本章學習目標
前面幾章我們常常處理平均值:血壓平均下降多少、LDL-C 平均差多少、住院天數平均是否改變。不過醫學研究裡有很多問題不是連續數值,而是「有或沒有」、「陽性或陰性」、「死亡或存活」、「接種或未接種」。
這些資料稱為類別資料 (categorical data)。如果類別只有兩種,例如是否再住院,就稱為二元資料 (binary data)。處理這類資料時,我們關心的通常是比例 (proportion)、風險 (risk)、勝算 (odds),以及不同組別之間是否有關聯。
讀完本章後,你應該能夠:
- 區分類別資料、二元資料與有序類別資料。
- 使用單一比例檢定 (one-sample proportion test) 與兩比例 z 檢定 (two-proportion z test)。
- 使用卡方獨立性檢定 (chi-square test of independence) 分析列聯表。
- 在小樣本或稀有事件時使用 Fisher exact test。
- 使用 McNemar test 分析配對二元資料。
- 對有序類別資料進行趨勢檢定 (trend test)。
- 報告類別資料分析時同時呈現效果大小與 p 值。
類別資料的基本語言
類別資料的第一個重點是計數。假設 420 位對照組病人中有 52 位發生不良事件,這不是平均值問題,而是「52/420」這個比例是否太高、是否和另一組不同。
常見的量包括:
- 風險 (risk):事件發生人數除以總人數。例如 52/420。
- 勝算 (odds):事件發生人數除以未發生人數。例如 52/368。
- 風險差 (risk difference):兩組風險相減。
- 相對風險 (relative risk):兩組風險相除。
- 勝算比 (odds ratio):兩組勝算相除。
風險比較直覺,勝算比在病例對照研究與 logistic regression 中很常見。剛開始學時,先不要把 odds ratio 自動解讀成 relative risk;事件常見時,兩者可以差很多。統計不怕你慢慢來,怕的是我們太快把它們當成同一個東西。
單一比例檢定
單一比例檢定用於檢查某個樣本比例是否與一個已知或假設比例不同。例如某醫院過去 30 天再住院率為 12%,新的照護計畫後觀察到 200 位出院病人中有 18 位再住院。研究者想問:新的再住院率是否低於 12%?
在 Python 中,可使用二項檢定 (binomial test)。它直接根據二項分布計算 p 值,對小樣本也很合適。
readmit_events = 18
readmit_total = 200
historical_rate = 0.12
one_prop_result = binomtest(readmit_events, readmit_total, p=historical_rate, alternative="less")
pd.DataFrame(
{
"quantity": ["觀察再住院率", "歷史再住院率", "單尾 p 值"],
"value": [readmit_events / readmit_total, historical_rate, one_prop_result.pvalue],
}
).round(4)
| 0 |
觀察再住院率 |
0.0900 |
| 1 |
歷史再住院率 |
0.1200 |
| 2 |
單尾 p 值 |
0.1129 |
這裡的虛無假設是再住院率等於 12%,對立假設是再住院率低於 12%。如果研究者事前沒有方向性假設,應使用雙尾檢定。
兩比例 z 檢定
兩比例 z 檢定用於比較兩個獨立組別的比例。它依賴常態近似,因此各組事件與非事件數不宜太小。若格子數很小,後面會介紹 Fisher exact test。
範例 1:疫苗組不良事件比例是否較低?
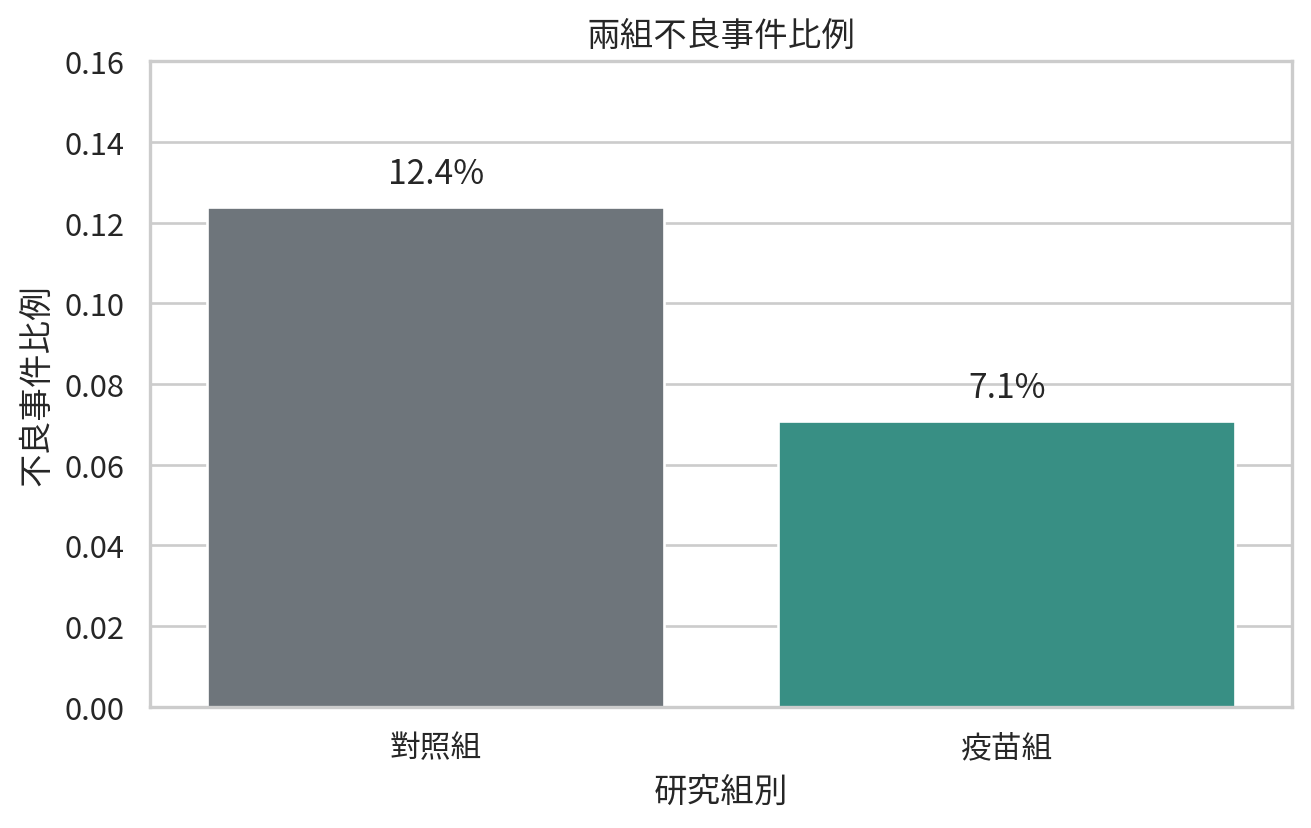
假設一項研究比較疫苗組與對照組的不良事件比例。對照組 420 人中有 52 人發生不良事件;疫苗組 438 人中有 31 人發生不良事件。
control_events, control_total = 52, 420
vaccine_events, vaccine_total = 31, 438
prop_df = pd.DataFrame(
{
"group": ["對照組", "疫苗組"],
"events": [control_events, vaccine_events],
"total": [control_total, vaccine_total],
}
)
prop_df["risk"] = prop_df["events"] / prop_df["total"]
prop_df
| 0 |
對照組 |
52 |
420 |
0.123810 |
| 1 |
疫苗組 |
31 |
438 |
0.070776 |
plt.figure(figsize=(7, 4.5))
sns.barplot(data=prop_df, x="group", y="risk", hue="group", palette=["#6c757d", "#2a9d8f"], legend=False)
for index, row in prop_df.iterrows():
plt.text(index, row["risk"] + 0.004, f"{row['risk']:.1%}", ha="center", va="bottom")
plt.ylim(0, 0.16)
plt.xlabel("研究組別")
plt.ylabel("不良事件比例")
plt.title("兩組不良事件比例")
plt.tight_layout()
plt.savefig(FIG_DIR / "ch10_two_proportion_adverse_events.png", dpi=300)
plt.show()
def two_proportion_z_test(success_a, total_a, success_b, total_b):
p_a = success_a / total_a
p_b = success_b / total_b
pooled = (success_a + success_b) / (total_a + total_b)
se = np.sqrt(pooled * (1 - pooled) * (1 / total_a + 1 / total_b))
z_stat = (p_a - p_b) / se
p_value = 2 * (1 - norm.cdf(abs(z_stat)))
return z_stat, p_value, p_a - p_b
z_stat, p_value, risk_difference = two_proportion_z_test(
vaccine_events, vaccine_total, control_events, control_total
)
pd.DataFrame(
{
"quantity": ["疫苗組風險", "對照組風險", "風險差", "z 統計量", "雙尾 p 值"],
"value": [vaccine_events / vaccine_total, control_events / control_total, risk_difference, z_stat, p_value],
}
).round(4)
| 0 |
疫苗組風險 |
0.0708 |
| 1 |
對照組風險 |
0.1238 |
| 2 |
風險差 |
-0.0530 |
| 3 |
z 統計量 |
-2.6270 |
| 4 |
雙尾 p 值 |
0.0086 |
p 值回答的是「若兩組真實比例相同,看到這麼極端或更極端資料的機率有多大」。但臨床判讀還需要看風險差。若風險差是 -5.3 個百分點,這比單看 p 值更接近病人與決策者真正關心的問題。
列聯表與卡方獨立性檢定
當兩個變項都是類別資料,可以放進列聯表 (contingency table)。例如「病房別」與「是否有跌倒風險」。
卡方獨立性檢定的虛無假設是兩個類別變項互相獨立。換句話說,跌倒風險比例不會因病房不同而不同。
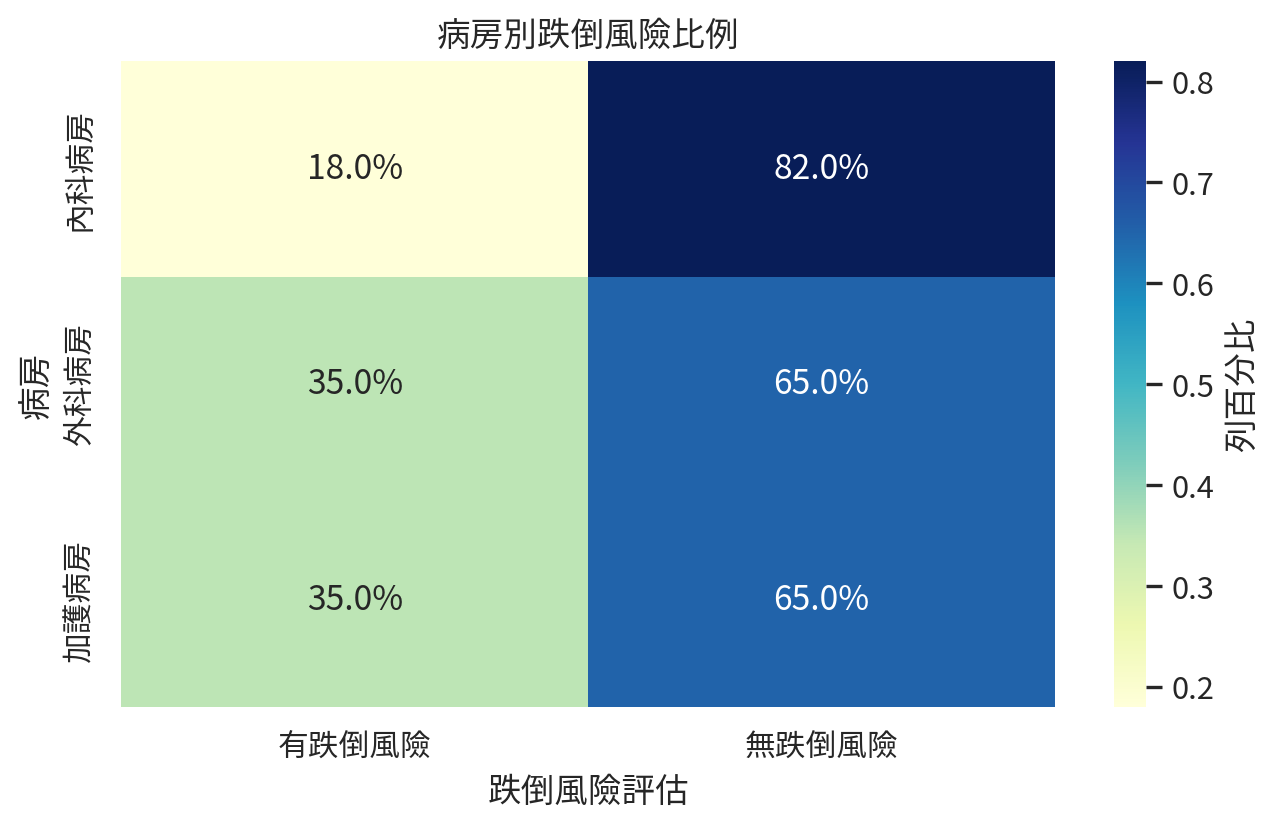
範例 2:病房別跌倒風險是否不同?
ward_table = pd.DataFrame(
[[18, 82], [35, 65], [28, 52]],
index=["內科病房", "外科病房", "加護病房"],
columns=["有跌倒風險", "無跌倒風險"],
)
ward_table
| 內科病房 |
18 |
82 |
| 外科病房 |
35 |
65 |
| 加護病房 |
28 |
52 |
ward_percent = ward_table.div(ward_table.sum(axis=1), axis=0)
plt.figure(figsize=(7, 4.5))
sns.heatmap(ward_percent, annot=True, fmt=".1%", cmap="YlGnBu", cbar_kws={"label": "列百分比"})
plt.xlabel("跌倒風險評估")
plt.ylabel("病房")
plt.title("病房別跌倒風險比例")
plt.tight_layout()
plt.savefig(FIG_DIR / "ch10_chisquare_fallrisk_heatmap.png", dpi=300)
plt.show()
chi2_stat, chi2_p, chi2_dof, expected = chi2_contingency(ward_table)
pd.DataFrame(
{
"quantity": ["卡方統計量", "自由度", "p 值"],
"value": [chi2_stat, chi2_dof, chi2_p],
}
).round(4)
| 0 |
卡方統計量 |
9.0363 |
| 1 |
自由度 |
2.0000 |
| 2 |
p 值 |
0.0109 |
pd.DataFrame(expected, index=ward_table.index, columns=ward_table.columns).round(2)
| 內科病房 |
28.93 |
71.07 |
| 外科病房 |
28.93 |
71.07 |
| 加護病房 |
23.14 |
56.86 |
卡方檢定的一個重要檢查是期望次數 (expected count)。若期望次數太小,卡方近似可能不穩。常見經驗法則是大多數期望次數應至少 5;若 2x2 表中格子很小,Fisher exact test 通常更合適。
Fisher exact test:小樣本與稀有事件
Fisher exact test 不依賴大樣本卡方近似,常用於 2x2 表,特別是事件很少的情境。它的計算較保守,但在小樣本時讓人睡得比較安穩。
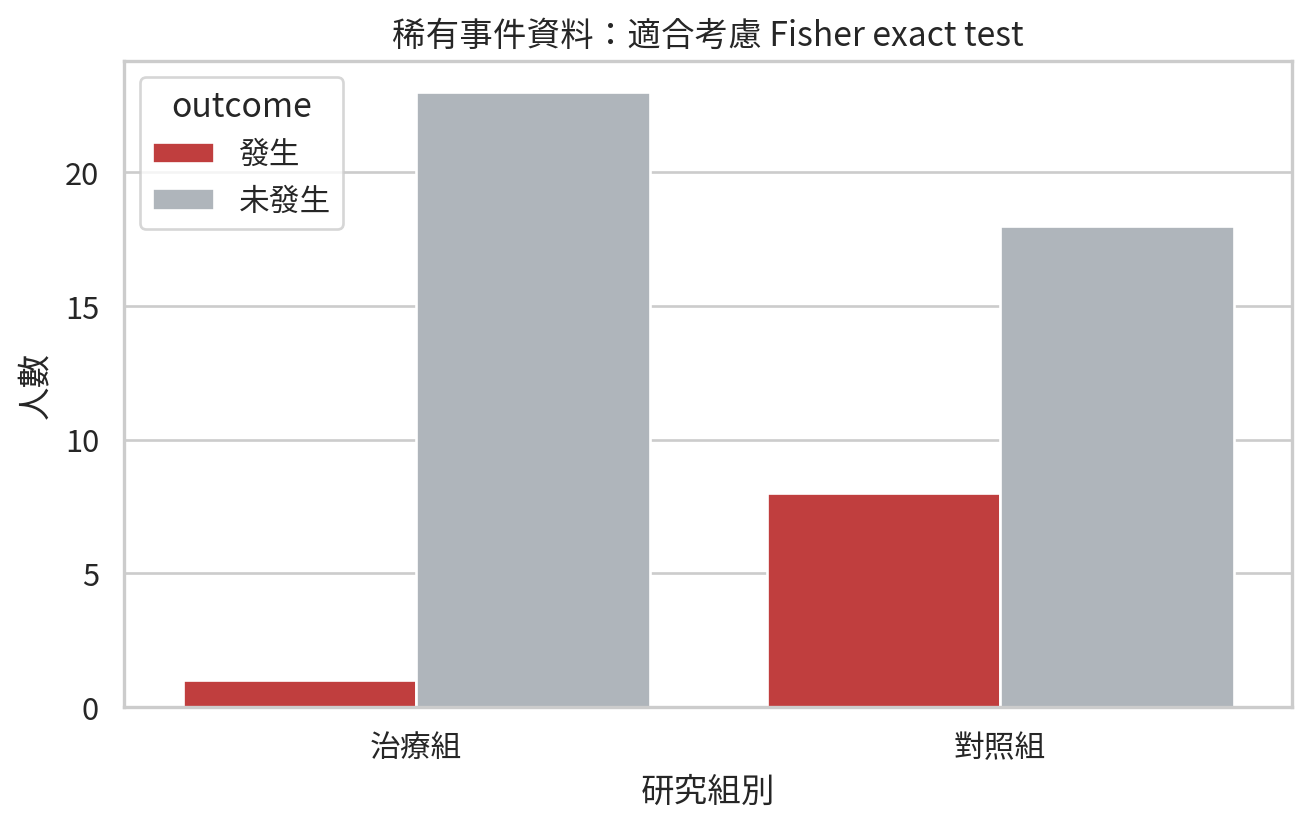
範例 3:稀有嚴重不良事件
rare_table = np.array([[1, 23], [8, 18]])
rare_df = pd.DataFrame(
{
"group": ["治療組", "治療組", "對照組", "對照組"],
"outcome": ["發生", "未發生", "發生", "未發生"],
"count": rare_table.ravel(),
}
)
pd.DataFrame(rare_table, index=["治療組", "對照組"], columns=["發生", "未發生"])
plt.figure(figsize=(7, 4.5))
sns.barplot(data=rare_df, x="group", y="count", hue="outcome", palette=["#d62828", "#adb5bd"])
plt.xlabel("研究組別")
plt.ylabel("人數")
plt.title("稀有事件資料:適合考慮 Fisher exact test")
plt.tight_layout()
plt.savefig(FIG_DIR / "ch10_fisher_rare_event_counts.png", dpi=300)
plt.show()
odds_ratio, fisher_p = fisher_exact(rare_table)
pd.DataFrame(
{
"quantity": ["勝算比", "雙尾 p 值"],
"value": [odds_ratio, fisher_p],
}
).round(4)
| 0 |
勝算比 |
0.0978 |
| 1 |
雙尾 p 值 |
0.0244 |
Fisher exact test 在 Python 的 scipy.stats.fisher_exact() 中會回傳勝算比與 p 值。若要正式報告,建議再加上勝算比信賴區間;本章先把重點放在檢定選擇與列聯表判讀。
McNemar test:配對二元資料
有些二元資料不是兩組獨立樣本,而是同一批人被測量兩次,或同一批檢體接受兩種檢測。例如同一批病人同時使用舊篩檢工具與新篩檢工具。這時不能用一般兩比例檢定,因為觀察值彼此配對。
McNemar test 的重點只看不一致的配對。若舊工具陽性新工具陰性的人數,和舊工具陰性新工具陽性的人數差很多,代表兩工具陽性率可能不同。
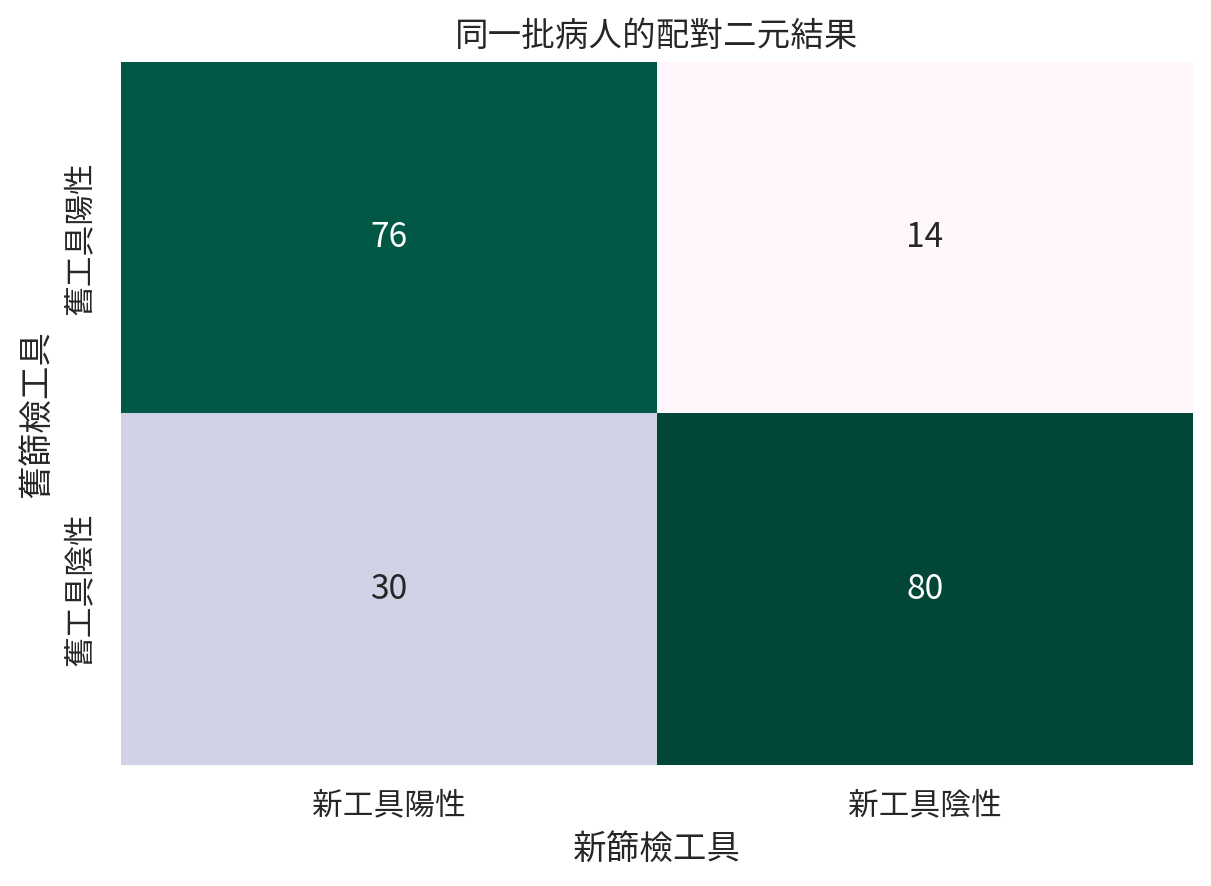
範例 4:新舊篩檢工具是否不同?
screen_table = np.array([[76, 14], [30, 80]])
screen_df = pd.DataFrame(screen_table, index=["舊工具陽性", "舊工具陰性"], columns=["新工具陽性", "新工具陰性"])
screen_df
plt.figure(figsize=(6.5, 4.8))
sns.heatmap(screen_df, annot=True, fmt="d", cmap="PuBuGn", cbar=False)
plt.xlabel("新篩檢工具")
plt.ylabel("舊篩檢工具")
plt.title("同一批病人的配對二元結果")
plt.tight_layout()
plt.savefig(FIG_DIR / "ch10_mcnemar_screening_pairs.png", dpi=300)
plt.show()
old_positive_new_negative = screen_table[0, 1]
old_negative_new_positive = screen_table[1, 0]
discordant_total = old_positive_new_negative + old_negative_new_positive
mcnemar_p = binomtest(
min(old_positive_new_negative, old_negative_new_positive),
discordant_total,
p=0.5,
).pvalue
pd.DataFrame(
{
"quantity": ["舊陽性新陰性", "舊陰性新陽性", "不一致配對總數", "exact McNemar p 值"],
"value": [old_positive_new_negative, old_negative_new_positive, discordant_total, mcnemar_p],
}
).round(4)
| 0 |
舊陽性新陰性 |
14.0000 |
| 1 |
舊陰性新陽性 |
30.0000 |
| 2 |
不一致配對總數 |
44.0000 |
| 3 |
exact McNemar p 值 |
0.0226 |
這裡用精確二項檢定實作 exact McNemar test。直覺是:在沒有差異的情況下,不一致配對應該差不多一半倒向舊工具、一半倒向新工具。
有序類別與趨勢檢定
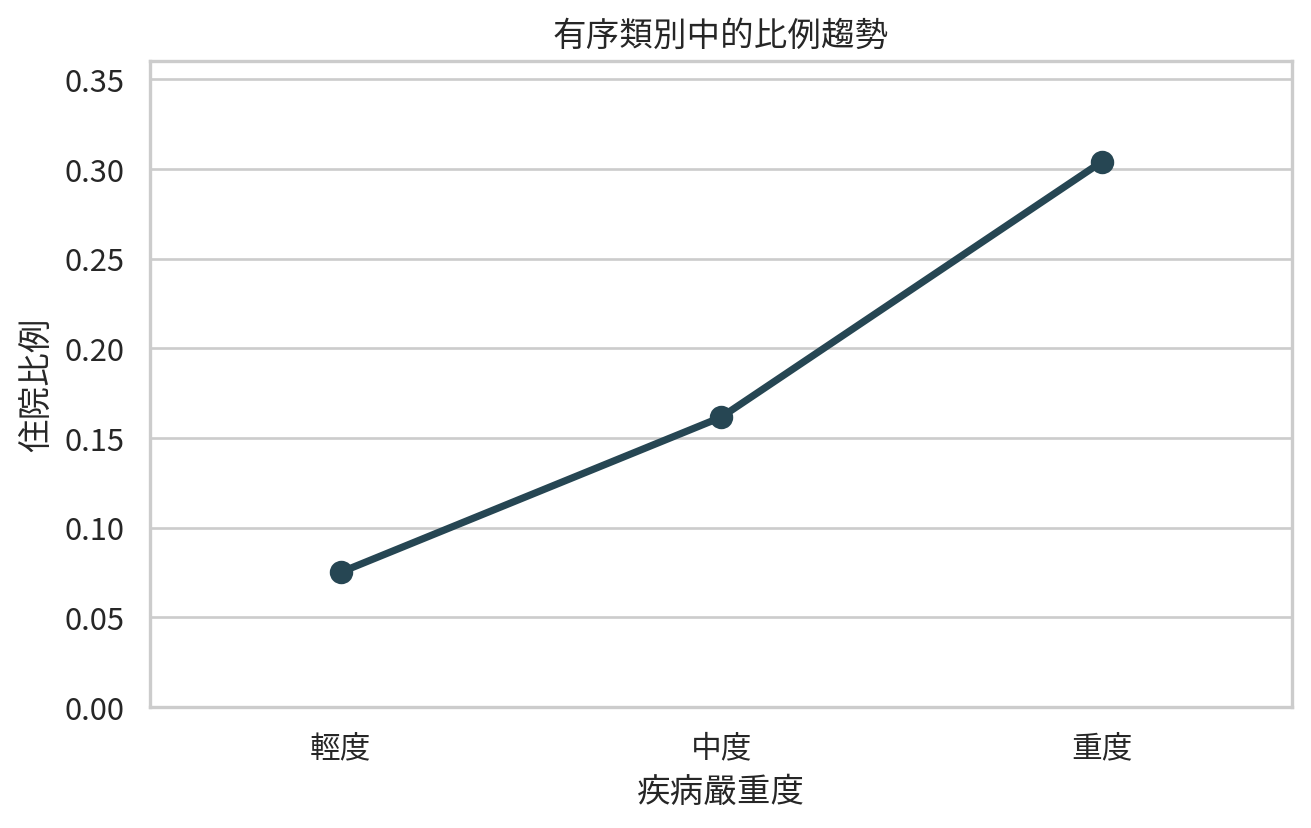
有些類別不是單純名目類別,而是有順序的,例如輕度、中度、重度。若結果是二元事件,可以問:事件比例是否隨類別順序增加或下降?
這類問題可使用 Cochran-Armitage trend test。Python 標準科學套件中沒有固定入口函數,但可直接依照統計量公式計算。
範例 5:疾病嚴重度與住院比例
severity_df = pd.DataFrame(
{
"severity": ["輕度", "中度", "重度"],
"score": [1, 2, 3],
"events": [9, 21, 38],
"total": [120, 130, 125],
}
)
severity_df["risk"] = severity_df["events"] / severity_df["total"]
severity_df
| 0 |
輕度 |
1 |
9 |
120 |
0.075000 |
| 1 |
中度 |
2 |
21 |
130 |
0.161538 |
| 2 |
重度 |
3 |
38 |
125 |
0.304000 |
plt.figure(figsize=(7, 4.5))
sns.pointplot(data=severity_df, x="severity", y="risk", color="#264653")
plt.xlabel("疾病嚴重度")
plt.ylabel("住院比例")
plt.ylim(0, 0.36)
plt.title("有序類別中的比例趨勢")
plt.tight_layout()
plt.savefig(FIG_DIR / "ch10_trend_test_ordered_groups.png", dpi=300)
plt.show()
def cochran_armitage_trend(successes, totals, scores):
successes = np.asarray(successes, dtype=float)
totals = np.asarray(totals, dtype=float)
scores = np.asarray(scores, dtype=float)
p_pool = successes.sum() / totals.sum()
score_bar = np.sum(totals * scores) / totals.sum()
numerator = np.sum(scores * (successes - totals * p_pool))
denominator = np.sqrt(p_pool * (1 - p_pool) * np.sum(totals * (scores - score_bar) ** 2))
z_stat = numerator / denominator
p_value = 2 * (1 - norm.cdf(abs(z_stat)))
return z_stat, p_value
trend_z, trend_p = cochran_armitage_trend(
severity_df["events"],
severity_df["total"],
severity_df["score"],
)
pd.DataFrame(
{
"quantity": ["趨勢 z 統計量", "雙尾 p 值"],
"value": [trend_z, trend_p],
}
).round(4)
| 0 |
趨勢 z 統計量 |
4.6589 |
| 1 |
雙尾 p 值 |
0.0000 |
趨勢檢定比一般卡方檢定更聚焦:它不是只問「三組是否有任何差異」,而是問「是否有隨順序上升或下降的線性趨勢」。當研究假設本來就有方向與順序時,這個問題更貼近臨床直覺。
常見錯誤
第一個錯誤是把配對資料當獨立資料。若同一位病人前後測、同一檢體做兩種檢測,就應考慮配對方法,例如 McNemar test。
第二個錯誤是只報告 p 值,不報告比例與效果大小。類別資料的效果大小可以是風險差、相對風險或勝算比。沒有這些數字,讀者很難知道差異是否有臨床意義。
第三個錯誤是小格子硬用卡方檢定。若事件很少,卡方近似可能不可靠。此時 Fisher exact test 或精確方法通常較合適。
第四個錯誤是忽略有序類別的順序。輕度、中度、重度不是三個任意標籤;若研究問題關心趨勢,應使用能保留順序資訊的方法。
本章重點整理
類別資料分析從計數開始。單一比例檢定處理一組比例與假設值的比較;兩比例 z 檢定處理兩個獨立比例的比較;卡方檢定處理兩個類別變項的關聯;Fisher exact test 適合小樣本 2x2 表;McNemar test 適合配對二元資料;趨勢檢定適合有序類別中的比例變化。
最好的報告方式不是「p = 0.03,所以有差」。比較成熟的寫法是:「疫苗組不良事件比例為 7.1%,對照組為 12.4%,風險差為 -5.3 個百分點,雙尾 p 值為 …」。數字一多,故事反而更清楚。
小練習
- 某篩檢計畫 300 人中有 42 人陽性。請檢定陽性率是否高於歷史值 10%。
- A 藥 180 人中有 24 人發生副作用,B 藥 175 人中有 39 人發生副作用。請計算兩組副作用比例、風險差與兩比例 z 檢定。
- 某研究有 3 個年齡層與是否接種疫苗的列聯表。你會用什麼檢定?若年齡層有明確順序,還能問什麼更聚焦的問題?
- 同一批 160 位病人使用兩種診斷工具,其中舊陽性新陰性為 18 人,舊陰性新陽性為 33 人。請用 exact McNemar test 判斷兩工具陽性率是否不同。
- 請解釋為什麼稀有事件資料不宜只依賴卡方近似。
Glossary
| 類別資料 |
categorical data |
以類別而非連續數值表示的資料。 |
| 二元資料 |
binary data |
只有兩種結果的類別資料,例如是/否、陽性/陰性。 |
| 比例 |
proportion |
事件人數除以總人數。 |
| 風險 |
risk |
特定時間或情境下事件發生的機率或比例。 |
| 勝算 |
odds |
事件發生人數與未發生人數的比。 |
| 風險差 |
risk difference |
兩組風險相減。 |
| 相對風險 |
relative risk |
兩組風險相除。 |
| 勝算比 |
odds ratio |
兩組勝算相除。 |
| 列聯表 |
contingency table |
呈現兩個類別變項交叉計數的表格。 |
| 卡方獨立性檢定 |
chi-square test of independence |
檢定兩個類別變項是否獨立的方法。 |
| 期望次數 |
expected count |
虛無假設下,每個列聯表格子預期的計數。 |
| Fisher 精確檢定 |
Fisher exact test |
用於 2x2 表的小樣本精確檢定。 |
| McNemar 檢定 |
McNemar test |
用於配對二元資料的檢定。 |
| 趨勢檢定 |
trend test |
檢定有序類別中事件比例是否呈現上升或下降趨勢的方法。 |