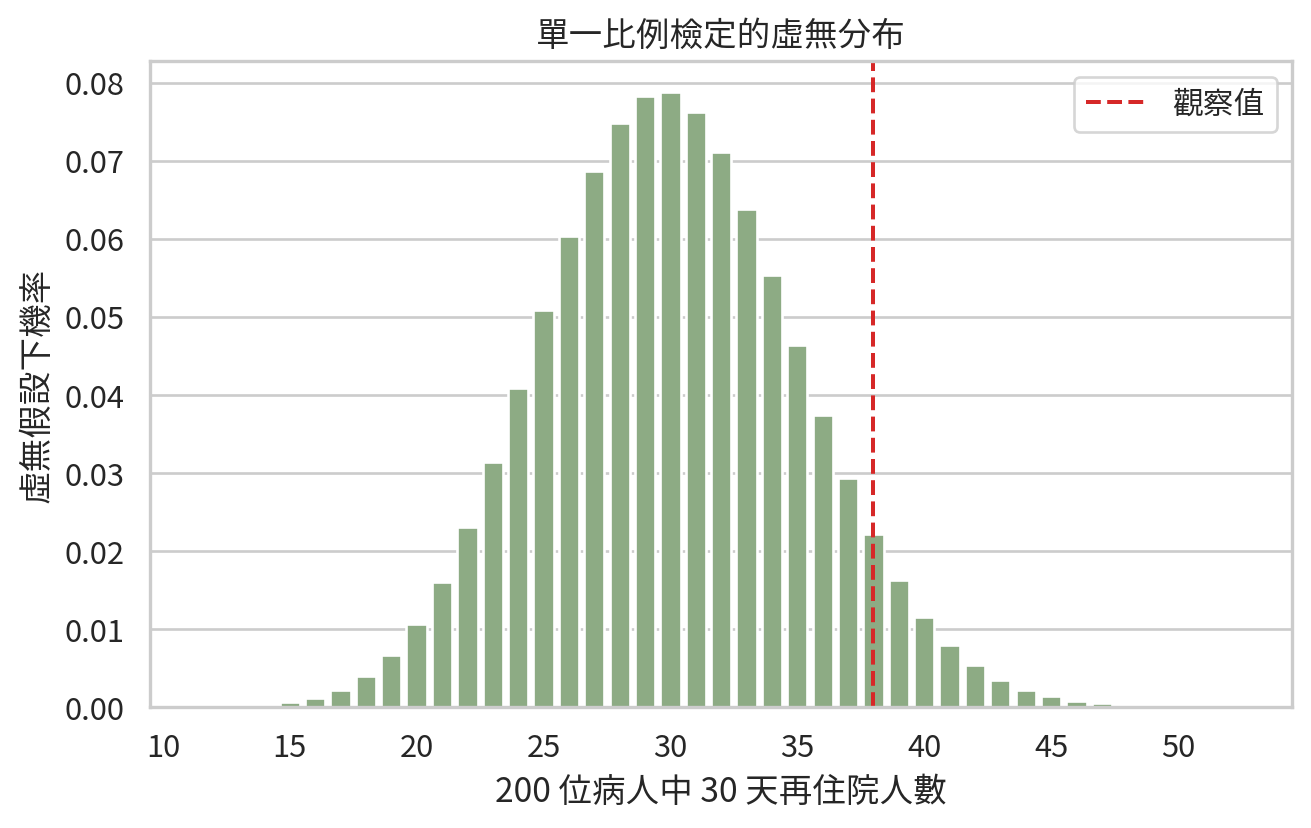
單一比例檢定用於比較樣本比例與某個基準比例。例如某醫院想知道 30 天再住院率是否高於全國基準 15%。若追蹤 200 位病人,其中 38 位再住院,樣本比例為 19%。
虛無假設與對立假設可寫成:
\[
H_0: p = 0.15
\]
\[
H_1: p > 0.15
\]
n_patients = 200
x_readmit = 38
p0 = 0.15
p_hat = x_readmit / n_patients
pd.DataFrame(
{
"quantity": ["樣本數", "再住院人數", "樣本再住院率", "基準再住院率"],
"value": [n_patients, x_readmit, p_hat, p0],
}
).round(3)
| 0 |
樣本數 |
200.00 |
| 1 |
再住院人數 |
38.00 |
| 2 |
樣本再住院率 |
0.19 |
| 3 |
基準再住院率 |
0.15 |
精確二項檢定 (exact binomial test) 直接使用二項分布計算在 \(H_0\) 下觀察到目前或更極端結果的機率。
binom_result = binomtest(x_readmit, n_patients, p=p0, alternative="greater")
pd.DataFrame(
{
"quantity": ["p 值", "樣本比例"],
"value": [binom_result.pvalue, p_hat],
}
).round(4)
k_values = np.arange(10, 55)
binom_df = pd.DataFrame({"readmissions": k_values, "probability": binom.pmf(k_values, n=n_patients, p=p0)})
plt.figure(figsize=(7, 4.5))
sns.barplot(data=binom_df, x="readmissions", y="probability", color="#8ab17d")
plt.axvline(x_readmit - k_values.min(), color="#d62828", linestyle="--", label="觀察值")
tick_positions = np.arange(0, len(k_values), 5)
plt.xticks(tick_positions, k_values[tick_positions])
plt.xlabel("200 位病人中 30 天再住院人數")
plt.ylabel("虛無假設下機率")
plt.title("單一比例檢定的虛無分布")
plt.legend()
plt.tight_layout()
plt.savefig(FIG_DIR / "ch07_one_proportion_null_distribution.png", dpi=300)
plt.show()
如果 p 值小於 0.05,我們會說資料提供證據支持再住院率高於 15%。但接著仍要問:高多少?信賴區間多寬?這個差異是否足以啟動品質改善方案?統計顯著只是會議的開始,不是會議紀錄的最後一行。
常態近似比例檢定
當樣本數夠大時,樣本比例可用常態分布近似。檢定統計量為:
\[
z = \frac{\hat{p} - p_0}{\sqrt{p_0(1-p_0)/n}}
\]
其中標準誤是在虛無假設下計算。這點和信賴區間常用 \(\hat{p}\) 估計標準誤略有不同。
se_null = np.sqrt(p0 * (1 - p0) / n_patients)
z_stat = (p_hat - p0) / se_null
p_value_z = 1 - norm.cdf(z_stat)
pd.DataFrame(
{
"quantity": ["z 統計量", "單尾 p 值"],
"value": [z_stat, p_value_z],
}
).round(4)
| 0 |
z 統計量 |
1.5842 |
| 1 |
單尾 p 值 |
0.0566 |
常態近似很方便,但若樣本數小、事件很少、比例接近 0 或 1,精確二項檢定或其他方法更穩妥。醫學資料常有稀有事件,這時不要硬把大樣本近似拖上場。
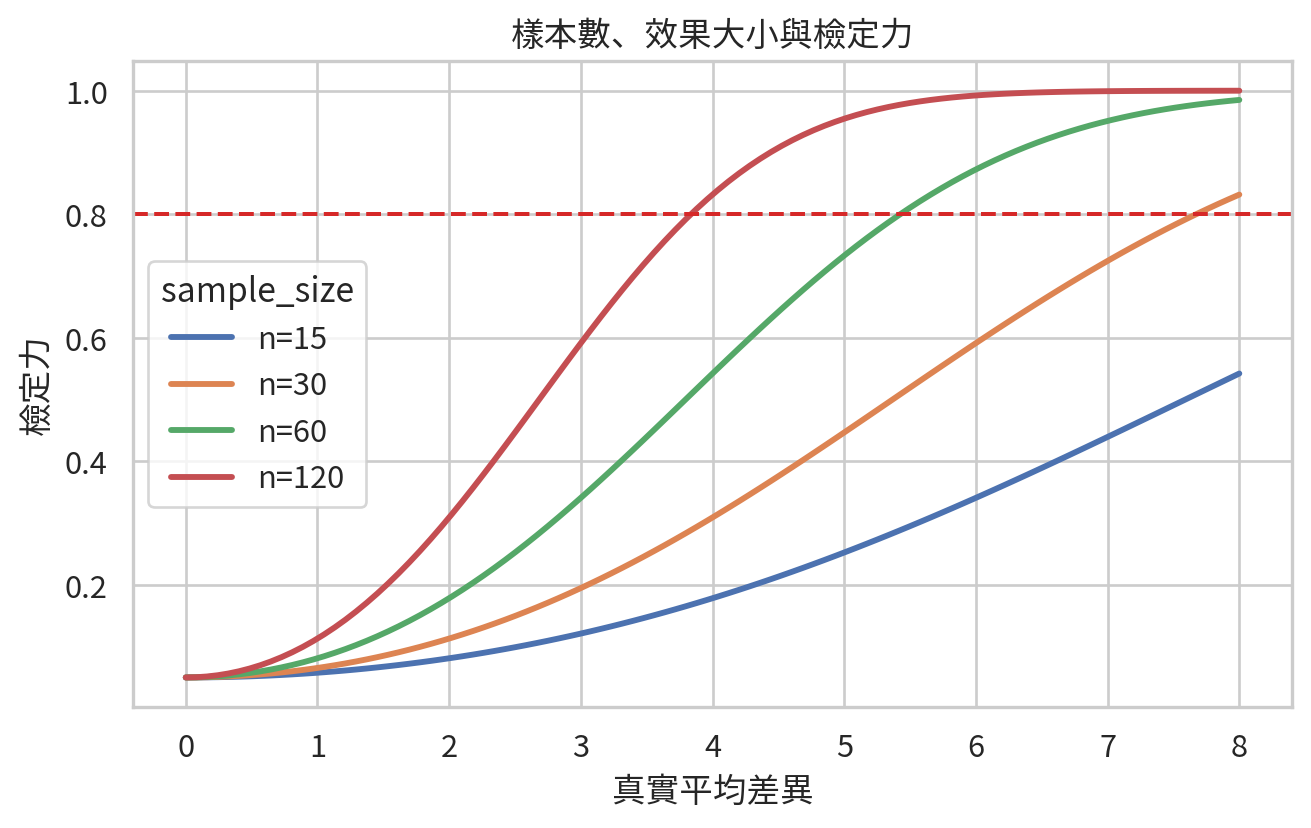
檢定力與樣本數
在研究設計階段,我們常問:「需要多少樣本才有足夠機會偵測到臨床上重要的差異?」這就是檢定力與樣本數規劃的問題。
下面用一個簡化的雙尾 z 檢定近似,假設標準差為 15 mmHg,顯著水準 0.05,觀察不同樣本數下,真實平均差異越大時檢定力如何改變。
effect_sizes = np.linspace(0, 8, 100)
sample_sizes = [15, 30, 60, 120]
rows = []
for n_current in sample_sizes:
se_known = 15 / np.sqrt(n_current)
critical = norm.ppf(0.975)
for effect in effect_sizes:
power = norm.cdf(-critical - effect / se_known) + (1 - norm.cdf(critical - effect / se_known))
rows.append({"effect": effect, "power": power, "sample_size": f"n={n_current}"})
power_df = pd.DataFrame(rows)
power_df.head()
| 0 |
0.000000 |
0.050000 |
n=15 |
| 1 |
0.080808 |
0.050050 |
n=15 |
| 2 |
0.161616 |
0.050199 |
n=15 |
| 3 |
0.242424 |
0.050449 |
n=15 |
| 4 |
0.323232 |
0.050798 |
n=15 |
plt.figure(figsize=(7, 4.5))
sns.lineplot(data=power_df, x="effect", y="power", hue="sample_size", linewidth=2.2)
plt.axhline(0.80, color="#d62828", linestyle="--", label="power = 0.80")
plt.xlabel("真實平均差異")
plt.ylabel("檢定力")
plt.title("樣本數、效果大小與檢定力")
plt.tight_layout()
plt.savefig(FIG_DIR / "ch07_power_by_sample_size.png", dpi=300)
plt.show()
圖中可見樣本數越大,檢定力越高。可是大樣本也可能讓非常小、臨床上不重要的差異變成統計顯著。因此設計研究時,應先定義最小臨床重要差異 (minimal clinically important difference, MCID),而不是只追求 p 值小於 0.05。
統計顯著與臨床顯著
統計顯著 (statistical significance) 表示資料在某個統計模型與顯著水準下,提供足夠證據反對虛無假設。臨床顯著則問:這個差異對病人照護、預後、成本或政策是否有實際意義?
例如某降血壓藥在 5000 人試驗中讓平均收縮壓下降 1 mmHg,p 值可能很小,但臨床意義有限。相反地,小型試驗中下降 8 mmHg 但 p 值 0.08,可能仍值得進一步研究。請不要讓 p 值變成研究判讀的獨裁者。
常見陷阱
- 把 p 值解釋成虛無假設為真的機率:這是最常見誤解之一。
- p 值小就等於效果重要:統計顯著不等於臨床顯著。
- p 值大就等於沒有差異:可能是樣本數不足或變異太大。
- 看完資料才決定單尾檢定:方向性假設應在分析前設定。
- 忽略多重檢定:做很多檢定時,偶然顯著的機會會上升。
- 只報 p 值不報效果量與信賴區間:讀者需要知道差多少,而不只是有沒有過門檻。
本章重點整理
- 假設檢定是在虛無假設下評估資料是否足夠極端。
- p 值是在虛無假設為真時,觀察到目前或更極端資料的機率。
- 單一樣本 t 檢定用於比較樣本平均值與某個基準平均值。
- 單一比例檢定用於比較樣本比例與某個基準比例。
- 第一型錯誤是錯誤拒絕真的虛無假設;第二型錯誤是未拒絕假的虛無假設。
- 檢定力是正確偵測到真實差異的機率。
- 假設檢定應與效果量、信賴區間與臨床意義一起解讀。
小練習
- 某樣本 18 位病人治療後 LDL-C 平均 112 mg/dL,標準差 24 mg/dL。檢定平均值是否低於 125 mg/dL。
- 某院 150 位出院病人中 30 位再住院。檢定再住院率是否高於 15%。
- 用自己的話解釋 p 值 0.03 的正確意思。
- 說明為什麼 p 值 0.20 不代表兩組完全沒有差異。
- 說明統計顯著但臨床不顯著的可能例子。
ldl_n = 18
ldl_mean = 112
ldl_sd = 24
ldl_mu0 = 125
ldl_se = ldl_sd / np.sqrt(ldl_n)
ldl_t = (ldl_mean - ldl_mu0) / ldl_se
ldl_p = t.cdf(ldl_t, df=ldl_n - 1)
readmit_practice = 30
n_practice = 150
p0_practice = 0.15
practice_binom = binomtest(readmit_practice, n_practice, p=p0_practice, alternative="greater")
pd.DataFrame(
{
"問題": ["LDL-C 單尾 t 統計量", "LDL-C 單尾 p 值", "再住院率精確二項 p 值"],
"數值": [ldl_t, ldl_p, practice_binom.pvalue],
}
).round(4)
| 0 |
LDL-C 單尾 t 統計量 |
-2.2981 |
| 1 |
LDL-C 單尾 p 值 |
0.0173 |
| 2 |
再住院率精確二項 p 值 |
0.0587 |
Glossary
| 假設檢定 |
hypothesis testing |
在虛無假設下評估資料是否足夠極端的推論方法。 |
| 虛無假設 |
null hypothesis |
通常代表沒有差異、沒有效果或等於基準值的假設。 |
| 對立假設 |
alternative hypothesis |
與虛無假設相對,研究者希望找到證據支持的假設。 |
| 檢定統計量 |
test statistic |
將樣本資料轉換為可與理論分布比較的統計量。 |
| p 值 |
p-value |
在虛無假設為真時,觀察到目前或更極端資料的機率。 |
| 顯著水準 |
significance level |
可接受的第一型錯誤機率,常記為 alpha。 |
| 拒絕域 |
rejection region |
檢定統計量落入後會拒絕虛無假設的區域。 |
| 單尾檢定 |
one-sided test |
對立假設具有明確方向的假設檢定。 |
| 雙尾檢定 |
two-sided test |
對立假設是不等於某值、方向不限的假設檢定。 |
| 單一樣本 t 檢定 |
one-sample t-test |
比較單一樣本平均值與基準平均值的 t 檢定。 |
| 單一比例檢定 |
one-sample proportion test |
比較單一樣本比例與基準比例的檢定。 |
| 精確二項檢定 |
exact binomial test |
直接使用二項分布進行比例檢定的方法。 |
| 第一型錯誤 |
type I error |
虛無假設為真時錯誤拒絕虛無假設。 |
| 第二型錯誤 |
type II error |
對立假設為真時未拒絕虛無假設。 |
| 檢定力 |
power |
對立假設為真時正確拒絕虛無假設的機率。 |
| 效果大小 |
effect size |
差異或關聯的實際大小。 |
| 統計顯著性 |
statistical significance |
檢定結果達到預先設定顯著水準的狀態。 |
| 臨床顯著性 |
clinical significance |
結果對病人照護或公共衛生是否具有實質意義。 |
| 最小臨床重要差異 |
minimal clinically important difference, MCID |
臨床上被認為有意義的最小效果大小。 |
| 多重檢定 |
multiple testing |
同一研究中進行多個假設檢定的情況。 |