本章學習目標
機率 (probability) 是生物統計的心臟,也是臨床醫學每天都在使用、但很少被正式命名的語言。當你說「這位病人的肺炎可能性很高」、「這個篩檢陽性不一定代表真的有病」、「這個治療副作用不常見」,其實都在做機率判斷。只是有時候我們穿著白袍講機率,聽起來比較像臨床直覺。
讀完本章後,你應該能夠:
- 說明樣本空間 (sample space)、事件 (event) 與機率的基本概念。
- 使用加法法則 (addition rule) 與乘法法則 (multiplication rule) 計算複合事件機率。
- 區分互斥事件 (mutually exclusive events) 與獨立事件 (independent events)。
- 解釋條件機率 (conditional probability)、敏感度 (sensitivity)、特異度 (specificity)、陽性預測值 (positive predictive value, PPV) 與陰性預測值 (negative predictive value, NPV)。
- 使用貝氏定理 (Bayes’ theorem) 說明疾病盛行率如何改變檢驗結果的臨床意義。
- 使用 Python 進行簡單機率計算與模擬 (simulation)。
為什麼醫學生與公衛學生要學機率?
醫療決策很少有 100% 確定的答案。病史、理學檢查、抽血、影像與篩檢工具都只是提供線索。機率讓我們把這些線索放在同一張地圖上,避免被單一數字牽著走。
例如某檢驗的敏感度與特異度都很高,聽起來很厲害。但若疾病非常罕見,陽性結果仍可能有不少是假陽性。這不是檢驗在搗亂,而是機率在提醒我們:背景風險很重要。臨床上若忘記盛行率,就像只看病人的收縮壓卻完全不問年齡、病史與症狀,會少掉關鍵脈絡。
本章的目的不是把你訓練成賭場精算師,而是讓你能在醫學研究與臨床診斷中,讀懂不確定性,並把不確定性說清楚。
樣本空間、事件與機率
樣本空間 (sample space) 是一次隨機過程所有可能結果的集合。事件 (event) 是樣本空間中的一部分結果。機率是用 0 到 1 之間的數值描述事件發生的可能性。機率 0 代表不可能發生,機率 1 代表必定發生。
在醫學例子中:
- 從門診抽一位病人,事件 A 可以是「有糖尿病」。
- 對病人做篩檢,事件 B 可以是「檢驗結果陽性」。
- 追蹤一組病人,事件 C 可以是「30 天內再住院」。
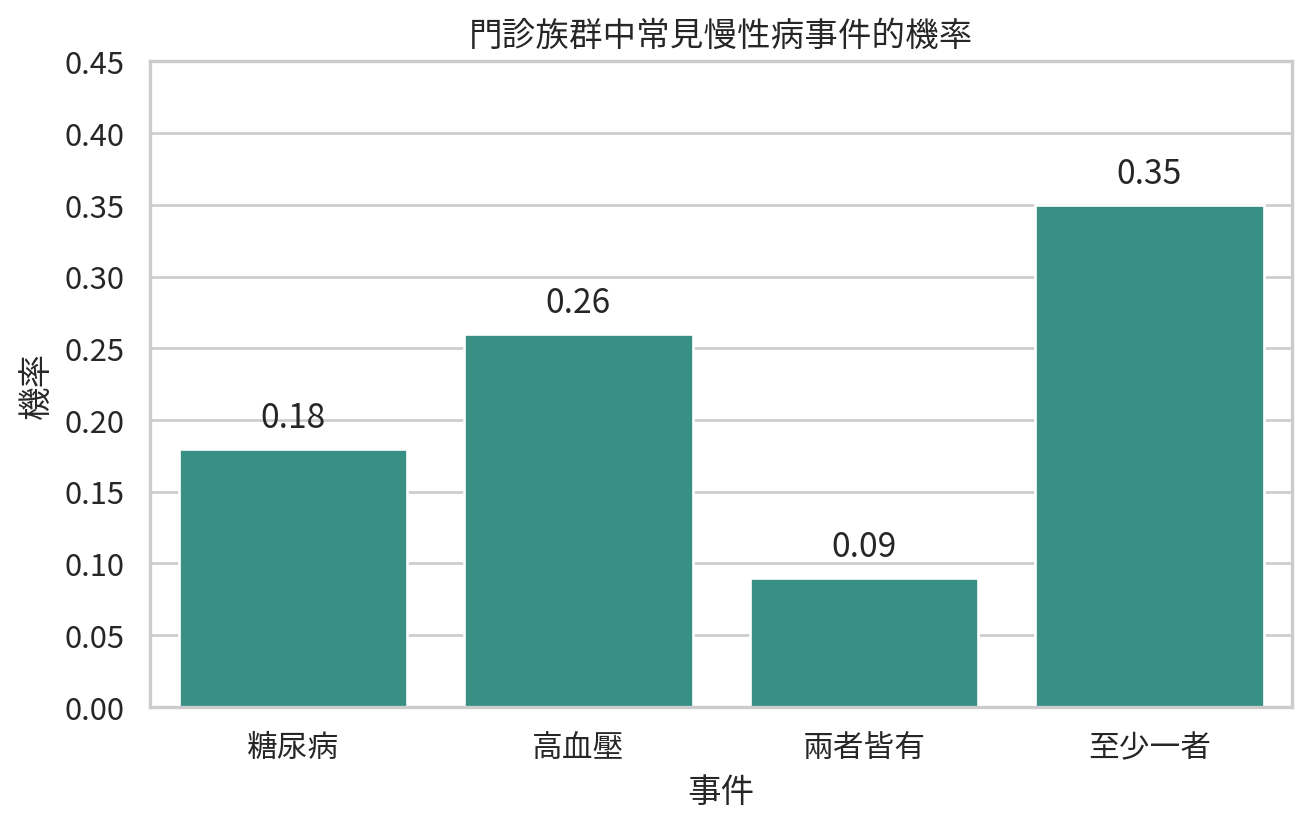
如果 1000 位門診病人中有 180 位有糖尿病,那麼糖尿病的樣本機率約為:
\[
P(\text{糖尿病}) = \frac{180}{1000} = 0.18
\]
這裡的 \(P(A)\) 表示事件 A 發生的機率。機率不是命運宣判,而是根據目前資訊對不確定性的量化。
範例 1:慢性病事件的機率
假設某社區門診抽樣 1000 位成年人,其中 180 位有糖尿病、260 位有高血壓、90 位兩者皆有。下面用 Python 整理事件機率。
n = 1000
diabetes = 180
hypertension = 260
both = 90
at_least_one = diabetes + hypertension - both
risk_data = pd.DataFrame(
{
"event": ["糖尿病", "高血壓", "兩者皆有", "至少一者"],
"count": [diabetes, hypertension, both, at_least_one],
}
)
risk_data["probability"] = risk_data["count"] / n
risk_data
| 0 |
糖尿病 |
180 |
0.18 |
| 1 |
高血壓 |
260 |
0.26 |
| 2 |
兩者皆有 |
90 |
0.09 |
| 3 |
至少一者 |
350 |
0.35 |
plt.figure(figsize=(7, 4.5))
sns.barplot(data=risk_data, x="event", y="probability", color="#2a9d8f")
plt.ylim(0, 0.45)
plt.xlabel("事件")
plt.ylabel("機率")
plt.title("門診族群中常見慢性病事件的機率")
for index, row in risk_data.iterrows():
plt.text(index, row["probability"] + 0.015, f"{row['probability']:.2f}", ha="center")
plt.tight_layout()
plt.savefig(FIG_DIR / "ch03_event_probabilities.png", dpi=300)
plt.show()
這個例子也提醒我們:事件可以重疊。糖尿病與高血壓不是互斥事件,一位病人可以兩者皆有。若直接把 180 與 260 相加,會把同時有兩種疾病的 90 位病人算兩次。
加法法則:至少發生一個事件
加法法則用來計算「A 或 B 發生」的機率。若 A 與 B 可能重疊,公式是:
\[
P(A \cup B) = P(A) + P(B) - P(A \cap B)
\]
其中 \(A \cup B\) 表示 A 或 B 至少一者發生,\(A \cap B\) 表示 A 與 B 同時發生。
在前面的慢性病例子中:
\[
P(\text{糖尿病或高血壓}) = 0.18 + 0.26 - 0.09 = 0.35
\]
若兩個事件不可能同時發生,稱為互斥事件。互斥事件的交集機率為 0,因此:
\[
P(A \cup B) = P(A) + P(B)
\]
例如一位病人的 ABO 血型不可能同時是 A 型又是 B 型,這就是互斥事件。不過「高血壓」和「糖尿病」顯然不是互斥事件;人體很有創意,常常不只帶一個診斷來門診。
乘法法則與條件機率
條件機率 (conditional probability) 是在已知某事件發生的條件下,另一事件發生的機率,記作 \(P(A \mid B)\),讀作「在 B 發生之下 A 的機率」。
乘法法則可寫成:
\[
P(A \cap B) = P(A \mid B)P(B)
\]
也可以寫成:
\[
P(A \cap B) = P(B \mid A)P(A)
\]
從定義來看:
\[
P(A \mid B) = \frac{P(A \cap B)}{P(B)}
\]
在前面的例子中,若 A 是糖尿病,B 是高血壓,則:
\[
P(\text{糖尿病} \mid \text{高血壓}) = \frac{0.09}{0.26} \approx 0.346
\]
也就是高血壓病人中約 34.6% 同時有糖尿病。條件機率很臨床,因為醫師很少在完全空白的情況下判斷;我們總是根據症狀、年齡、檢驗結果與病史更新可能性。
p_diabetes = diabetes / n
p_hypertension = hypertension / n
p_both = both / n
conditional_table = pd.DataFrame(
{
"quantity": [
"P(糖尿病)",
"P(高血壓)",
"P(糖尿病且高血壓)",
"P(糖尿病 | 高血壓)",
"P(高血壓 | 糖尿病)",
],
"value": [
p_diabetes,
p_hypertension,
p_both,
p_both / p_hypertension,
p_both / p_diabetes,
],
}
)
conditional_table["value"] = conditional_table["value"].round(3)
conditional_table
| 0 |
P(糖尿病) |
0.180 |
| 1 |
P(高血壓) |
0.260 |
| 2 |
P(糖尿病且高血壓) |
0.090 |
| 3 |
P(糖尿病 | 高血壓) |
0.346 |
| 4 |
P(高血壓 | 糖尿病) |
0.500 |
獨立不等於互斥
獨立事件 (independent events) 是指一個事件是否發生,不會改變另一事件的機率。如果 A 與 B 獨立,則:
\[
P(A \mid B) = P(A)
\]
也等價於:
\[
P(A \cap B) = P(A)P(B)
\]
請小心:獨立與互斥完全不同。互斥事件不能同時發生;獨立事件則是彼此不影響。若兩個事件互斥且其中一個發生,另一個就不可能發生,因此通常不會獨立,除非其中某事件機率是 0。這一點很容易混淆,統計課常在這裡設小陷阱,不是因為老師壞,是因為概念真的長得有點像。
在慢性病例子中,若糖尿病與高血壓獨立,我們會預期:
\[
P(\text{糖尿病且高血壓}) = 0.18 \times 0.26 = 0.0468
\]
但實際觀察到 0.09,比獨立情況下更高,暗示兩者在此族群中可能相關。
expected_if_independent = p_diabetes * p_hypertension
observed_joint = p_both
pd.DataFrame(
{
"情境": ["若獨立時的 P(兩者皆有)", "實際觀察的 P(兩者皆有)"],
"機率": [expected_if_independent, observed_joint],
}
).round(4)
| 0 |
若獨立時的 P(兩者皆有) |
0.0468 |
| 1 |
實際觀察的 P(兩者皆有) |
0.0900 |
篩檢檢驗的 2x2 表
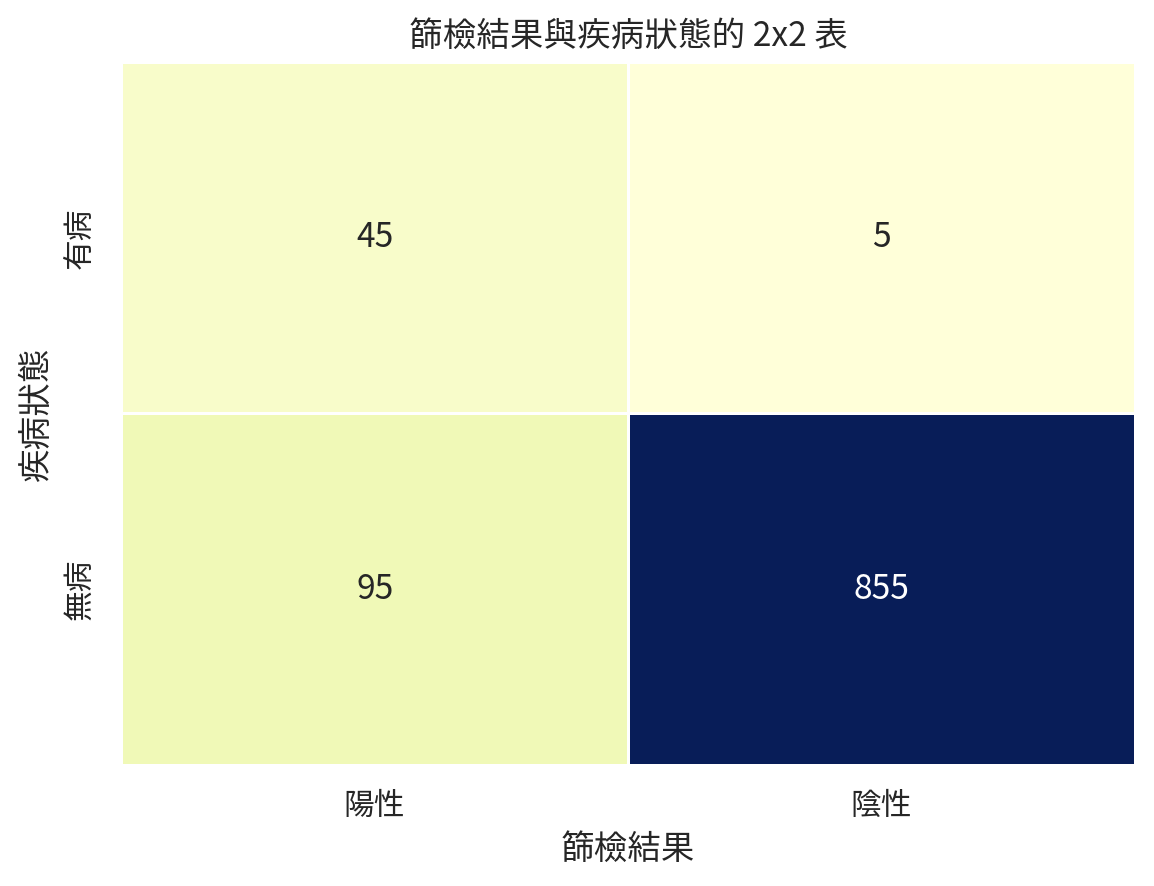
機率在診斷研究中特別重要。假設某疾病盛行率為 5%,在 1000 位受檢者中有 50 位真正有病、950 位沒有病。某篩檢工具在有病者中抓出 45 位陽性,在無病者中有 95 位誤判為陽性。
screening = pd.DataFrame(
{
"disease": ["有病", "有病", "無病", "無病"],
"test": ["陽性", "陰性", "陽性", "陰性"],
"count": [45, 5, 95, 855],
}
)
screening_matrix = (
screening
.pivot(index="disease", columns="test", values="count")
.loc[["有病", "無病"], ["陽性", "陰性"]]
)
screening_matrix
| disease |
|
|
| 有病 |
45 |
5 |
| 無病 |
95 |
855 |
plt.figure(figsize=(6.2, 4.8))
sns.heatmap(screening_matrix, annot=True, fmt="d", cmap="YlGnBu", cbar=False, linewidths=0.5)
plt.xlabel("篩檢結果")
plt.ylabel("疾病狀態")
plt.title("篩檢結果與疾病狀態的 2x2 表")
plt.tight_layout()
plt.savefig(FIG_DIR / "ch03_screening_heatmap.png", dpi=300)
plt.show()
這張表可以算出四個診斷研究常見指標:
- 敏感度:有病的人中,檢驗陽性的比例。
- 特異度:無病的人中,檢驗陰性的比例。
- 陽性預測值:檢驗陽性的人中,真正有病的比例。
- 陰性預測值:檢驗陰性的人中,真正無病的比例。
tp = screening_matrix.loc["有病", "陽性"]
fn = screening_matrix.loc["有病", "陰性"]
fp = screening_matrix.loc["無病", "陽性"]
tn = screening_matrix.loc["無病", "陰性"]
sensitivity = tp / (tp + fn)
specificity = tn / (tn + fp)
ppv = tp / (tp + fp)
npv = tn / (tn + fn)
diagnostic_metrics = pd.DataFrame(
{
"指標": ["敏感度", "特異度", "陽性預測值", "陰性預測值"],
"英文": ["sensitivity", "specificity", "positive predictive value", "negative predictive value"],
"數值": [sensitivity, specificity, ppv, npv],
}
)
diagnostic_metrics["數值"] = diagnostic_metrics["數值"].round(3)
diagnostic_metrics
| 0 |
敏感度 |
sensitivity |
0.900 |
| 1 |
特異度 |
specificity |
0.900 |
| 2 |
陽性預測值 |
positive predictive value |
0.321 |
| 3 |
陰性預測值 |
negative predictive value |
0.994 |
請注意:敏感度與特異度是以疾病狀態為條件;PPV 與 NPV 是以檢驗結果為條件。臨床醫師拿到檢驗結果後,通常真正想知道的是 PPV 或 NPV,而不是只有敏感度與特異度。
貝氏定理:檢驗結果如何更新疾病機率
貝氏定理 (Bayes’ theorem) 是條件機率的直接應用。若 D 代表有病,+ 代表檢驗陽性,則:
\[
P(D \mid +) = \frac{P(+ \mid D)P(D)}{P(+)}
\]
其中 \(P(D)\) 是檢驗前機率 (pre-test probability),常可由疾病盛行率、臨床風險或醫師判斷估計;\(P(D \mid +)\) 是檢驗後機率 (post-test probability)。
在篩檢情境中,疾病越罕見,即使檢驗本身不差,陽性結果中假陽性的比例仍可能很高。這就是為什麼低風險族群的大規模篩檢需要特別小心:陽性不一定是壞消息的確認,有時候只是進一步檢查的開始。
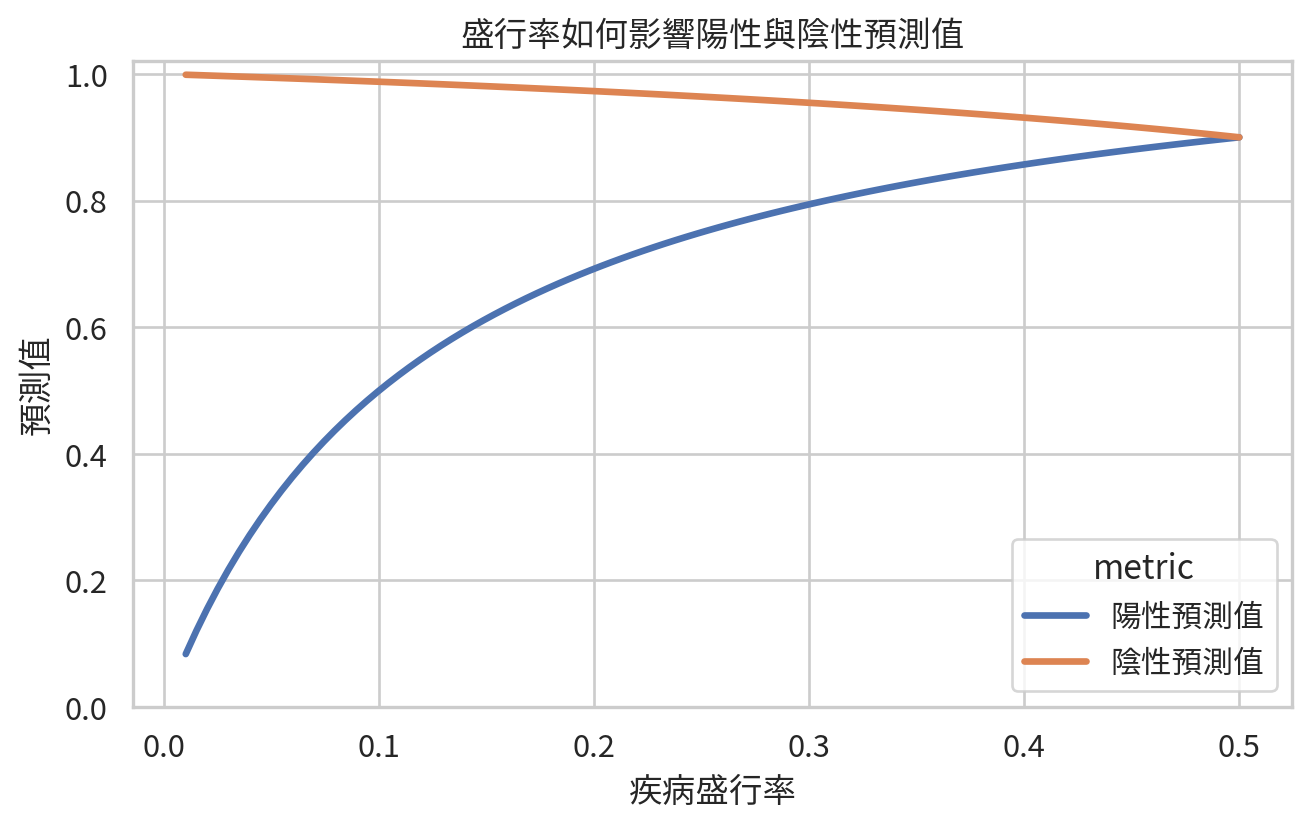
範例 2:盛行率如何影響 PPV 與 NPV
假設某檢驗敏感度與特異度皆為 90%。我們改變疾病盛行率,看看 PPV 與 NPV 如何變化。
def screening_metrics(prevalence: float, sensitivity: float = 0.90, specificity: float = 0.90) -> tuple:
ppv = sensitivity * prevalence / (sensitivity * prevalence + (1 - specificity) * (1 - prevalence))
npv = specificity * (1 - prevalence) / ((1 - sensitivity) * prevalence + specificity * (1 - prevalence))
return ppv, npv
prevalence_grid = np.linspace(0.01, 0.50, 100)
metric_rows = []
for prevalence in prevalence_grid:
current_ppv, current_npv = screening_metrics(prevalence)
metric_rows.append({"prevalence": prevalence, "metric": "陽性預測值", "value": current_ppv})
metric_rows.append({"prevalence": prevalence, "metric": "陰性預測值", "value": current_npv})
metrics = pd.DataFrame(metric_rows)
metrics.head()
| 0 |
0.010000 |
陽性預測值 |
0.083333 |
| 1 |
0.010000 |
陰性預測值 |
0.998879 |
| 2 |
0.014949 |
陽性預測值 |
0.120173 |
| 3 |
0.014949 |
陰性預測值 |
0.998317 |
| 4 |
0.019899 |
陽性預測值 |
0.154496 |
plt.figure(figsize=(7, 4.5))
sns.lineplot(data=metrics, x="prevalence", y="value", hue="metric", linewidth=2.5)
plt.xlabel("疾病盛行率")
plt.ylabel("預測值")
plt.title("盛行率如何影響陽性與陰性預測值")
plt.ylim(0, 1.02)
plt.tight_layout()
plt.savefig(FIG_DIR / "ch03_prevalence_predictive_values.png", dpi=300)
plt.show()
圖中最重要的訊息是:PPV 會隨盛行率上升而上升,NPV 則通常在低盛行率時很高。換句話說,同一個檢驗在不同族群中,臨床意義可能完全不同。檢驗不會自己講背景故事,所以我們要替它補上。
勝算與風險
風險 (risk) 是事件發生的機率。例如 100 位病人中 20 位發生副作用,風險是 0.20。勝算 (odds) 是事件發生機率除以未發生機率:
\[
\text{odds} = \frac{p}{1-p}
\]
若副作用風險為 0.20,勝算為:
\[
\frac{0.20}{0.80} = 0.25
\]
風險與勝算不同。當事件很罕見時,兩者數值接近;當事件常見時,勝算會比風險大很多。病例對照研究與邏輯斯迴歸常使用勝算比 (odds ratio),因此理解勝算很重要。它一開始有點不直覺,但多看幾次就會熟,像第一次看心電圖也不會馬上跟 P 波成為好朋友。
risk_values = pd.DataFrame({"risk": [0.01, 0.05, 0.10, 0.20, 0.50, 0.80]})
risk_values["odds"] = risk_values["risk"] / (1 - risk_values["risk"])
risk_values.round(3)
| 0 |
0.01 |
0.010 |
| 1 |
0.05 |
0.053 |
| 2 |
0.10 |
0.111 |
| 3 |
0.20 |
0.250 |
| 4 |
0.50 |
1.000 |
| 5 |
0.80 |
4.000 |
模擬:用電腦看見機率
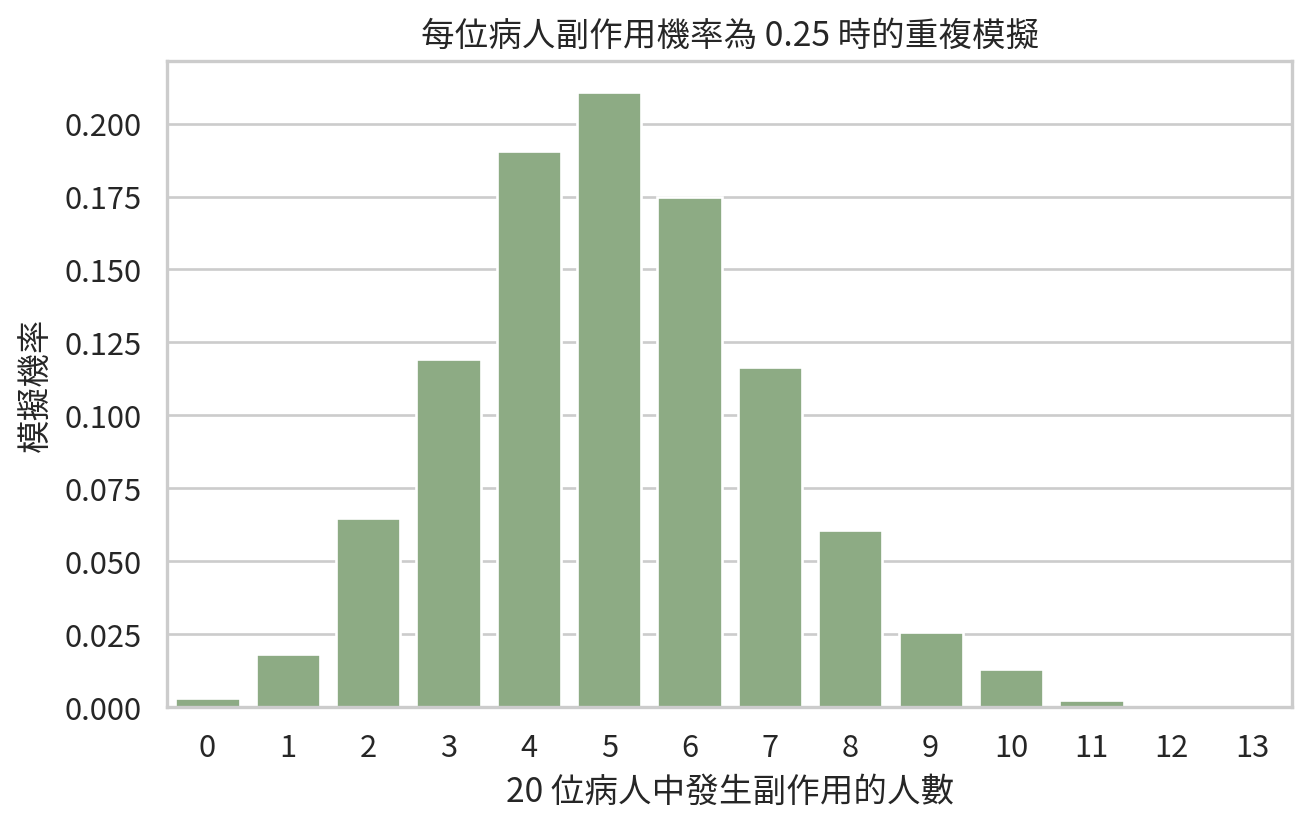
模擬 (simulation) 是用電腦重複產生隨機結果,觀察長期行為的方法。它不能取代數學推導,但能幫助我們建立直覺。
假設某藥物的副作用機率是 0.25。若每次收治 20 位使用此藥的病人,發生副作用的人數會是多少?每一批 20 人都不一樣,但若重複很多次,分布會逐漸穩定。
simulated_trials = np.random.binomial(n=20, p=0.25, size=5000)
sim_df = pd.DataFrame({"events": simulated_trials})
simulation_summary = (
sim_df["events"]
.value_counts(normalize=True)
.sort_index()
.reset_index()
)
simulation_summary.columns = ["events", "probability"]
simulation_summary.head(10)
| 0 |
0 |
0.0030 |
| 1 |
1 |
0.0182 |
| 2 |
2 |
0.0646 |
| 3 |
3 |
0.1194 |
| 4 |
4 |
0.1906 |
| 5 |
5 |
0.2108 |
| 6 |
6 |
0.1748 |
| 7 |
7 |
0.1164 |
| 8 |
8 |
0.0606 |
| 9 |
9 |
0.0258 |
plt.figure(figsize=(7, 4.5))
sns.barplot(data=simulation_summary, x="events", y="probability", color="#8ab17d")
plt.xlabel("20 位病人中發生副作用的人數")
plt.ylabel("模擬機率")
plt.title("每位病人副作用機率為 0.25 時的重複模擬")
plt.tight_layout()
plt.savefig(FIG_DIR / "ch03_binomial_simulation.png", dpi=300)
plt.show()
這張圖讓我們看到,即使單一病人副作用機率固定為 0.25,每批 20 位病人中實際發生副作用的人數仍會變動。這就是隨機變異 (random variation)。臨床研究若樣本太小,結果很容易被這種變動影響;這也是後面學估計與假設檢定時會一直遇到的核心問題。
常見陷阱
- 把機率當作確定預言:機率 0.80 不是保證發生,機率 0.05 也不是不會發生。
- 混淆敏感度與 PPV:敏感度是有病者中陽性的比例;PPV 是陽性者中有病的比例。
- 忽略盛行率:同一個檢驗在不同族群中,陽性結果的意義可能不同。
- 把互斥當獨立:互斥是不能同時發生;獨立是彼此不影響。
- 只看單一檢驗結果:臨床判斷應結合檢驗前機率與檢驗特性。
本章重點整理
- 機率是描述不確定性的數學語言,範圍介於 0 與 1 之間。
- 加法法則用於計算「A 或 B」的機率;若事件重疊,要扣掉交集。
- 條件機率描述在已知某事件發生時,另一事件發生的機率。
- 獨立事件與互斥事件不同,兩者不可混為一談。
- 敏感度與特異度描述檢驗在疾病狀態下的表現;PPV 與 NPV 描述拿到檢驗結果後的疾病機率。
- 貝氏定理說明檢驗前機率與檢驗特性如何共同決定檢驗後機率。
- 模擬能幫助我們理解隨機變異與長期機率行為。
小練習
- 若 500 位病人中有 60 位吸菸、90 位有高血壓、25 位兩者皆有,計算 \(P(\text{吸菸或高血壓})\)。
- 在同一資料中,計算 \(P(\text{高血壓} \mid \text{吸菸})\)。
- 某檢驗敏感度 0.95、特異度 0.85、疾病盛行率 0.02,計算 PPV 與 NPV。
- 用
np.random.binomial() 模擬 1000 次,每次 50 位病人、副作用機率 0.10,畫出副作用人數分布。
- 用自己的話說明為什麼罕見疾病的篩檢陽性結果需要謹慎解釋。
smoking = 60
hypertension_exercise = 90
both_exercise = 25
n_exercise = 500
p_smoking_or_hypertension = (smoking + hypertension_exercise - both_exercise) / n_exercise
p_hypertension_given_smoking = both_exercise / smoking
exercise_ppv, exercise_npv = screening_metrics(prevalence=0.02, sensitivity=0.95, specificity=0.85)
practice_results = pd.DataFrame(
{
"quantity": [
"P(吸菸或高血壓)",
"P(高血壓 | 吸菸)",
"PPV",
"NPV",
],
"value": [
p_smoking_or_hypertension,
p_hypertension_given_smoking,
exercise_ppv,
exercise_npv,
],
}
)
practice_results["value"] = practice_results["value"].round(3)
practice_results
| 0 |
P(吸菸或高血壓) |
0.250 |
| 1 |
P(高血壓 | 吸菸) |
0.417 |
| 2 |
PPV |
0.114 |
| 3 |
NPV |
0.999 |
Glossary
| 機率 |
probability |
描述事件發生可能性的數值,介於 0 與 1 之間。 |
| 樣本空間 |
sample space |
一次隨機過程所有可能結果的集合。 |
| 事件 |
event |
樣本空間中的一部分結果。 |
| 加法法則 |
addition rule |
用來計算至少一個事件發生機率的法則。 |
| 乘法法則 |
multiplication rule |
用來計算事件交集機率的法則。 |
| 互斥事件 |
mutually exclusive events |
不可能同時發生的事件。 |
| 獨立事件 |
independent events |
一事件發生不改變另一事件機率的情況。 |
| 交集 |
intersection |
兩個事件同時發生的部分。 |
| 聯集 |
union |
兩個事件至少一者發生的部分。 |
| 條件機率 |
conditional probability |
在已知某事件發生下,另一事件發生的機率。 |
| 敏感度 |
sensitivity |
有病者中檢驗陽性的比例。 |
| 特異度 |
specificity |
無病者中檢驗陰性的比例。 |
| 陽性預測值 |
positive predictive value, PPV |
檢驗陽性者中真正有病的比例。 |
| 陰性預測值 |
negative predictive value, NPV |
檢驗陰性者中真正無病的比例。 |
| 貝氏定理 |
Bayes’ theorem |
用條件機率更新事件機率的定理。 |
| 檢驗前機率 |
pre-test probability |
檢驗前根據背景風險或臨床資訊估計的疾病機率。 |
| 檢驗後機率 |
post-test probability |
納入檢驗結果後更新的疾病機率。 |
| 盛行率 |
prevalence |
特定時間點或期間族群中已有疾病的比例。 |
| 風險 |
risk |
事件發生的機率。 |
| 勝算 |
odds |
事件發生機率除以未發生機率。 |
| 勝算比 |
odds ratio |
兩組勝算的比值。 |
| 模擬 |
simulation |
用電腦重複產生隨機結果以研究機率行為的方法。 |
| 隨機變異 |
random variation |
即使機率固定,實際觀察結果仍會自然波動的現象。 |