本章學習目標
前面我們學過兩組平均值比較。可是醫學研究常常不只兩組:標準照護、飲食介入、藥物介入、合併介入;或低劑量、中劑量、高劑量;或三種病房、四種治療策略、五個年齡層。當組別變多,直接做很多次兩兩 t 檢定會讓第一型錯誤率一路升高,像是一直抽獎券,遲早抽到一張看起來很顯著的。
多樣本推論 (multisample inference) 的核心問題是:三組以上的母群體平均值是否有差異?最常見的方法是一因子變異數分析 (one-way analysis of variance, one-way ANOVA)。ANOVA 先回答「是否至少有一組不同」,再視需要進行事後比較 (post hoc comparison) 找出差異在哪裡。
讀完本章後,你應該能夠:
- 說明為什麼三組以上比較不宜只做多次 t 檢定。
- 解釋 one-way ANOVA 的研究問題、虛無假設與 F 統計量。
- 檢查 ANOVA 的基本假設,包括獨立性、常態性與變異數同質性。
- 使用 Levene test 評估變異數同質性。
- 使用事後比較與 Bonferroni correction 控制多重比較。
- 報告效果大小,例如 eta-squared。
- 認識二因子設計與交互作用 (interaction) 的基本直覺。
為什麼不要一直做 t 檢定?
假設有四組介入,每次兩兩比較共有 6 次 t 檢定。如果每次檢定都使用 \(\alpha = 0.05\),整體出現至少一個偽陽性的機率會超過 0.05。這稱為多重比較問題 (multiple comparisons problem)。
ANOVA 的做法是先用一個整體檢定檢查所有組平均值是否完全相同。若整體檢定沒有顯著證據,通常不急著進行大量兩兩比較。若整體檢定顯著,再根據研究問題做事後比較,並使用校正方法控制錯誤率。
One-way ANOVA 的基本想法
One-way ANOVA 比較三組以上獨立樣本的平均值。虛無假設是:
\[
H_0: \mu_1 = \mu_2 = \cdots = \mu_k
\]
對立假設則是至少有一組平均值不同。ANOVA 使用 F 統計量 (F statistic),概念上比較「組間變異」與「組內變異」。如果組間差異相對於組內雜訊很大,F 值會變大,p 值會變小。
ANOVA 的常見假設包括:
- 各觀察值彼此獨立。
- 各組資料大致來自常態分布。
- 各組變異數大致相同,也稱變異數同質性 (homogeneity of variance)。
常態性在每組樣本數適中時通常有一定穩健性,但獨立性很重要,不能靠樣本數救回來。若同一位病人被重複測量,應考慮 repeated measures ANOVA 或混合模型,而不是把資料當成獨立樣本。
範例資料:四種介入後的收縮壓
假設高血壓門診比較四種 12 週介入後的收縮壓:標準照護、飲食介入、藥物介入、合併介入。每組 24 位病人。
standard = np.random.normal(148, 10, 24)
diet = np.random.normal(140, 11, 24)
drug = np.random.normal(134, 10, 24)
combo = np.random.normal(128, 9, 24)
sbp_df = pd.DataFrame(
{
"sbp": np.r_[standard, diet, drug, combo],
"group": ["標準照護"] * len(standard)
+ ["飲食介入"] * len(diet)
+ ["藥物介入"] * len(drug)
+ ["合併介入"] * len(combo),
}
)
sbp_df.groupby("group")["sbp"].agg(["count", "mean", "std"]).round(2)
| group |
|
|
|
| 合併介入 |
24 |
127.98 |
9.71 |
| 標準照護 |
24 |
147.33 |
8.85 |
| 藥物介入 |
24 |
129.36 |
11.23 |
| 飲食介入 |
24 |
139.37 |
13.77 |
plt.figure(figsize=(8, 4.8))
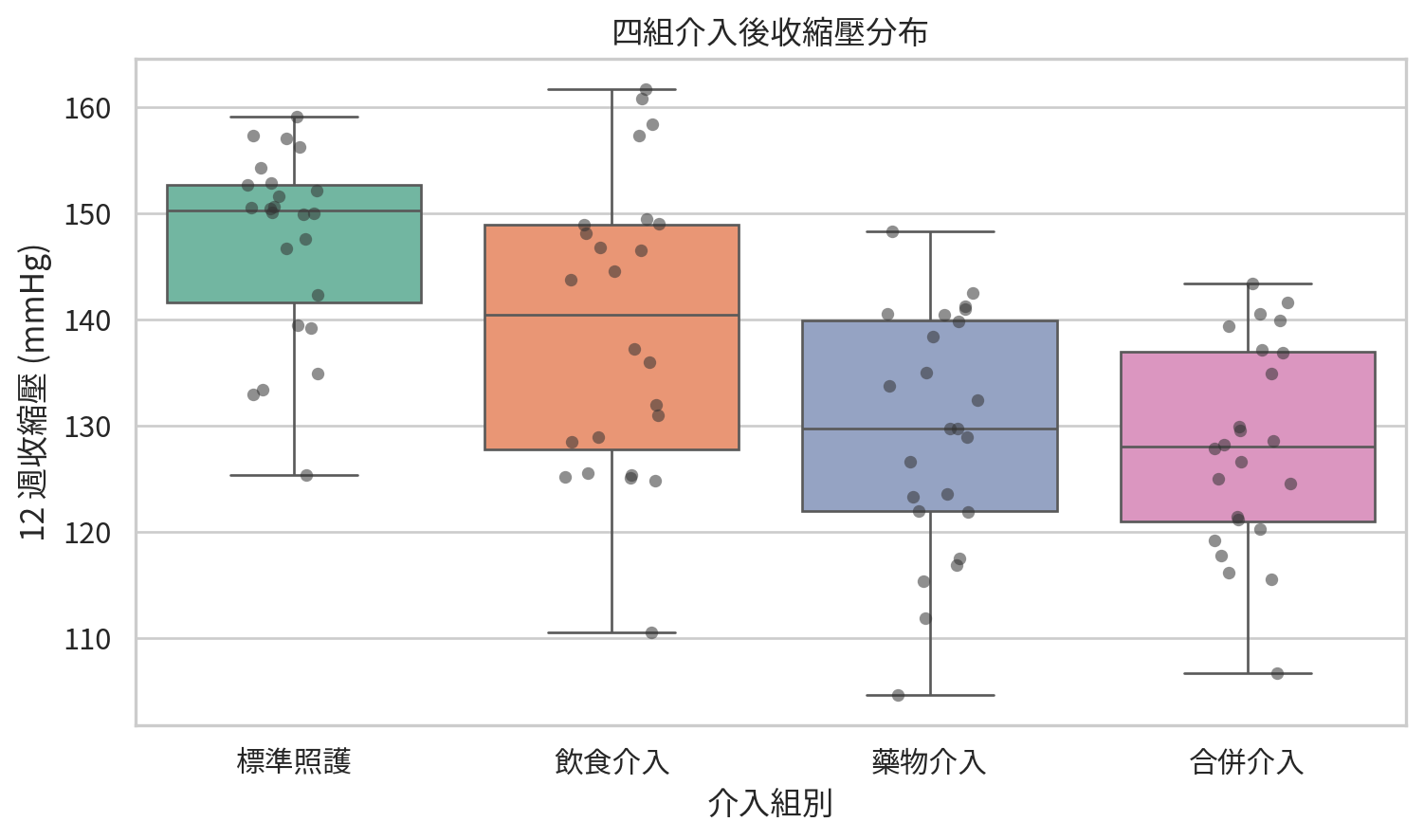
sns.boxplot(data=sbp_df, x="group", y="sbp", hue="group", palette="Set2", legend=False)
sns.stripplot(data=sbp_df, x="group", y="sbp", color="#333333", alpha=0.55, jitter=0.15)
plt.xlabel("介入組別")
plt.ylabel("12 週收縮壓 (mmHg)")
plt.title("四組介入後收縮壓分布")
plt.tight_layout()
plt.savefig(FIG_DIR / "ch12_anova_sbp_groups.png", dpi=300)
plt.show()
圖形比 p 值更早說話。這張圖讓我們先看見合併介入組平均收縮壓較低,但各組之間仍有重疊。ANOVA 會協助我們評估這樣的組間差異是否大到超過組內變異能合理解釋的程度。
執行 one-way ANOVA
anova_result = f_oneway(standard, diet, drug, combo)
pd.DataFrame(
{
"quantity": ["F 統計量", "p 值"],
"value": [anova_result.statistic, anova_result.pvalue],
}
).round(4)
| 0 |
F 統計量 |
16.2537 |
| 1 |
p 值 |
0.0000 |
若 ANOVA p 值很小,表示至少有一組平均值不同。但它不會告訴你是哪一組與哪一組不同。這很像值班醫師說「病房有狀況」,但還沒告訴你是哪一床。
各組平均值與信賴區間
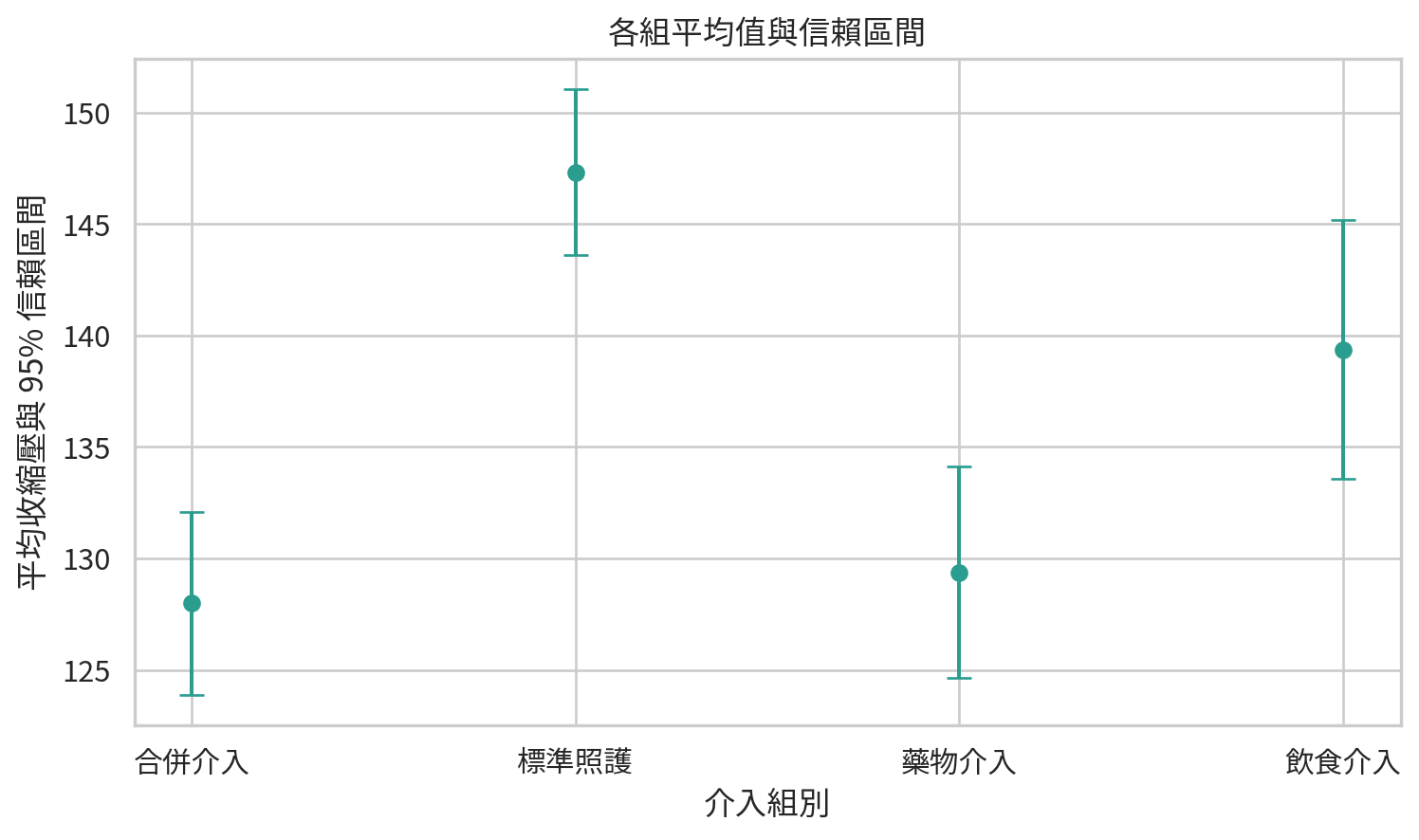
除了整體檢定,我們也應報告各組平均值與信賴區間。這比只報 p 值更能呈現臨床差異大小。
def mean_ci(values):
values = np.asarray(values, dtype=float)
n = len(values)
mean = values.mean()
se = values.std(ddof=1) / np.sqrt(n)
margin = t.ppf(0.975, df=n - 1) * se
return mean, mean - margin, mean + margin
summary_rows = []
for group_name, values in sbp_df.groupby("group")["sbp"]:
mean, lower, upper = mean_ci(values)
summary_rows.append({"group": group_name, "mean": mean, "lower": lower, "upper": upper})
summary_df = pd.DataFrame(summary_rows)
summary_df.round(2)
| 0 |
合併介入 |
127.98 |
123.88 |
132.08 |
| 1 |
標準照護 |
147.33 |
143.59 |
151.07 |
| 2 |
藥物介入 |
129.36 |
124.62 |
134.11 |
| 3 |
飲食介入 |
139.37 |
133.55 |
145.18 |
plt.figure(figsize=(8, 4.8))
plt.errorbar(
summary_df["group"],
summary_df["mean"],
yerr=[summary_df["mean"] - summary_df["lower"], summary_df["upper"] - summary_df["mean"]],
fmt="o",
color="#2a9d8f",
capsize=5,
)
plt.xlabel("介入組別")
plt.ylabel("平均收縮壓與 95% 信賴區間")
plt.title("各組平均值與信賴區間")
plt.tight_layout()
plt.savefig(FIG_DIR / "ch12_group_means_ci.png", dpi=300)
plt.show()
變異數同質性與 Levene test
ANOVA 假設各組變異數相近。Levene test 可用來檢查變異數是否有明顯差異。它的虛無假設是各組變異數相同。
levene_result = levene(standard, diet, drug, combo)
pd.DataFrame(
{
"quantity": ["Levene 統計量", "p 值"],
"value": [levene_result.statistic, levene_result.pvalue],
}
).round(4)
| 0 |
Levene 統計量 |
3.3829 |
| 1 |
p 值 |
0.0215 |
若 Levene test p 值很小,代表變異數同質性可能不成立。此時可考慮 Welch ANOVA、資料轉換、穩健方法,或改用非參數方法如 Kruskal-Wallis。方法選擇要回到資料型態與研究問題,不是看到一個檢定顯著就立刻換整套人生。
效果大小:eta-squared
p 值受樣本數影響很大。多樣本比較最好同時報告效果大小。ANOVA 常用 eta-squared (\(\eta^2\)),表示總變異中有多少比例可由組別解釋。
def eta_squared(groups):
all_values = np.concatenate(groups)
grand_mean = all_values.mean()
ss_between = sum(len(group) * (group.mean() - grand_mean) ** 2 for group in groups)
ss_total = np.sum((all_values - grand_mean) ** 2)
return ss_between / ss_total
eta2 = eta_squared([standard, diet, drug, combo])
pd.DataFrame({"quantity": ["eta-squared"], "value": [eta2]}).round(4)
若 \(\eta^2 = 0.25\),可粗略解讀為組別解釋了結果總變異的 25%。這不是因果證明,但能幫助判斷組別差異是否有實質意義。
事後比較與 Bonferroni correction
ANOVA 顯著後,常見下一步是比較哪些組別不同。若有 4 組,兩兩比較共有 6 次。Bonferroni correction 的想法很直接:把每個 p 值乘以比較次數,或把顯著水準除以比較次數。
Bonferroni 方法保守,但容易理解。保守的意思是比較不容易宣稱顯著,代價是可能降低檢定力。
def pairwise_ttests(df, value_col, group_col):
groups = list(df[group_col].unique())
rows = []
n_tests = len(groups) * (len(groups) - 1) // 2
for i, group_a in enumerate(groups):
for group_b in groups[i + 1 :]:
values_a = df.loc[df[group_col] == group_a, value_col]
values_b = df.loc[df[group_col] == group_b, value_col]
result = ttest_ind(values_a, values_b, equal_var=True)
mean_diff = values_a.mean() - values_b.mean()
rows.append(
{
"comparison": f"{group_a} - {group_b}",
"mean_difference": mean_diff,
"raw_p": result.pvalue,
"bonferroni_p": min(result.pvalue * n_tests, 1.0),
}
)
return pd.DataFrame(rows)
posthoc_df = pairwise_ttests(sbp_df, "sbp", "group")
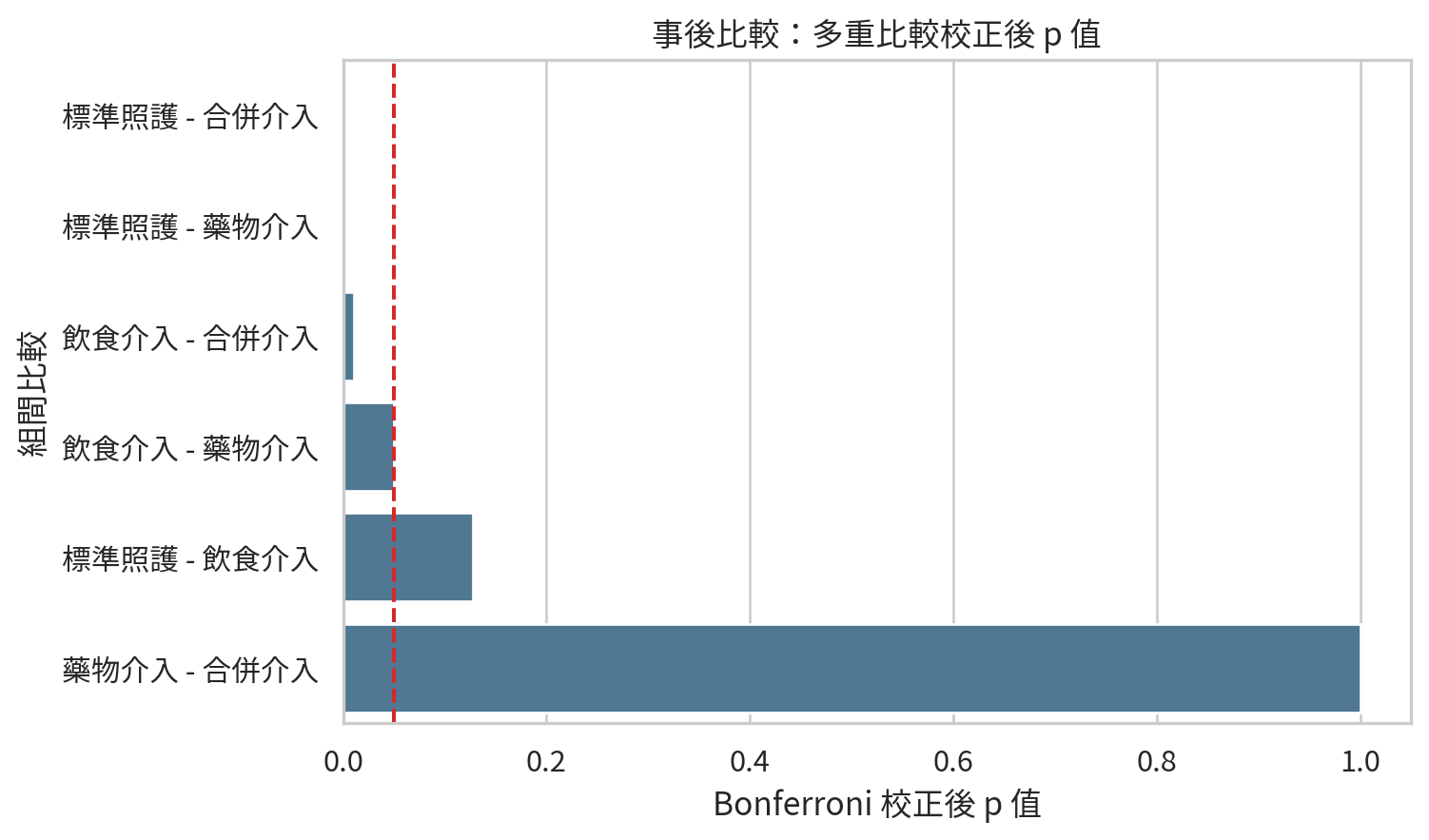
posthoc_df.round(4)
| 0 |
標準照護 - 飲食介入 |
7.9643 |
0.0213 |
0.1280 |
| 1 |
標準照護 - 藥物介入 |
17.9663 |
0.0000 |
0.0000 |
| 2 |
標準照護 - 合併介入 |
19.3507 |
0.0000 |
0.0000 |
| 3 |
飲食介入 - 藥物介入 |
10.0020 |
0.0083 |
0.0500 |
| 4 |
飲食介入 - 合併介入 |
11.3864 |
0.0018 |
0.0109 |
| 5 |
藥物介入 - 合併介入 |
1.3844 |
0.6500 |
1.0000 |
posthoc_plot = posthoc_df.sort_values("bonferroni_p")
plt.figure(figsize=(8, 4.8))
sns.barplot(data=posthoc_plot, x="bonferroni_p", y="comparison", color="#457b9d")
plt.axvline(0.05, color="#d62828", linestyle="--")
plt.xlabel("Bonferroni 校正後 p 值")
plt.ylabel("組間比較")
plt.title("事後比較:多重比較校正後 p 值")
plt.tight_layout()
plt.savefig(FIG_DIR / "ch12_posthoc_bonferroni.png", dpi=300)
plt.show()
Figure 12.3: 事後兩兩比較的 Bonferroni 校正後 p 值。紅線為 0.05。
事後比較要與研究問題相配。若研究一開始只關心「合併介入是否優於標準照護」,就不一定需要報告所有可能兩兩比較。統計表格不是越長越有學問,有時只是讓讀者在 p 值森林裡迷路。
二因子設計與交互作用
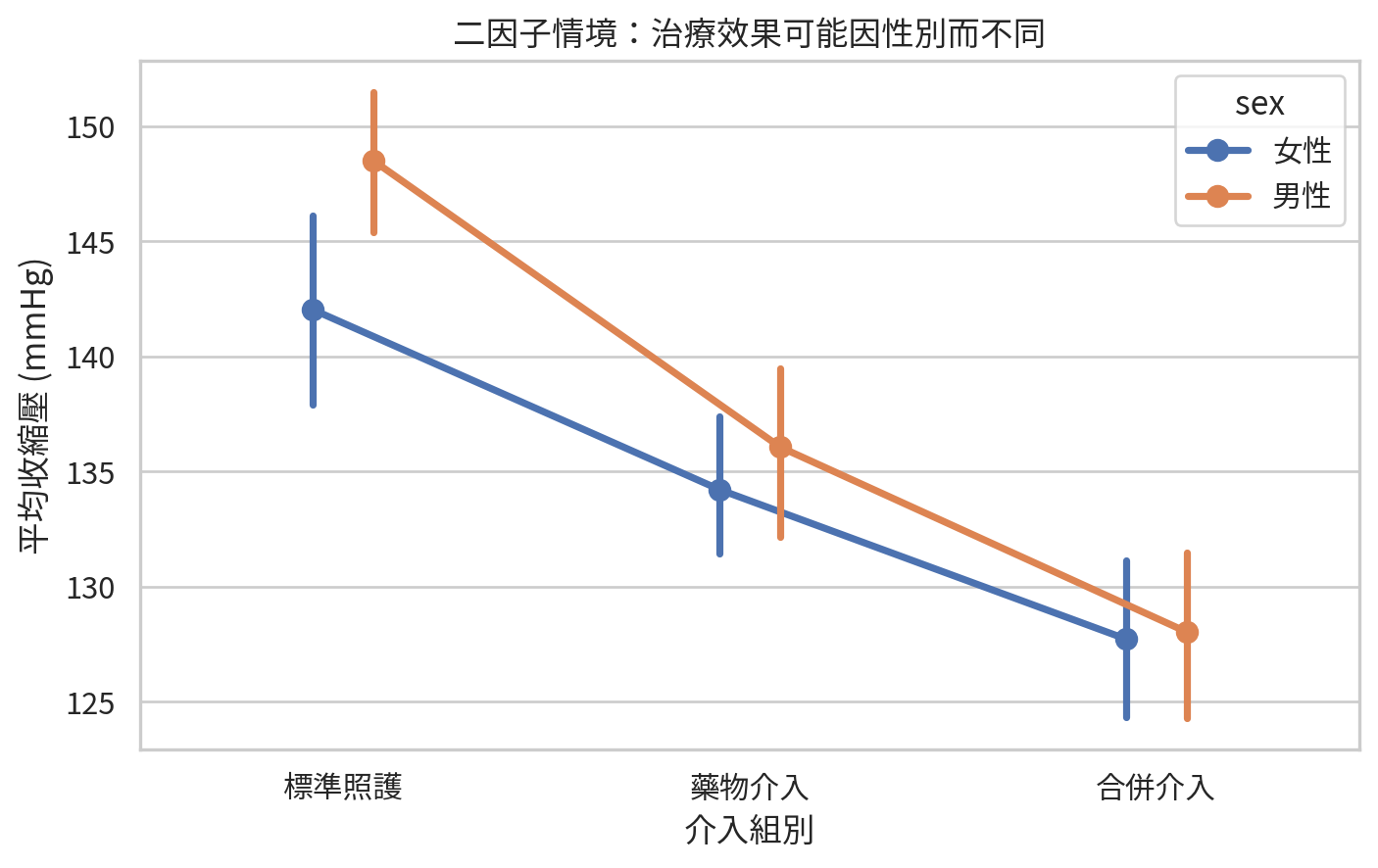
有些研究不只一個因子。例如同時考慮治療組別與性別,或劑量與年齡層。二因子 ANOVA (two-way ANOVA) 可同時評估兩個因子的主效應 (main effect),以及兩者是否有交互作用。
交互作用 (interaction) 的意思是:某個因子的效果會因另一個因子的水準而改變。例如合併介入對男性的降壓效果可能比女性更明顯。這不是說哪一性別「比較重要」,而是治療效果可能不完全一致。
sex_levels = ["女性", "男性"]
treat_levels = ["標準照護", "藥物介入", "合併介入"]
interaction_rows = []
for sex in sex_levels:
for treatment in treat_levels:
base = 146 if sex == "男性" else 142
effect = {"標準照護": 0, "藥物介入": -9, "合併介入": -15}[treatment]
interaction = -4 if (sex == "男性" and treatment == "合併介入") else 0
values = np.random.normal(base + effect + interaction, 8, 18)
for value in values:
interaction_rows.append({"sex": sex, "treatment": treatment, "sbp": value})
interaction_df = pd.DataFrame(interaction_rows)
interaction_df.head()
| 0 |
女性 |
標準照護 |
143.186819 |
| 1 |
女性 |
標準照護 |
134.493290 |
| 2 |
女性 |
標準照護 |
151.241545 |
| 3 |
女性 |
標準照護 |
134.688509 |
| 4 |
女性 |
標準照護 |
149.735668 |
plt.figure(figsize=(7.5, 4.8))
sns.pointplot(data=interaction_df, x="treatment", y="sbp", hue="sex", dodge=0.15, errorbar=("ci", 95))
plt.xlabel("介入組別")
plt.ylabel("平均收縮壓 (mmHg)")
plt.title("二因子情境:治療效果可能因性別而不同")
plt.tight_layout()
plt.savefig(FIG_DIR / "ch12_interaction_plot.png", dpi=300)
plt.show()
交互作用圖不是正式檢定,但非常有用。若線條接近平行,代表各組差異在不同性別中大致相似;若線條明顯不平行,表示可能存在交互作用,需要進一步用適當模型檢定。
何時改用非參數方法?
若資料明顯偏態、離群值很多、樣本數小,或結果是有序尺度,Kruskal-Wallis test 可能比 one-way ANOVA 更適合。這在 Chapter 9 已介紹過。
不過,Kruskal-Wallis 也不是單純「中位數 ANOVA」。它檢定的是各組排序分布是否相同。若分布形狀差很多,解釋仍要小心。選方法時要看研究問題、資料型態與分布,而不是把「常態不常態」當成唯一開關。
常見錯誤
第一個錯誤是三組以上直接做一堆 t 檢定,卻沒有多重比較校正。這會增加偽陽性風險。
第二個錯誤是 ANOVA 顯著後就說「所有組都不同」。ANOVA 只告訴我們至少有一組不同,不能直接指出是哪幾組。
第三個錯誤是只報告 p 值,不報告各組平均值、信賴區間與效果大小。沒有這些資訊,讀者很難判斷臨床意義。
第四個錯誤是忽略研究設計。獨立樣本 ANOVA 不適用於同一批人重複測量的資料。
第五個錯誤是看到交互作用圖線條交叉就立刻過度解讀。交互作用需要模型與檢定支持,也需要臨床合理性。
本章重點整理
多樣本推論處理三組以上的比較。One-way ANOVA 先檢定所有組平均值是否相同,若整體檢定顯著,再依研究問題進行事後比較。多重比較會增加第一型錯誤率,因此需要 Bonferroni、Tukey 或其他校正方法。報告 ANOVA 時,應同時呈現各組摘要、整體檢定、效果大小與事後比較。
當研究設計有兩個因子時,除了各因子的主效應,也要留意交互作用。臨床資料常常不只問「哪個治療比較好」,還會問「對誰比較好」。這時候模型就要跟著問題長大一點。
小練習
- 某研究比較三種止痛藥的疼痛分數下降量。請說明 one-way ANOVA 的虛無假設。
- 若 ANOVA p 值為 0.01,是否表示三組兩兩都不同?為什麼?
- 四組比較共有幾個兩兩比較?若使用 Bonferroni correction,單次比較的顯著水準是多少?
- 請解釋 eta-squared 的意義。
- 如果 Levene test 顯著,你會考慮哪些替代方法?
- 請畫出一個可能有交互作用的臨床情境,並用文字描述線條為何不平行。
Glossary
| 多樣本推論 |
multisample inference |
處理三組以上資料比較的推論方法。 |
| 變異數分析 |
analysis of variance, ANOVA |
比較多組平均值是否相同的統計方法。 |
| 單因子變異數分析 |
one-way ANOVA |
只有一個分組因子的 ANOVA。 |
| F 統計量 |
F statistic |
ANOVA 中用於比較組間變異與組內變異的統計量。 |
| 組間變異 |
between-group variation |
不同組平均值之間的變異。 |
| 組內變異 |
within-group variation |
同一組內個體之間的變異。 |
| 變異數同質性 |
homogeneity of variance |
各組變異數大致相同的假設。 |
| Levene 檢定 |
Levene test |
檢定各組變異數是否相同的方法。 |
| 事後比較 |
post hoc comparison |
整體檢定後進行的組間比較。 |
| 多重比較問題 |
multiple comparisons problem |
多次檢定增加偽陽性機率的問題。 |
| Bonferroni 校正 |
Bonferroni correction |
以校正顯著水準或 p 值控制多重比較的保守方法。 |
| Eta-squared |
eta-squared |
ANOVA 中表示組別解釋總變異比例的效果大小。 |
| 主效應 |
main effect |
某一因子平均而言對結果的影響。 |
| 交互作用 |
interaction |
某一因子的效果會因另一因子的水準而改變。 |