本章學習目標
前一章談到流行病學研究設計。本章處理一個更貼近追蹤研究的問題:如果每位研究對象的追蹤時間不同,該怎麼比較事件發生?
例如某研究追蹤病人再住院。有些人完整追蹤 2 年,有些人搬家失訪,有些人 3 個月後就發生事件。這時單純用「事件人數 / 總人數」會浪費資訊,甚至造成偏差。Person-time data 會把每個人實際貢獻的追蹤時間加總,計算 incidence rate。
讀完本章後,你應該能夠:
解釋 person-time 與 incidence rate 的意義。
使用 Poisson distribution 建立事件數模型的直覺。
計算 incidence rate 與 Poisson 信賴區間。
比較兩組 incidence rate 並解讀 rate ratio。
計算 standardized mortality ratio (SMR)。
理解 censoring、Kaplan-Meier curve 與 log-rank test 的基本概念。
辨認 person-time 分析常見錯誤。
為什麼需要 person-time?
假設兩個診所各追蹤 100 位病人。診所 A 平均追蹤 6 個月,診所 B 平均追蹤 2 年。若兩者都發生 10 件事件,能說事件風險一樣嗎?不能。診所 B 給事件發生的時間窗口比較長。
Person-time 是每位研究對象貢獻的追蹤時間總和。例如 100 人各追蹤 2 年,總 person-time 是 200 person-years。Incidence rate 則是:
\[
\text{Incidence rate} = \frac{\text{number of events}}{\text{total person-time}}
\]
常見單位包括每 1,000 person-years 或每 100,000 person-years。單位要寫清楚,不然讀者會像在看沒有標示劑量的處方。
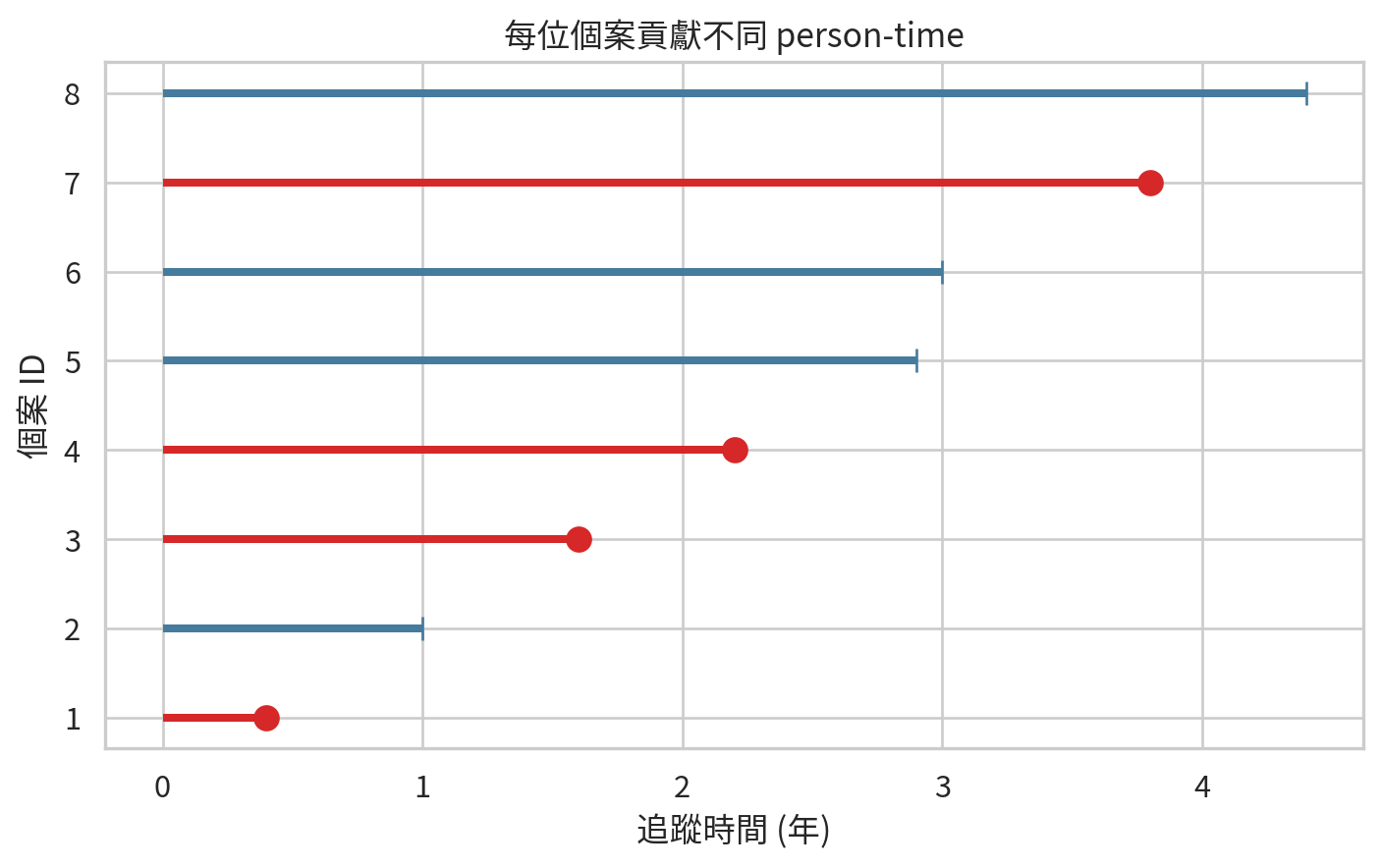
每位個案貢獻不同追蹤時間
= pd.DataFrame("id" : np.arange(1 , 9 ),"follow_up" : [0.4 , 1.0 , 1.6 , 2.2 , 2.9 , 3.0 , 3.8 , 4.4 ],"event" : [1 , 0 , 1 , 1 , 0 , 0 , 1 , 0 ],
0
1
0.4
1
1
2
1.0
0
2
3
1.6
1
3
4
2.2
1
4
5
2.9
0
5
6
3.0
0
6
7
3.8
1
7
8
4.4
0
= (7.5 , 4.8 ))for _, row in person_time_df.iterrows():= "#d62828" if row["event" ] == 1 else "#457b9d" "id" ], 0 , row["follow_up" ], color= color, linewidth= 3 )= "o" if row["event" ] == 1 else "|" "follow_up" ], row["id" ], marker= marker, color= color, markersize= 9 )"追蹤時間 (年)" )"個案 ID" )"每位個案貢獻不同 person-time" )/ "ch14_person_time_rugs.png" , dpi= 300 )
= person_time_df["event" ].sum ()= person_time_df["follow_up" ].sum ()= events / person_years * 1000 "quantity" : ["事件數" , "總 person-years" , "每 1,000 person-years 事件率" ],"value" : [events, person_years, rate_per_1000],round (2 )
0
事件數
4.00
1
總 person-years
19.30
2
每 1,000 person-years 事件率
207.25
設限 (censoring) 指研究對象在追蹤期間未發生事件,但後續狀態未知或追蹤結束。例如研究結束、失訪、搬家、退出研究。設限不是失敗,它只是告訴我們:「到這個時間點為止,尚未觀察到事件。」
Poisson model 的基本直覺
Person-time 事件數常用 Poisson distribution 建模,特別是事件相對少、每個小時間段發生事件的機率低時。Poisson 模型的平均事件數可寫成:
\[
E(Y) = \lambda T
\]
其中 \(Y\) 是事件數,\(\lambda\) 是事件率,\(T\) 是 person-time。若已知 person-time,事件數越多,估計事件率越高。
範例 1:兩種照護模式的事件率
假設比較標準照護與遠距追蹤的急診回診事件。標準照護組有 42 件事件、815.4 person-years;遠距追蹤組有 27 件事件、842.8 person-years。
= pd.DataFrame("group" : ["標準照護" , "遠距追蹤" ],"events" : [42 , 27 ],"person_years" : [815.4 , 842.8 ],"rate_per_1000" ] = rate_df["events" ] / rate_df["person_years" ] * 1000
0
標準照護
42
815.4
51.508462
1
遠距追蹤
27
842.8
32.036070
def poisson_rate_ci(events, person_time, multiplier= 1000 ):= 0.5 * chi2.ppf(0.025 , 2 * events) / person_time= 0.5 * chi2.ppf(0.975 , 2 * (events + 1 )) / person_timereturn events / person_time * multiplier, lower * multiplier, upper * multiplier
"rate" , "lower" , "upper" ]] = rate_df.apply (lambda row: pd.Series(poisson_rate_ci(row["events" ], row["person_years" ])),= 1 ,round (2 )
0
標準照護
42
815.4
51.51
51.51
37.12
69.62
1
遠距追蹤
27
842.8
32.04
32.04
21.11
46.61
= (7 , 4.5 ))"group" ],"rate" ],= [rate_df["rate" ] - rate_df["lower" ], rate_df["upper" ] - rate_df["rate" ]],= "o" ,= "#2a9d8f" ,= 5 ,"每 1,000 人年事件率" )"照護模式" )"Person-time 資料的 incidence rate" )/ "ch14_incidence_rate_ci.png" , dpi= 300 )
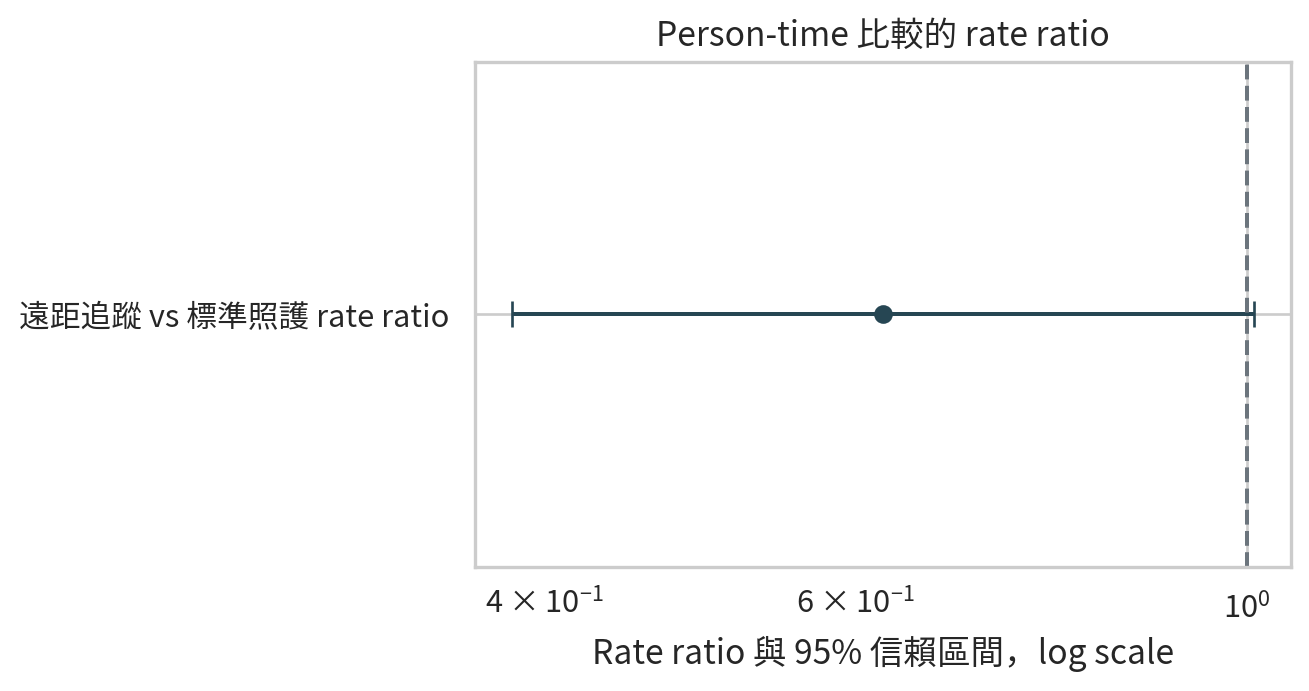
Rate ratio 與假設檢定
兩組 incidence rate 的比值稱為 rate ratio。若 rate ratio = 1,表示兩組事件率相同。若小於 1,代表分子組事件率較低。
def rate_ratio_ci(events_a, pt_a, events_b, pt_b):= (events_a / pt_a) / (events_b / pt_b)= np.sqrt(1 / events_a + 1 / events_b)= np.exp(np.log(rr) + np.array([- 1.96 , 1.96 ]) * se_log)= np.log(rr) / se_log= 2 * (1 - norm.cdf(abs (z_stat)))return rr, ci, z_stat, p_value
= rate_ratio_ci(27 , 842.8 , 42 , 815.4 )"quantity" : ["Rate ratio" , "95% CI 下限" , "95% CI 上限" , "z 統計量" , "雙尾 p 值" ],"value" : [rr, rr_ci[0 ], rr_ci[1 ], rr_z, rr_p],round (4 )
0
Rate ratio
0.6220
1
95% CI 下限
0.3835
2
95% CI 上限
1.0086
3
z 統計量
-1.9252
4
雙尾 p 值
0.0542
= pd.DataFrame("measure" : ["遠距追蹤 vs 標準照護 rate ratio" ],"estimate" : [rr],"lower" : [rr_ci[0 ]],"upper" : [rr_ci[1 ]],= (7 , 3.8 ))"estimate" ],"measure" ],= [effect_df["estimate" ] - effect_df["lower" ], effect_df["upper" ] - effect_df["estimate" ]],= "o" ,= "#264653" ,= 5 ,1 , color= "#6c757d" , linestyle= "--" )"log" )"Rate ratio 與 95% 信賴區間,log scale" )"" )"Person-time 比較的 rate ratio" )/ "ch14_rate_ratio_forest.png" , dpi= 300 )
Rate ratio 的信賴區間若跨過 1,表示資料與兩組事件率相同仍相容。若沒有跨過 1,代表有較明確的事件率差異證據。不過仍要看絕對事件率差異,因為 rate ratio 只告訴我們相對大小。
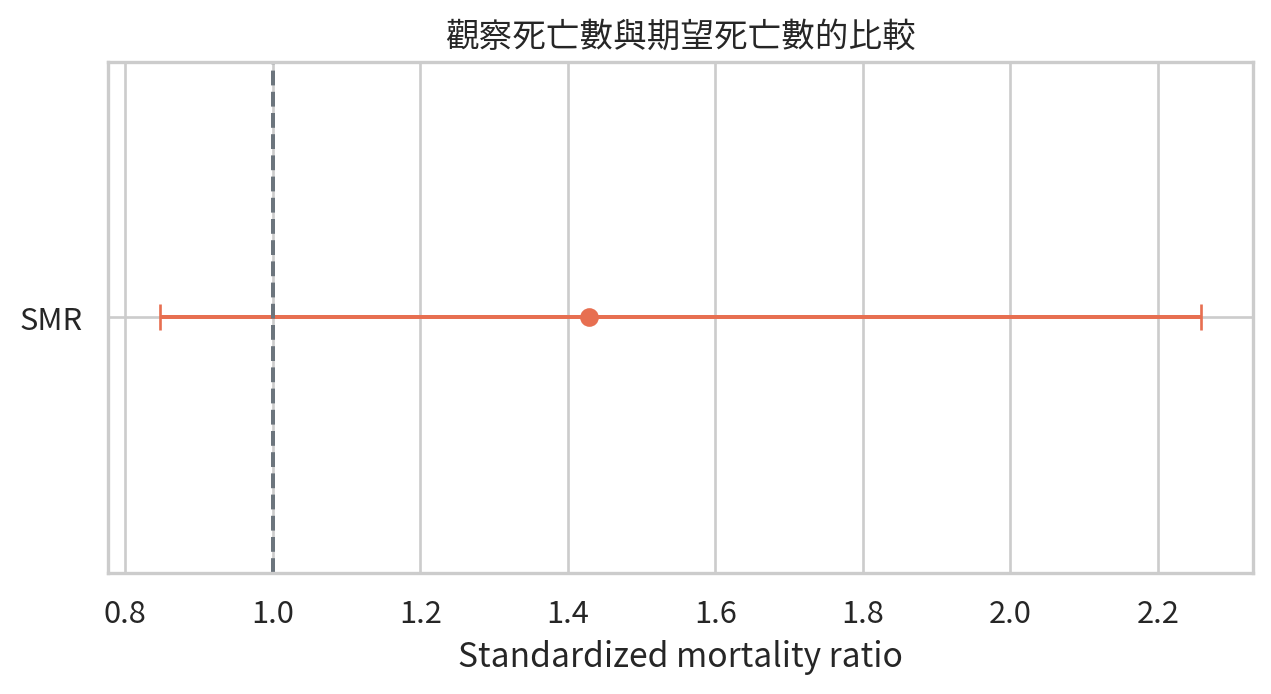
Standardized mortality ratio
Standardized mortality ratio (SMR) 用於比較觀察死亡數與根據外部標準率所得到的期望死亡數:
\[
\text{SMR} = \frac{\text{observed deaths}}{\text{expected deaths}}
\]
若 SMR = 1,表示觀察死亡數與期望死亡數相同;若 SMR > 1,表示觀察死亡數高於期望。
def smr_ci(observed, expected):= observed / expected= 0.5 * chi2.ppf(0.025 , 2 * observed) / expected= 0.5 * chi2.ppf(0.975 , 2 * (observed + 1 )) / expectedreturn smr, lower, upper
= 18 = 12.6 = smr_ci(observed, expected)= poisson.sf(observed - 1 , expected)"quantity" : ["觀察死亡數" , "期望死亡數" , "SMR" , "95% CI 下限" , "95% CI 上限" , "Poisson 單尾 p 值" ],"value" : [observed, expected, smr, smr_lower, smr_upper, poisson_p],round (4 )
0
觀察死亡數
18.0000
1
期望死亡數
12.6000
2
SMR
1.4286
3
95% CI 下限
0.8467
4
95% CI 上限
2.2578
5
Poisson 單尾 p 值
0.0889
= pd.DataFrame({"quantity" : ["SMR" ], "estimate" : [smr], "lower" : [smr_lower], "upper" : [smr_upper]})= (6.8 , 3.8 ))"estimate" ],"quantity" ],= [smr_plot["estimate" ] - smr_plot["lower" ], smr_plot["upper" ] - smr_plot["estimate" ]],= "o" ,= "#e76f51" ,= 5 ,1 , color= "#6c757d" , linestyle= "--" )"Standardized mortality ratio" )"" )"觀察死亡數與期望死亡數的比較" )/ "ch14_smr_ci.png" , dpi= 300 )
SMR 常見於職業流行病學或醫院品質監測。解讀時要記得:期望死亡數來自外部標準率,因此標準族群是否合適很重要。
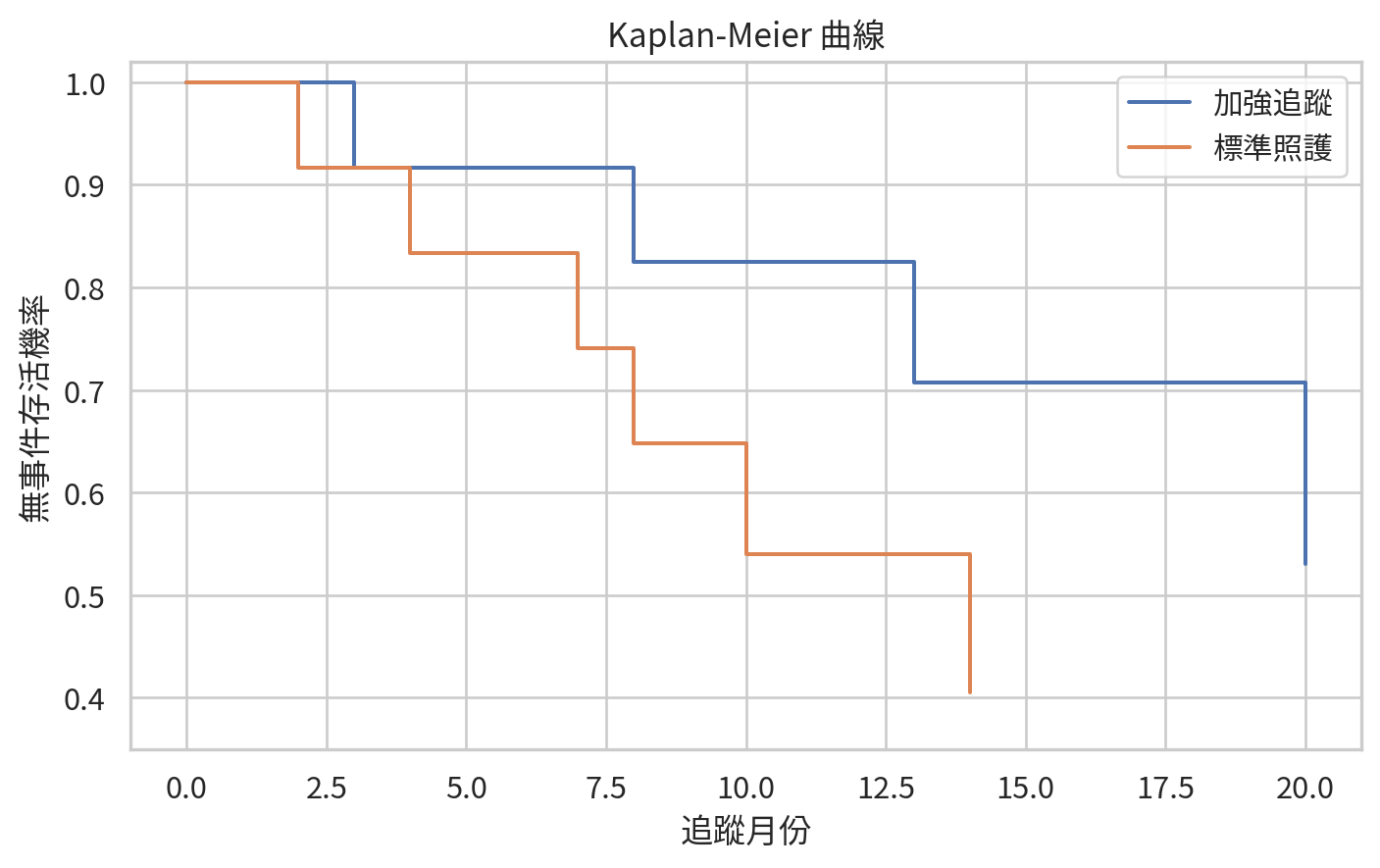
Time-to-event data 與 Kaplan-Meier curve
Person-time rate 把事件數與追蹤時間加總成一個率。若我們更想看事件隨時間累積的過程,就會進入 time-to-event analysis,也稱 survival analysis。
Kaplan-Meier curve 用來估計某時間點仍未發生事件的機率。它可以處理右設限資料,並在每個事件時間點更新存活機率。
def kaplan_meier_table(times, events):= np.argsort(times)= np.asarray(times)[order]= np.asarray(events)[order]= []= 1.0 for time in np.unique(times[events == 1 ]):= np.sum (times >= time)= np.sum ((times == time) & (events == 1 ))*= 1 - observed_events / at_risk"time" : time, "at_risk" : at_risk, "events" : observed_events, "survival" : survival})return pd.DataFrame(rows)
= np.array([2 , 4 , 5 , 7 , 8 , 9 , 10 , 12 , 14 , 16 , 18 , 20 ])= np.array([1 , 1 , 0 , 1 , 1 , 0 , 1 , 0 , 1 , 0 , 0 , 0 ])= np.array([3 , 6 , 8 , 9 , 11 , 13 , 15 , 18 , 20 , 22 , 24 , 24 ])= np.array([1 , 0 , 1 , 0 , 0 , 1 , 0 , 0 , 1 , 0 , 0 , 0 ])= kaplan_meier_table(standard_time, standard_event)"group" ] = "標準照護" = kaplan_meier_table(enhanced_time, enhanced_event)"group" ] = "加強追蹤" = pd.concat([km_standard, km_enhanced], ignore_index= True )
0
2
12
1
0.916667
標準照護
1
4
11
1
0.833333
標準照護
2
7
9
1
0.740741
標準照護
3
8
8
1
0.648148
標準照護
4
10
6
1
0.540123
標準照護
5
14
4
1
0.405093
標準照護
6
3
12
1
0.916667
加強追蹤
7
8
10
1
0.825000
加強追蹤
8
13
7
1
0.707143
加強追蹤
9
20
4
1
0.530357
加強追蹤
= (7.5 , 4.8 ))for group_name, part in km_df.groupby("group" ):= np.r_[0 , part["time" ]]= np.r_[1 , part["survival" ]]= "post" , label= group_name)"追蹤月份" )"無事件存活機率" )0.35 , 1.02 )"Kaplan-Meier 曲線" )/ "ch14_kaplan_meier_curve.png" , dpi= 300 )
Log-rank test
Log-rank test 用於比較兩組 Kaplan-Meier 曲線。它在每個事件時間點比較觀察事件數與期望事件數,最後加總成一個卡方統計量。
def logrank_two_group(time_a, event_a, time_b, event_b):= np.sort(np.unique(np.r_[np.asarray(time_a)[event_a == 1 ], np.asarray(time_b)[event_b == 1 ]]))= 0.0 = 0.0 = 0.0 for event_time in times:= np.sum (time_a >= event_time)= np.sum (time_b >= event_time)= np.sum ((time_a == event_time) & (event_a == 1 ))= np.sum ((time_b == event_time) & (event_b == 1 ))= risk_a + risk_b= event_a_at_time + event_b_at_timeif risk_total <= 1 :continue = event_total * risk_a / risk_total= risk_a * risk_b * event_total * (risk_total - event_total) / (risk_total** 2 * (risk_total - 1 ))+= event_a_at_time+= expected_a+= variance= (observed_a_total - expected_a_total) ** 2 / variance_total= 1 - chi2.cdf(chi_square, df= 1 )return chi_square, p_value, observed_a_total, expected_a_total
= logrank_two_group("quantity" : ["log-rank chi-square" , "p 值" , "標準照護觀察事件數" , "標準照護期望事件數" ],"value" : [logrank_chi2, logrank_p, observed_a, expected_a],round (4 )
0
log-rank chi-square
1.3343
1
p 值
0.2480
2
標準照護觀察事件數
6.0000
3
標準照護期望事件數
4.2330
Log-rank test 檢定的是兩組整體事件時間分布是否不同。若研究目標是估計暴露對 hazard 的影響,或需要調整共變項,下一步通常會使用 Cox proportional hazards model。那已經是進階存活分析的入口,這本導論先把門打開一點點,不把你推進去。
常見錯誤
第一個錯誤是追蹤時間不同卻只看事件比例。若每組 person-time 不同,事件比例可能誤導。
第二個錯誤是把 incidence rate 解讀成 risk。Rate 可以大於 1,因為它是每單位時間事件數;risk 是機率,介於 0 到 1。
第三個錯誤是忽略設限機制。Kaplan-Meier 與 log-rank 通常假設設限是非資訊性設限,也就是設限原因不應與未來事件風險強烈相關。
第四個錯誤是只報 rate ratio,不報各組事件率與 person-time。沒有分母時間,讀者很難判斷資料量與臨床意義。
第五個錯誤是遇到重複事件仍當成單次事件分析。若同一病人可多次急診或多次感染,需要考慮 recurrent event 方法或合適的 Poisson/negative binomial 模型。
本章重點整理
Person-time data 適合處理追蹤時間不一致的事件資料。Incidence rate 是事件數除以總 person-time,Poisson distribution 提供事件數檢定與信賴區間的基礎。兩組事件率可用 rate ratio 比較,SMR 可用來比較觀察事件數與外部標準下的期望事件數。
當研究問題關心事件發生時間,而不只是總事件率時,Kaplan-Meier curve 可呈現無事件存活機率,log-rank test 可比較兩組曲線。到這裡,全書從資料描述、機率、估計、檢定、迴歸、流行病學設計一路走到追蹤時間資料,統計地圖終於多了一條時間軸。
小練習
某研究觀察到 36 件感染事件,總追蹤時間為 720 person-years。請計算每 1,000 person-years 的感染率。
A 組有 20 件事件、500 person-years;B 組有 35 件事件、620 person-years。請計算 rate ratio。
為什麼 person-time rate 不是 risk?
某醫院觀察死亡數為 25,依標準人口期望死亡數為 20。請計算 SMR 並解釋。
請說明 censoring 在 Kaplan-Meier 分析中的角色。
Log-rank test 顯著時,是否能直接說某組 hazard ratio 等於多少?為什麼?
Glossary
人時
person-time
每位研究對象貢獻追蹤時間的總和。
人年
person-years
以年為單位的 person-time。
發生率
incidence rate
事件數除以總 person-time。
率比
rate ratio
兩組 incidence rate 的比值。
Poisson 分布
Poisson distribution
常用於描述固定時間或空間中事件數的離散分布。
標準化死亡比
standardized mortality ratio, SMR
觀察死亡數除以期望死亡數。
設限
censoring
追蹤期間未觀察到事件,但後續狀態未知或研究結束的情形。
存活時間資料
time-to-event data
同時包含事件是否發生與事件或設限時間的資料。
Kaplan-Meier 曲線
Kaplan-Meier curve
估計無事件存活機率隨時間變化的曲線。
Log-rank 檢定
log-rank test
比較兩組或多組存活曲線的檢定。
危險率
hazard
某時間點尚未發生事件者在下一瞬間發生事件的瞬時率。
重複事件
recurrent event
同一個體可能發生多次的事件。