本章學習目標
前幾章我們學到 t 檢定、信賴區間與常態近似。這些方法很好用,但醫療資料常常不太乖:住院天數右偏、疼痛分數是等級、樣本數很小、離群值很有存在感。這時候,非參數方法 (nonparametric methods) 提供另一條路。
非參數方法不是「不用假設」的方法,而是較少依賴特定母群體分布形狀的方法。許多非參數檢定使用排序 (rank) 而非原始數值,因此對極端值較穩健。它們像臨床老師看到病人資料很亂時,溫柔但堅定地說:「我們先排隊。」
讀完本章後,你應該能夠:
- 說明非參數方法適用的常見情境。
- 使用符號檢定 (sign test) 與 Wilcoxon 符號等級檢定 (Wilcoxon signed-rank test) 分析單一樣本或配對資料。
- 使用 Mann-Whitney U 檢定 (Mann-Whitney U test) 比較兩個獨立樣本。
- 使用 Kruskal-Wallis 檢定 (Kruskal-Wallis test) 比較三組以上獨立樣本。
- 使用 Spearman 等級相關 (Spearman rank correlation) 描述單調關係。
- 理解置換檢定 (permutation test) 的基本直覺。
什麼時候考慮非參數方法?
非參數方法常用於下列情境:
- 樣本數小,難以評估常態假設。
- 連續資料明顯偏態,例如住院天數、醫療費用、CRP。
- 有離群值,且離群值不一定是錯誤。
- 結果變項是次序資料 (ordinal data),例如疼痛分數、疾病嚴重度等級。
- 研究問題更關心中位數或分布位置,而不是平均值。
不過,非參數方法也不是萬能。它們通常檢定分布位置或排序差異,不一定直接檢定平均值差異。報告結果時,最好搭配中位數、四分位距與合適的效果量,避免只丟出一個 p 值讓讀者自己找路。
排序的基本概念
許多非參數方法會把原始資料轉成排序。假設資料為 3、8、10,排序分別是 1、2、3。若有相同值,通常使用平均排序。例如 3、8、8、10 中,兩個 8 佔第 2 與第 3 名,因此各給 2.5。
排序的優點是降低極端值影響。若某病人住院 60 天,平均值會被明顯拉高;但在排序資料中,它只是最大值。這不代表離群值不重要,而是非參數方法不讓它一個人把整張桌子掀翻。
Mann-Whitney U 檢定:兩獨立樣本
Mann-Whitney U 檢定用於比較兩個獨立樣本的分布位置,常被視為兩獨立樣本 t 檢定的非參數替代方法。它也稱 Wilcoxon rank-sum test。
重要提醒:Mann-Whitney U 檢定不只是「中位數檢定」。若兩組分布形狀相似,它可被解讀為位置差異;若分布形狀不同,解釋要更小心。
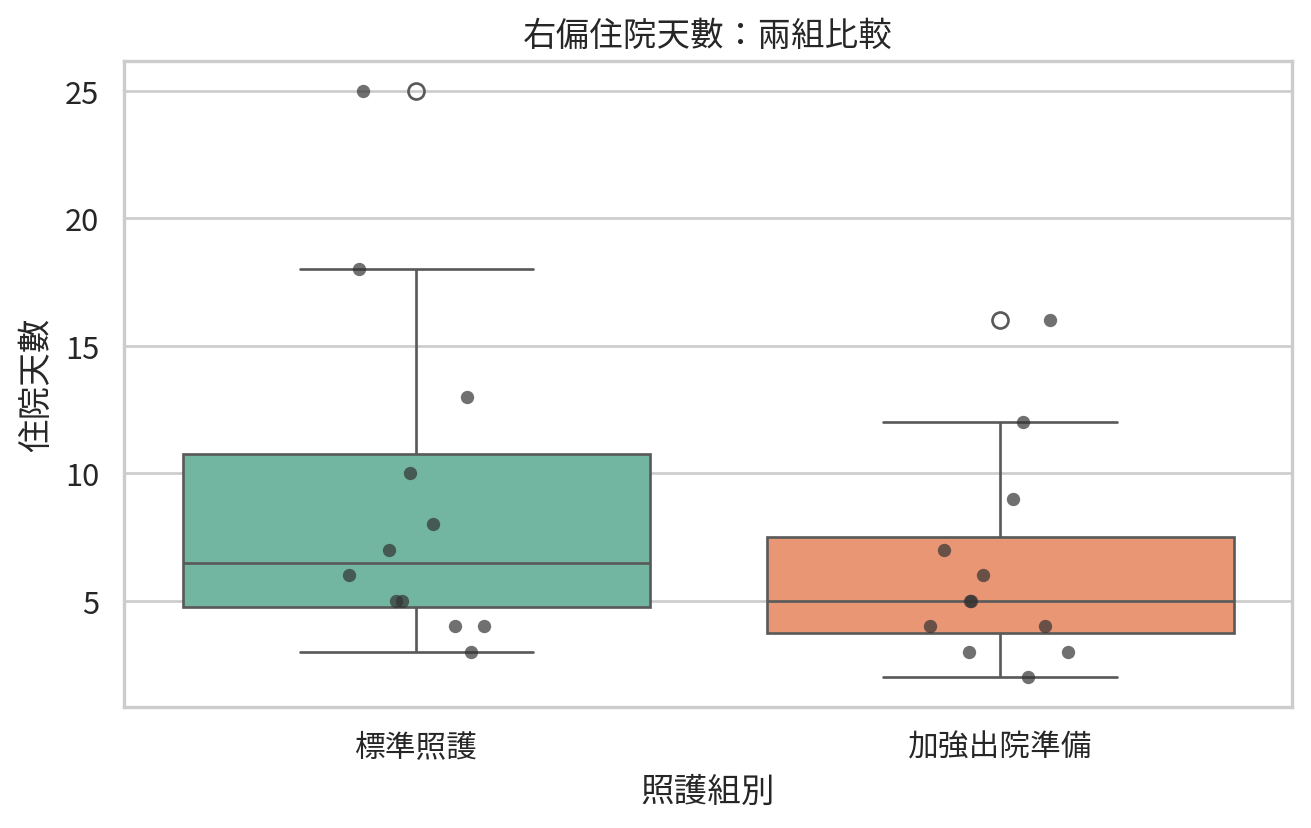
範例 1:加強出院準備是否縮短住院天數?
假設研究比較標準照護與加強出院準備兩組病人的住院天數。住院天數右偏且樣本不大,因此考慮 Mann-Whitney U 檢定。
standard_los = np.array([3, 4, 4, 5, 5, 6, 7, 8, 10, 13, 18, 25])
enhanced_los = np.array([2, 3, 3, 4, 4, 5, 5, 6, 7, 9, 12, 16])
los_df = pd.DataFrame(
{
"los": np.r_[standard_los, enhanced_los],
"group": ["標準照護"] * len(standard_los) + ["加強出院準備"] * len(enhanced_los),
}
)
los_df.groupby("group")["los"].agg(["count", "median", "mean", "std"]).round(2)
| group |
|
|
|
|
| 加強出院準備 |
12 |
5.0 |
6.33 |
4.14 |
| 標準照護 |
12 |
6.5 |
9.00 |
6.65 |
plt.figure(figsize=(7, 4.5))
sns.boxplot(data=los_df, x="group", y="los", hue="group", palette="Set2", legend=False)
sns.stripplot(data=los_df, x="group", y="los", color="#333333", alpha=0.7, jitter=0.12)
plt.xlabel("照護組別")
plt.ylabel("住院天數")
plt.title("右偏住院天數:兩組比較")
plt.tight_layout()
plt.savefig(FIG_DIR / "ch09_mannwhitney_los_boxplot.png", dpi=300)
plt.show()
mw_result = mannwhitneyu(enhanced_los, standard_los, alternative="less")
pd.DataFrame(
{
"quantity": ["U 統計量", "單尾 p 值"],
"value": [mw_result.statistic, mw_result.pvalue],
}
).round(4)
| 0 |
U 統計量 |
52.0000 |
| 1 |
單尾 p 值 |
0.1288 |
這裡使用單尾對立假設,因為研究問題是「加強出院準備是否縮短住院天數」。若研究前沒有明確方向,應使用雙尾檢定。
符號檢定與 Wilcoxon 符號等級檢定
配對資料若差值明顯不符合常態,或結果是次序尺度,可以考慮符號檢定或 Wilcoxon 符號等級檢定。
符號檢定只看差值方向:改善、惡化或無變化。它非常穩健,但也丟掉很多資訊。Wilcoxon 符號等級檢定同時考慮差值方向與大小排序,因此通常比符號檢定更有檢定力,但它假設差值分布大致對稱。
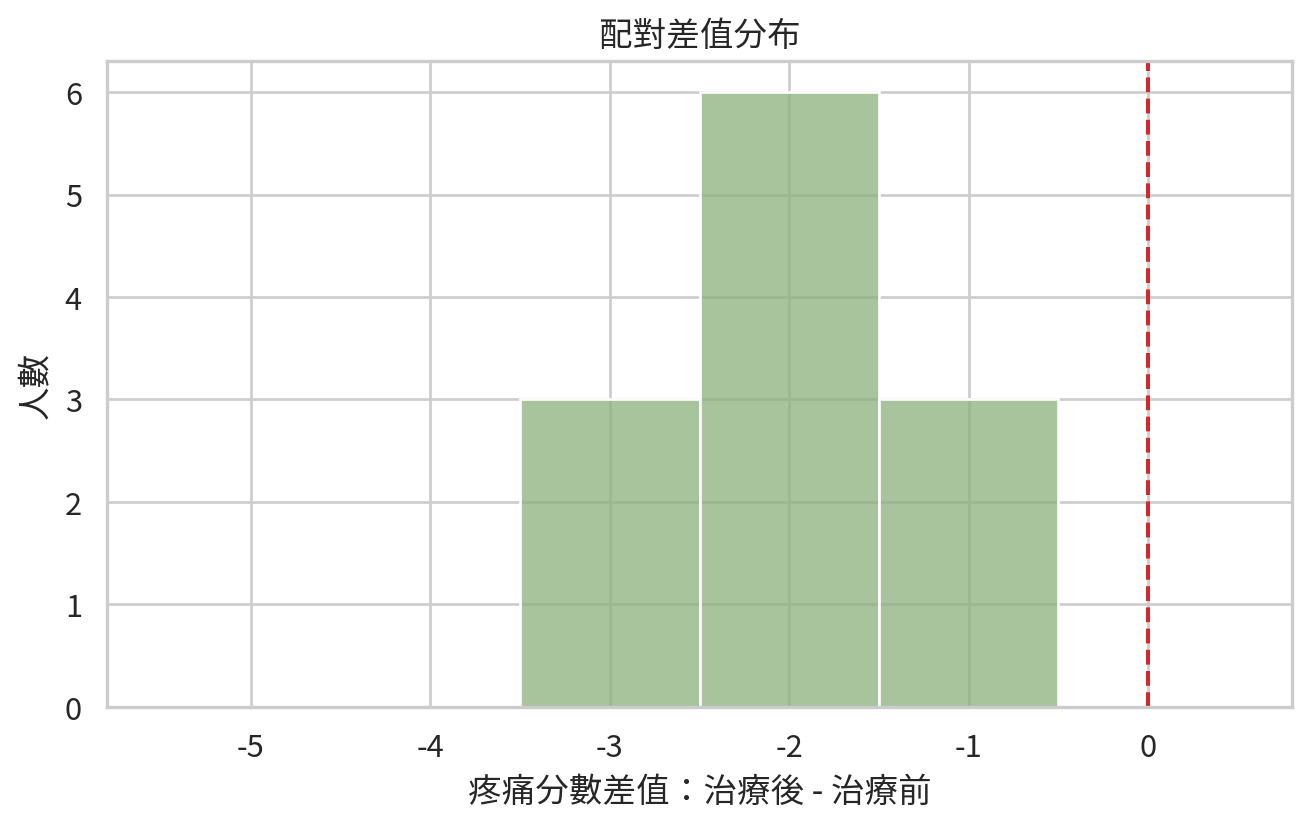
範例 2:治療前後疼痛分數
某疼痛門診記錄 12 位病人治療前後的疼痛分數,分數為 0 到 10 的次序量尺。研究問題是治療後疼痛是否下降。
pain_before = np.array([8, 7, 6, 8, 9, 7, 6, 8, 7, 9, 6, 8])
pain_after = np.array([5, 6, 4, 6, 6, 5, 5, 7, 4, 7, 4, 6])
paired_df = pd.DataFrame({"id": np.arange(1, 13), "before": pain_before, "after": pain_after})
paired_df["difference"] = paired_df["after"] - paired_df["before"]
paired_df
| 0 |
1 |
8 |
5 |
-3 |
| 1 |
2 |
7 |
6 |
-1 |
| 2 |
3 |
6 |
4 |
-2 |
| 3 |
4 |
8 |
6 |
-2 |
| 4 |
5 |
9 |
6 |
-3 |
| 5 |
6 |
7 |
5 |
-2 |
| 6 |
7 |
6 |
5 |
-1 |
| 7 |
8 |
8 |
7 |
-1 |
| 8 |
9 |
7 |
4 |
-3 |
| 9 |
10 |
9 |
7 |
-2 |
| 10 |
11 |
6 |
4 |
-2 |
| 11 |
12 |
8 |
6 |
-2 |
plt.figure(figsize=(7, 4.5))
sns.histplot(data=paired_df, x="difference", bins=np.arange(-5.5, 1.5, 1), color="#8ab17d")
plt.axvline(0, color="#d62828", linestyle="--")
plt.xlabel("疼痛分數差值:治療後 - 治療前")
plt.ylabel("人數")
plt.title("配對差值分布")
plt.tight_layout()
plt.savefig(FIG_DIR / "ch09_wilcoxon_paired_differences.png", dpi=300)
plt.show()
wilcoxon_result = wilcoxon(pain_after, pain_before, alternative="less")
pd.DataFrame(
{
"quantity": ["Wilcoxon 統計量", "單尾 p 值", "差值中位數"],
"value": [wilcoxon_result.statistic, wilcoxon_result.pvalue, np.median(paired_df["difference"])],
}
).round(4)
| 0 |
Wilcoxon 統計量 |
0.0000 |
| 1 |
單尾 p 值 |
0.0002 |
| 2 |
差值中位數 |
-2.0000 |
如果 p 值小,代表資料提供證據支持治療後疼痛分數下降。臨床上仍應報告下降幅度,例如差值中位數與四分位距。病人關心的不是 p 值多小,而是疼痛少了多少。
Kruskal-Wallis 檢定:三組以上比較
Kruskal-Wallis 檢定是 Mann-Whitney U 檢定的多組延伸,用於比較三組以上獨立樣本的分布位置。它常被視為單因子 ANOVA 的非參數替代方法。
虛無假設是各組來自相同分布。若檢定顯著,代表至少一組不同,但不會告訴你哪兩組不同。後續需要事後比較,並注意多重比較問題。
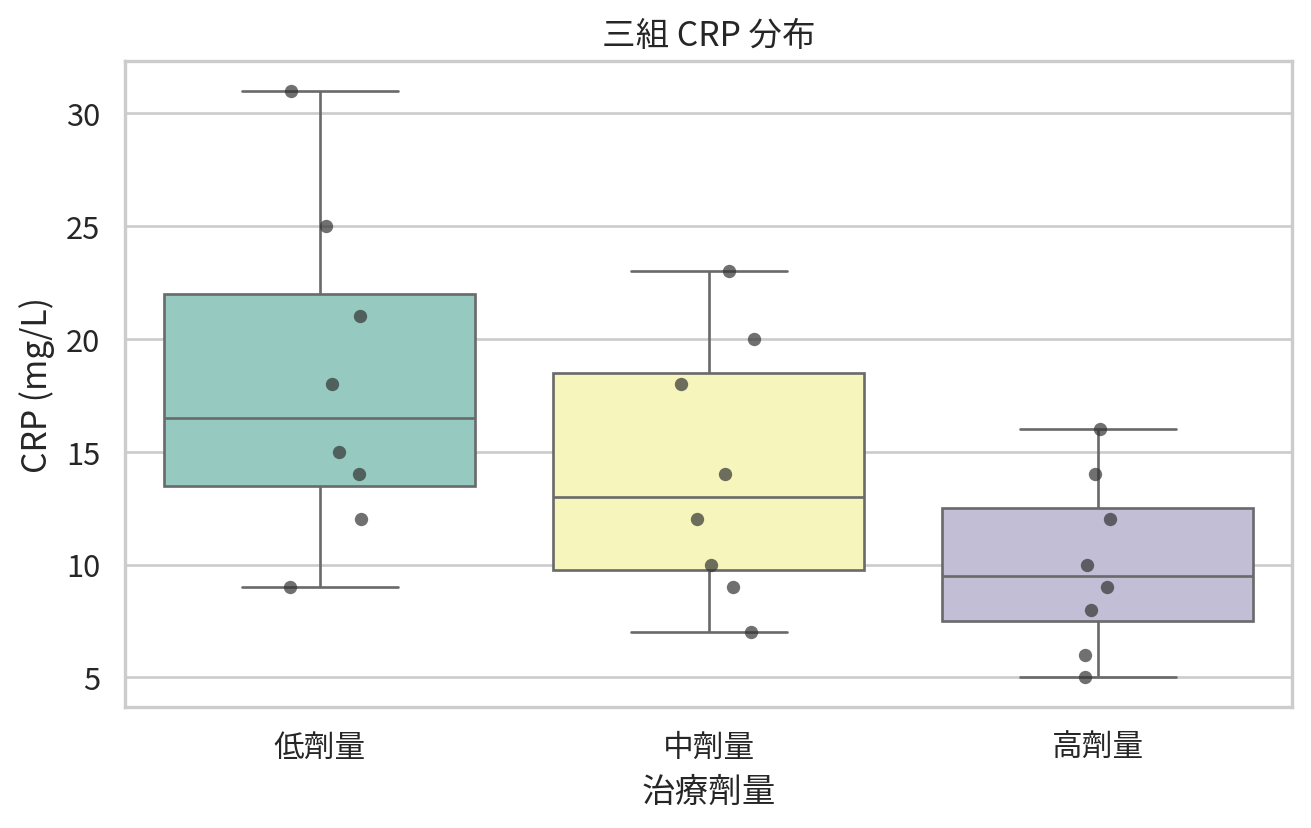
範例 3:三種劑量下的 CRP
dose_a = np.array([9, 12, 14, 15, 18, 21, 25, 31])
dose_b = np.array([7, 9, 10, 12, 14, 18, 20, 23])
dose_c = np.array([5, 6, 8, 9, 10, 12, 14, 16])
crp_df = pd.DataFrame(
{
"crp": np.r_[dose_a, dose_b, dose_c],
"dose": ["低劑量"] * len(dose_a) + ["中劑量"] * len(dose_b) + ["高劑量"] * len(dose_c),
}
)
crp_df.groupby("dose")["crp"].agg(["count", "median", "mean"]).round(2)
| dose |
|
|
|
| 中劑量 |
8 |
13.0 |
14.12 |
| 低劑量 |
8 |
16.5 |
18.12 |
| 高劑量 |
8 |
9.5 |
10.00 |
plt.figure(figsize=(7, 4.5))
sns.boxplot(data=crp_df, x="dose", y="crp", hue="dose", palette="Set3", legend=False)
sns.stripplot(data=crp_df, x="dose", y="crp", color="#333333", alpha=0.7, jitter=0.12)
plt.xlabel("治療劑量")
plt.ylabel("CRP (mg/L)")
plt.title("三組 CRP 分布")
plt.tight_layout()
plt.savefig(FIG_DIR / "ch09_kruskal_crp_groups.png", dpi=300)
plt.show()
kruskal_result = kruskal(dose_a, dose_b, dose_c)
pd.DataFrame(
{
"quantity": ["H 統計量", "p 值"],
"value": [kruskal_result.statistic, kruskal_result.pvalue],
}
).round(4)
| 0 |
H 統計量 |
6.1965 |
| 1 |
p 值 |
0.0451 |
若結果顯著,下一步應該做組間事後比較,並控制多重比較造成的第一型錯誤增加。本章先保留這個伏筆,因為多組推論會在後面章節更完整處理。
Spearman 等級相關
Pearson 相關衡量線性關係,而 Spearman 等級相關衡量單調關係 (monotonic relationship)。如果一個變項增加時另一個變項大致增加或大致減少,即使不是直線,Spearman 相關仍可能捕捉到。
Spearman 相關會先把資料轉成排序,再計算排序間的相關。因此它對離群值較不敏感,也適合次序資料。
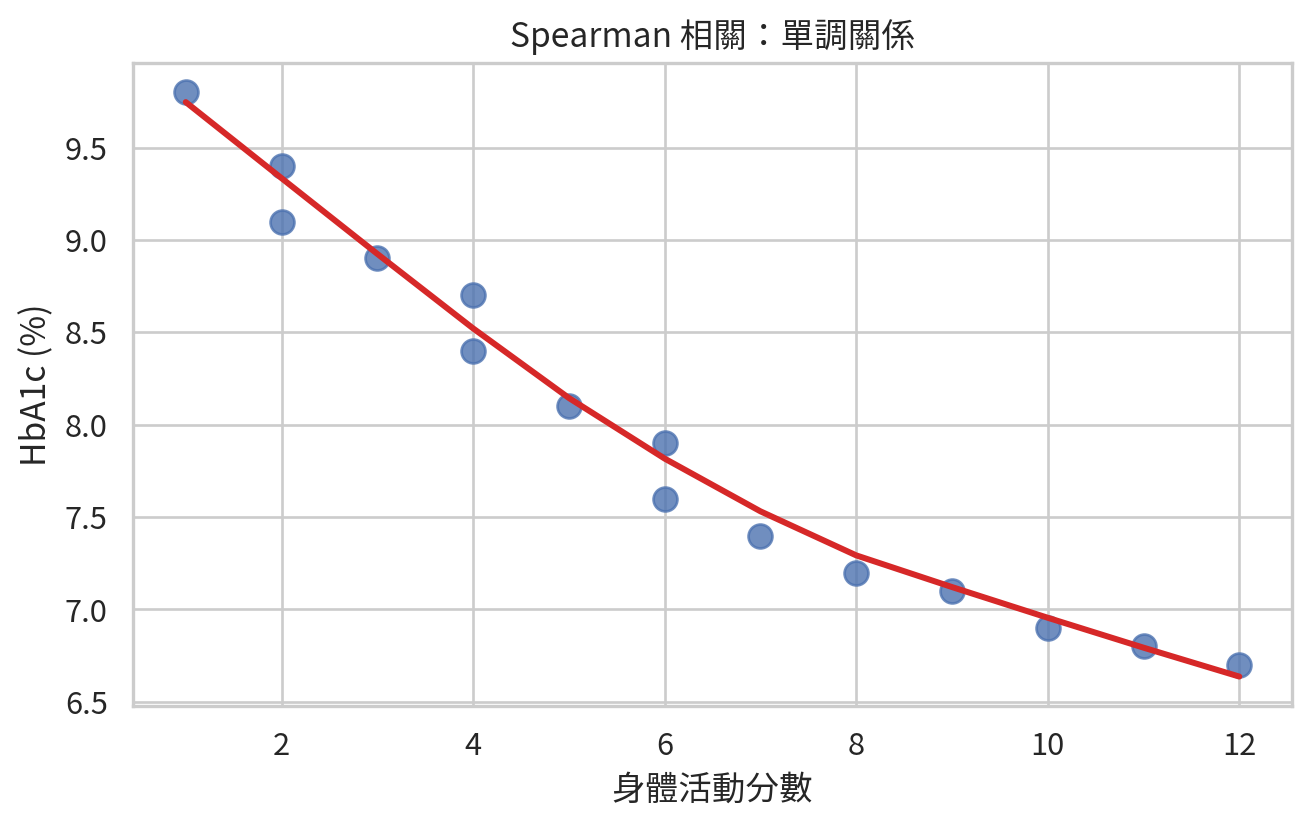
範例 4:身體活動分數與 HbA1c
假設一組糖尿病病人有身體活動分數與 HbA1c。活動分數越高,HbA1c 看起來越低,但關係不一定線性。
activity = np.array([1, 2, 2, 3, 4, 4, 5, 6, 6, 7, 8, 9, 10, 11, 12])
hba1c = np.array([9.8, 9.4, 9.1, 8.9, 8.7, 8.4, 8.1, 7.9, 7.6, 7.4, 7.2, 7.1, 6.9, 6.8, 6.7])
corr_df = pd.DataFrame({"activity_score": activity, "hba1c": hba1c})
corr_df.head()
| 0 |
1 |
9.8 |
| 1 |
2 |
9.4 |
| 2 |
2 |
9.1 |
| 3 |
3 |
8.9 |
| 4 |
4 |
8.7 |
plt.figure(figsize=(7, 4.5))
sns.regplot(data=corr_df, x="activity_score", y="hba1c", lowess=True, scatter_kws={"s": 80}, line_kws={"color": "#d62828"})
plt.xlabel("身體活動分數")
plt.ylabel("HbA1c (%)")
plt.title("Spearman 相關:單調關係")
plt.tight_layout()
plt.savefig(FIG_DIR / "ch09_spearman_activity_hba1c.png", dpi=300)
plt.show()
spearman_result = spearmanr(activity, hba1c)
pd.DataFrame(
{
"quantity": ["Spearman rho", "p 值"],
"value": [spearman_result.statistic, spearman_result.pvalue],
}
).round(4)
| 0 |
Spearman rho |
-0.9973 |
| 1 |
p 值 |
0.0000 |
相關不等於因果。活動量高與 HbA1c 低可能有關,但也可能受到飲食、藥物順從性、病程長短與社經因素影響。Spearman 相關能描述關係,但不能替代研究設計。
置換檢定的直覺
置換檢定是一種重抽樣方法。其核心想法是:若虛無假設下兩組沒有差異,那麼組別標籤應該可以任意交換。每次隨機重新分配標籤並計算統計量,就能建立虛無假設下的參考分布。
置換檢定的優點是直覺清楚,且不需要強烈分布假設。缺點是計算量較大,不過現代電腦通常不是問題。請注意,置換檢定仍依賴交換性 (exchangeability):在虛無假設下,資料標籤可以交換才合理。
def median_difference(x, y, axis=0):
return np.median(x, axis=axis) - np.median(y, axis=axis)
perm_result = permutation_test(
(enhanced_los, standard_los),
median_difference,
alternative="less",
n_resamples=5000,
random_state=20260627,
)
pd.DataFrame(
{
"quantity": ["觀察到的中位數差", "置換檢定 p 值"],
"value": [median_difference(enhanced_los, standard_los), perm_result.pvalue],
}
).round(4)
| 0 |
觀察到的中位數差 |
-1.5000 |
| 1 |
置換檢定 p 值 |
0.2827 |
置換檢定很適合教學,因為它把「如果沒有組間差異,結果會長什麼樣子」這件事具體化。它也提醒我們,統計檢定本質上是在建立一個虛無世界,然後看現實資料在那個世界裡有多不尋常。
常見陷阱
- 以為非參數等於沒有假設:非參數方法仍有資料結構與抽樣假設。
- 把 Mann-Whitney U 一律解釋為中位數差異:只有在分布形狀相似時較合理。
- 忽略配對結構:配對資料應分析差值或使用配對方法。
- 只報 p 值:仍應報告中位數、四分位距或效果量。
- 多組檢定顯著後不做適當事後比較:Kruskal-Wallis 只告訴你至少一組不同。
- 把相關當因果:Spearman 相關只描述單調關係。
本章重點整理
- 非參數方法較少依賴特定母群體分布,常用於偏態、小樣本或次序資料。
- Mann-Whitney U 檢定用於兩獨立樣本的排序比較。
- Wilcoxon 符號等級檢定用於配對資料或單一樣本中位數相關問題。
- Kruskal-Wallis 檢定用於三組以上獨立樣本比較。
- Spearman 等級相關描述兩變項的單調關係。
- 置換檢定透過重新排列標籤建立虛無分布。
- 非參數方法也需要搭配圖形、摘要統計與臨床解釋。
小練習
- 某研究比較兩組住院費用,資料明顯右偏,你會考慮哪一種檢定?為什麼?
- 若同一批病人治療前後疼痛分數為次序尺度,應使用獨立樣本方法還是配對方法?
- Kruskal-Wallis 檢定顯著後,為何不能直接知道哪兩組不同?
- Spearman 相關與 Pearson 相關的主要差異是什麼?
- 用自己的話說明置換檢定的虛無分布如何產生。
practice_group_a = np.array([12, 14, 15, 18, 22, 40])
practice_group_b = np.array([8, 9, 11, 12, 13, 18])
practice_mw = mannwhitneyu(practice_group_b, practice_group_a, alternative="less")
practice_before = np.array([6, 7, 8, 7, 9, 6])
practice_after = np.array([5, 5, 6, 6, 7, 5])
practice_wilcoxon = wilcoxon(practice_after, practice_before, alternative="less")
pd.DataFrame(
{
"檢定": ["Mann-Whitney U", "Wilcoxon signed-rank"],
"統計量": [practice_mw.statistic, practice_wilcoxon.statistic],
"p 值": [practice_mw.pvalue, practice_wilcoxon.pvalue],
}
).round(4)
| 0 |
Mann-Whitney U |
5.0 |
0.0223 |
| 1 |
Wilcoxon signed-rank |
0.0 |
0.0156 |
Glossary
| 非參數方法 |
nonparametric methods |
較少依賴特定母群體分布形式的統計方法。 |
| 排序 |
rank |
將觀察值依大小轉換為名次。 |
| 次序資料 |
ordinal data |
有自然順序但間距未必相等的資料。 |
| Mann-Whitney U 檢定 |
Mann-Whitney U test |
比較兩獨立樣本排序分布的非參數檢定。 |
| Wilcoxon rank-sum test |
Wilcoxon rank-sum test |
Mann-Whitney U 檢定的另一名稱。 |
| 符號檢定 |
sign test |
只使用差值方向進行推論的非參數檢定。 |
| Wilcoxon 符號等級檢定 |
Wilcoxon signed-rank test |
使用配對差值方向與大小排序的非參數檢定。 |
| Kruskal-Wallis 檢定 |
Kruskal-Wallis test |
比較三組以上獨立樣本排序分布的非參數檢定。 |
| Spearman 等級相關 |
Spearman rank correlation |
基於排序衡量兩變項單調關係的相關係數。 |
| 單調關係 |
monotonic relationship |
一變項增加時另一變項大致持續增加或減少的關係。 |
| 置換檢定 |
permutation test |
透過重新排列標籤建立虛無分布的重抽樣檢定。 |
| 交換性 |
exchangeability |
在虛無假設下觀察值標籤可交換的性質。 |
| 事後比較 |
post-hoc comparison |
多組整體檢定後進一步比較特定組別的方法。 |
| 多重比較 |
multiple comparisons |
同時進行多個比較而增加第一型錯誤風險的情況。 |