本章學習目標
前面幾章我們學會比較一組、兩組或多組資料,也學會處理比例與類別資料。本章開始處理另一種常見問題:兩個或多個變項是否一起變動?如果 BMI 較高,HbA1c 是否也較高?如果調整年齡與身體活動後,BMI 與 HbA1c 的關係還在嗎?
相關 (correlation) 用來描述兩個變項一起變動的方向與強度。迴歸 (regression) 則進一步建立一個模型,用一個或多個解釋變項來描述或預測結果變項。相關像是說「兩個人常一起出現」,迴歸則會多問一句:「其中一個增加一單位,另一個平均會改變多少?」
讀完本章後,你應該能夠:
- 解釋 Pearson correlation 與 Spearman rank correlation 的差異。
- 使用散佈圖 (scatter plot) 檢查兩個連續變項的關係。
- 建立簡單線性迴歸 (simple linear regression) 並解讀斜率。
- 理解截距、斜率、殘差與 \(R^2\) 的意義。
- 建立多變項線性迴歸 (multiple linear regression) 並解讀調整後係數。
- 使用殘差圖檢查線性迴歸的基本假設。
- 區分解釋、預測與因果推論。
相關不等於迴歸
相關係數 (correlation coefficient) 通常介於 -1 到 1。正值代表一個變項增加時,另一個也傾向增加;負值代表一個增加時,另一個傾向下降;接近 0 則表示線性或單調關係不明顯。
Pearson correlation 衡量線性關係,適合兩個連續變項且關係大致呈直線。Spearman rank correlation 則先把資料轉成排序,再衡量單調關係,對離群值與非線性但單調的關係較穩健。
相關係數有兩個重要提醒。第一,相關不代表因果。第二,相關係數只是一個摘要,不能取代圖。醫學資料很會在散佈圖裡藏劇情,單一數字常常只講了預告片。
範例資料:BMI、年齡、活動量與 HbA1c
我們建立一組糖尿病門診資料,包含年齡、BMI、身體活動分數與 HbA1c。這是模擬資料,但設計成接近臨床教學會遇到的情境。
n = 48
age = np.random.normal(58, 9, n).round(0)
bmi = np.random.normal(27, 4, n).round(1)
activity = np.clip(np.random.normal(5.5, 2.2, n), 1, 10).round(1)
hba1c = 5.2 + 0.045 * age + 0.085 * bmi - 0.18 * activity + np.random.normal(0, 0.45, n)
diabetes_df = pd.DataFrame(
{
"age": age,
"bmi": bmi,
"activity": activity,
"hba1c": np.round(hba1c, 2),
}
)
diabetes_df.head()
| 0 |
60.0 |
18.1 |
5.2 |
7.85 |
| 1 |
61.0 |
28.8 |
4.7 |
9.98 |
| 2 |
58.0 |
25.0 |
2.3 |
9.32 |
| 3 |
60.0 |
29.8 |
7.2 |
8.96 |
| 4 |
66.0 |
29.9 |
1.0 |
10.92 |
diabetes_df.describe().round(2)
| count |
48.00 |
48.00 |
48.00 |
48.00 |
| mean |
57.48 |
26.07 |
5.59 |
8.99 |
| std |
9.61 |
4.46 |
2.22 |
0.91 |
| min |
34.00 |
15.30 |
1.00 |
6.89 |
| 25% |
49.75 |
22.78 |
3.95 |
8.36 |
| 50% |
60.00 |
26.40 |
5.55 |
8.98 |
| 75% |
64.25 |
29.65 |
7.20 |
9.32 |
| max |
76.00 |
33.80 |
10.00 |
11.04 |
Pearson 與 Spearman 相關
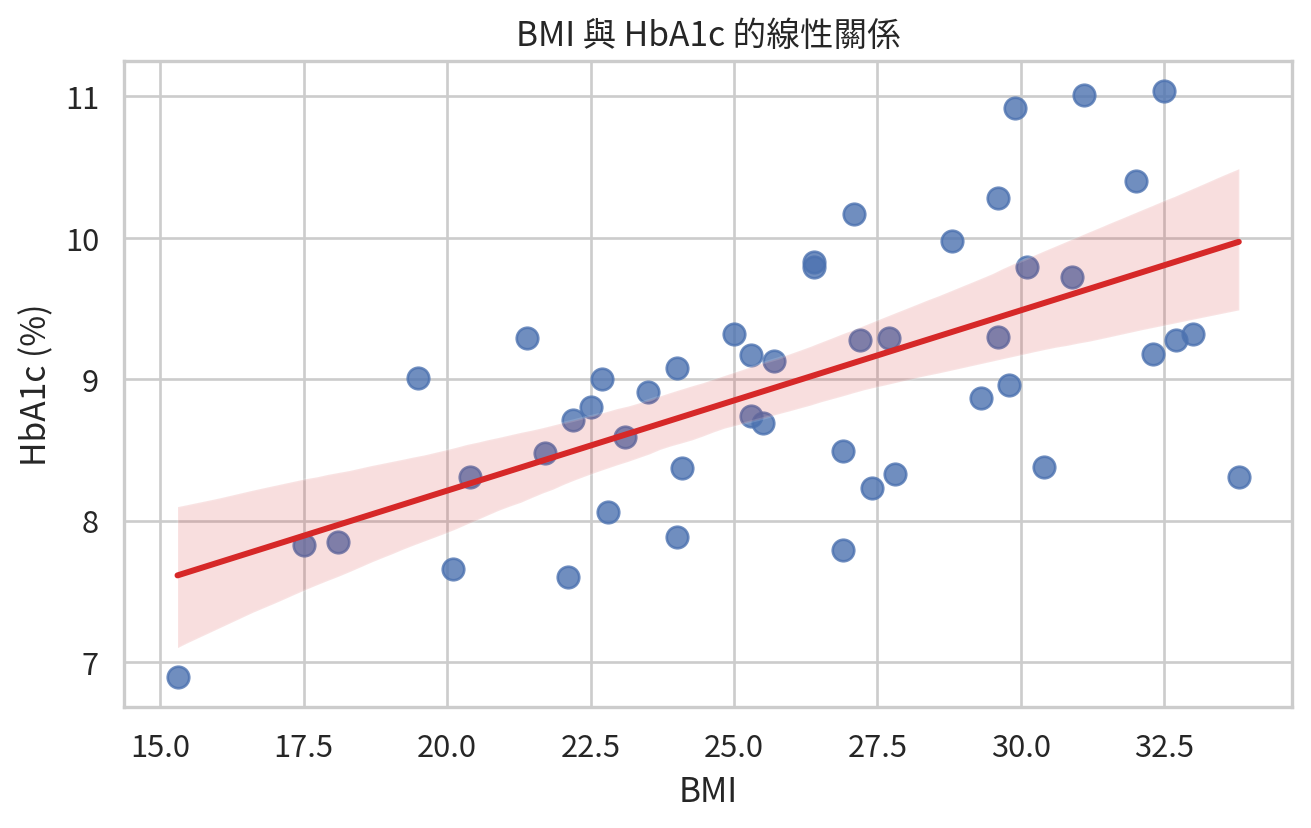
先看 BMI 與 HbA1c 的關係。散佈圖是第一步,相關係數是第二步。順序不要反過來;資料視覺化是臨床統計的聽診器。
plt.figure(figsize=(7, 4.5))
sns.regplot(data=diabetes_df, x="bmi", y="hba1c", scatter_kws={"s": 65}, line_kws={"color": "#d62828"})
plt.xlabel("BMI")
plt.ylabel("HbA1c (%)")
plt.title("BMI 與 HbA1c 的線性關係")
plt.tight_layout()
plt.savefig(FIG_DIR / "ch11_bmi_hba1c_regression.png", dpi=300)
plt.show()
pearson_result = pearsonr(diabetes_df["bmi"], diabetes_df["hba1c"])
spearman_result = spearmanr(diabetes_df["bmi"], diabetes_df["hba1c"])
pd.DataFrame(
{
"method": ["Pearson correlation", "Spearman rank correlation"],
"estimate": [pearson_result.statistic, spearman_result.statistic],
"p_value": [pearson_result.pvalue, spearman_result.pvalue],
}
).round(4)
| 0 |
Pearson correlation |
0.6222 |
0.0 |
| 1 |
Spearman rank correlation |
0.5771 |
0.0 |
若 Pearson 與 Spearman 結果相近,通常表示關係大致線性且沒有被極端值嚴重支配。若兩者差很多,應回到散佈圖檢查是否有離群值、曲線關係或資料分群。
簡單線性迴歸
簡單線性迴歸用一個解釋變項 \(X\) 描述一個連續結果 \(Y\):
\[
Y_i = \beta_0 + \beta_1 X_i + \epsilon_i
\]
其中 \(\beta_0\) 是截距 (intercept),\(\beta_1\) 是斜率 (slope),\(\epsilon_i\) 是殘差 (residual)。在本例中,\(Y\) 是 HbA1c,\(X\) 是 BMI。斜率的解讀是:BMI 每增加 1 單位,HbA1c 平均改變多少百分點。
def fit_ols(y, x_df):
x = np.column_stack([np.ones(len(x_df)), x_df.to_numpy(dtype=float)])
y = np.asarray(y, dtype=float)
beta = np.linalg.lstsq(x, y, rcond=None)[0]
fitted = x @ beta
resid = y - fitted
n_obs, n_param = x.shape
sigma2 = np.sum(resid**2) / (n_obs - n_param)
cov_beta = sigma2 * np.linalg.inv(x.T @ x)
se = np.sqrt(np.diag(cov_beta))
t_stat = beta / se
p_value = 2 * (1 - t.cdf(np.abs(t_stat), df=n_obs - n_param))
r2 = 1 - np.sum(resid**2) / np.sum((y - y.mean()) ** 2)
return beta, se, t_stat, p_value, fitted, resid, r2
beta_simple, se_simple, t_simple, p_simple, fitted_simple, resid_simple, r2_simple = fit_ols(
diabetes_df["hba1c"], diabetes_df[["bmi"]]
)
simple_coef = pd.DataFrame(
{
"term": ["截距", "BMI"],
"estimate": beta_simple,
"se": se_simple,
"t": t_simple,
"p_value": p_simple,
}
)
simple_coef.round(4)
| 0 |
截距 |
5.6607 |
0.6255 |
9.0494 |
0.0 |
| 1 |
BMI |
0.1275 |
0.0237 |
5.3908 |
0.0 |
pd.DataFrame({"quantity": ["R-squared"], "value": [r2_simple]}).round(4)
\(R^2\) 表示模型解釋了結果變異的比例。例如 \(R^2 = 0.30\) 可解讀為此模型約解釋 HbA1c 變異的 30%。但 \(R^2\) 高不代表因果正確,\(R^2\) 低也不代表模型沒用。臨床研究裡,很多重要因素本來就只能解釋一小部分個體差異。
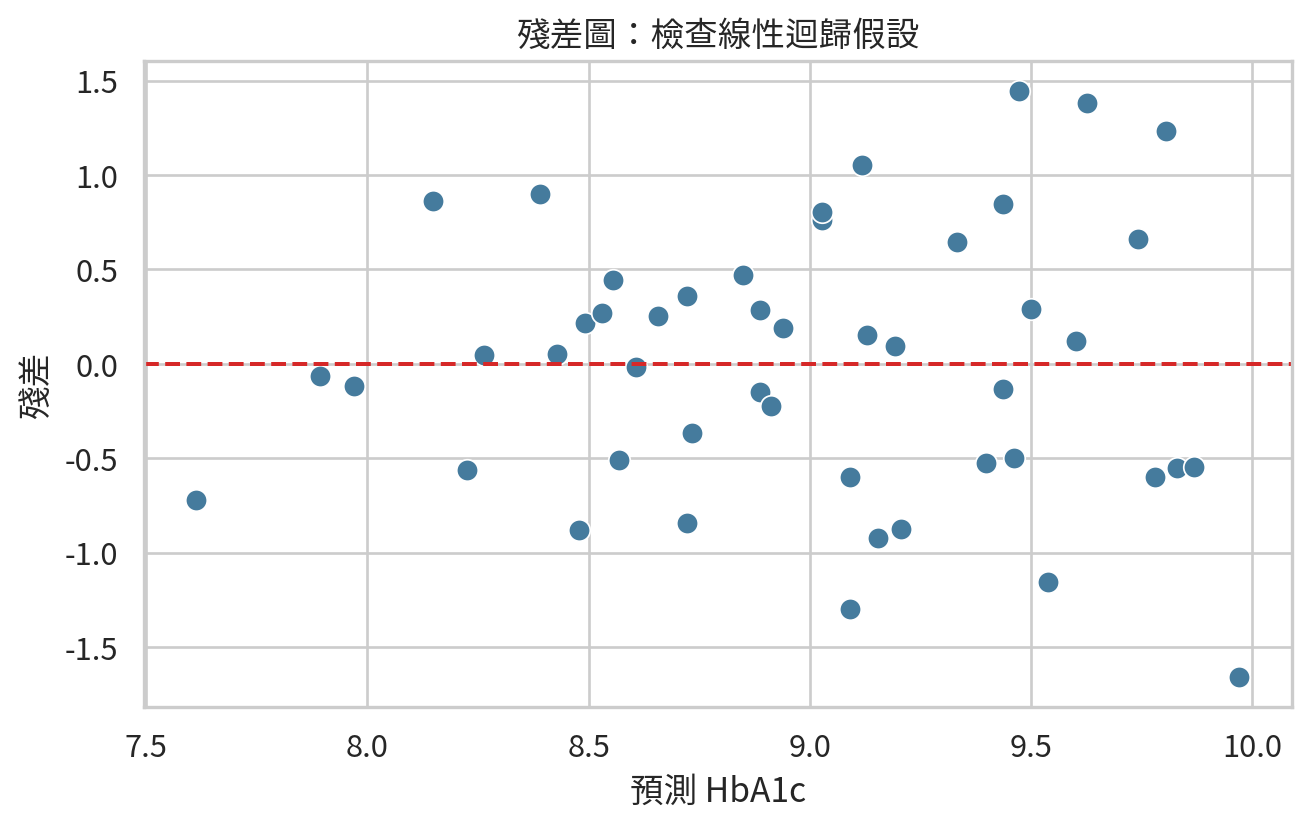
殘差與模型檢查
殘差是觀察值與模型預測值的差。線性迴歸常見假設包括線性、殘差變異大致相同、殘差近似常態,以及觀察值彼此獨立。
殘差圖是檢查模型的第一站。如果殘差圖出現彎曲形狀,表示線性模型可能漏掉非線性關係;如果殘差隨預測值變大而擴散,表示變異可能不等。
diabetes_df["fitted_simple"] = fitted_simple
diabetes_df["resid_simple"] = resid_simple
plt.figure(figsize=(7, 4.5))
sns.scatterplot(data=diabetes_df, x="fitted_simple", y="resid_simple", s=65, color="#457b9d")
plt.axhline(0, color="#d62828", linestyle="--")
plt.xlabel("預測 HbA1c")
plt.ylabel("殘差")
plt.title("殘差圖:檢查線性迴歸假設")
plt.tight_layout()
plt.savefig(FIG_DIR / "ch11_residuals_fitted.png", dpi=300)
plt.show()
多變項線性迴歸
簡單迴歸只看 BMI 與 HbA1c,但臨床上 BMI 不是孤島。年齡、身體活動、用藥、病程長短都可能影響 HbA1c。多變項線性迴歸可以同時放入多個解釋變項:
\[
Y_i = \beta_0 + \beta_1 X_{1i} + \beta_2 X_{2i} + \beta_3 X_{3i} + \epsilon_i
\]
在多變項模型中,BMI 係數的意思變成:在年齡與身體活動相同的情況下,BMI 每增加 1 單位,HbA1c 平均改變多少。這句「在其他變項相同的情況下」很重要,講太快就會滑倒。
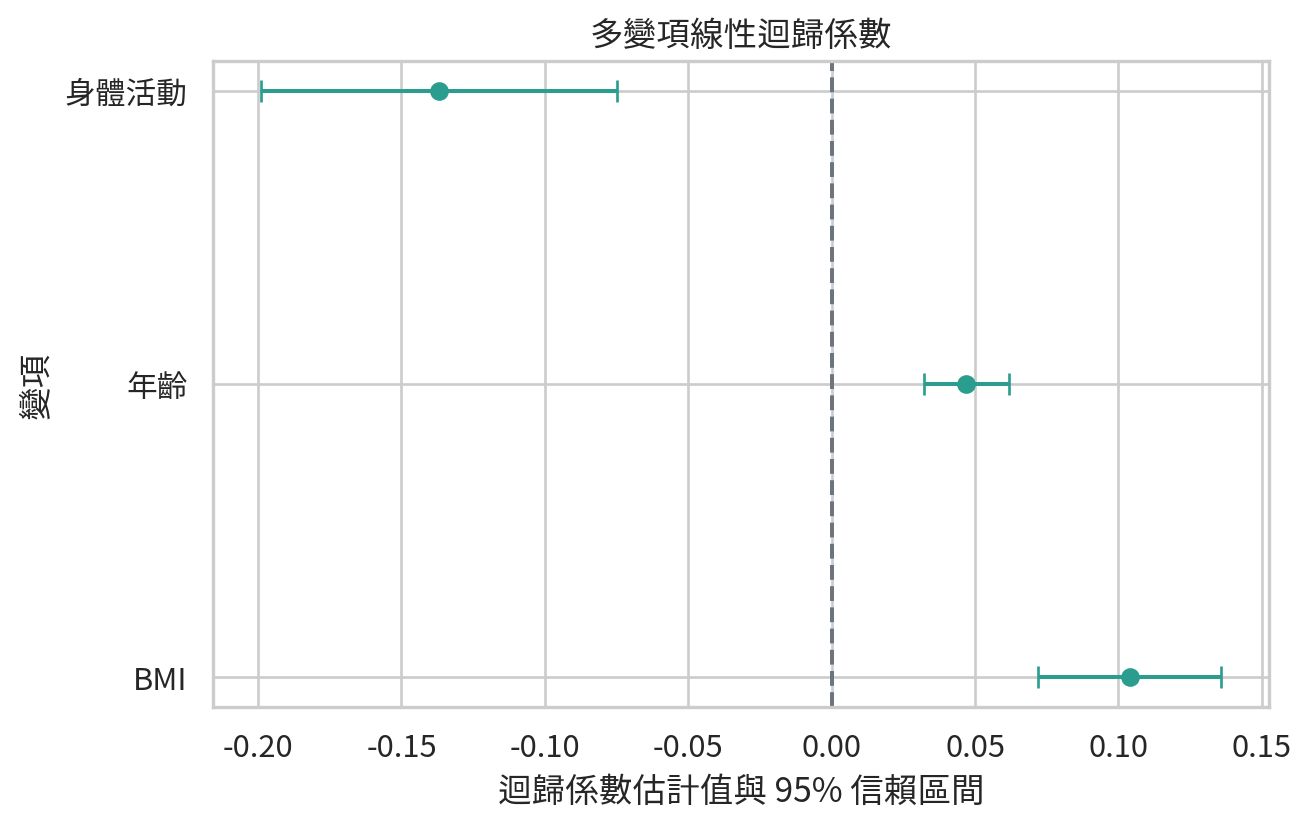
beta_multi, se_multi, t_multi, p_multi, fitted_multi, resid_multi, r2_multi = fit_ols(
diabetes_df["hba1c"], diabetes_df[["bmi", "age", "activity"]]
)
coef_df = pd.DataFrame(
{
"term": ["截距", "BMI", "年齡", "身體活動"],
"estimate": beta_multi,
"se": se_multi,
"t": t_multi,
"p_value": p_multi,
}
)
coef_df["lower"] = coef_df["estimate"] - 1.96 * coef_df["se"]
coef_df["upper"] = coef_df["estimate"] + 1.96 * coef_df["se"]
coef_df.round(4)
| 0 |
截距 |
4.3414 |
0.5606 |
7.7442 |
0.0000 |
3.2426 |
5.4402 |
| 1 |
BMI |
0.1039 |
0.0162 |
6.4142 |
0.0000 |
0.0721 |
0.1356 |
| 2 |
年齡 |
0.0470 |
0.0075 |
6.2519 |
0.0000 |
0.0323 |
0.0617 |
| 3 |
身體活動 |
-0.1369 |
0.0316 |
-4.3315 |
0.0001 |
-0.1989 |
-0.0750 |
plot_coef = coef_df.query("term != '截距'")
plt.figure(figsize=(7, 4.5))
plt.errorbar(plot_coef["estimate"], plot_coef["term"], xerr=1.96 * plot_coef["se"], fmt="o", color="#2a9d8f", capsize=4)
plt.axvline(0, color="#6c757d", linestyle="--")
plt.xlabel("迴歸係數估計值與 95% 信賴區間")
plt.ylabel("變項")
plt.title("多變項線性迴歸係數")
plt.tight_layout()
plt.savefig(FIG_DIR / "ch11_multiple_regression_coefficients.png", dpi=300)
plt.show()
pd.DataFrame({"quantity": ["Multiple regression R-squared"], "value": [r2_multi]}).round(4)
| 0 |
Multiple regression R-squared |
0.7419 |
多變項迴歸常用於調整混雜因子 (confounder)。但要小心,放進模型的變項不是越多越好。樣本數太小、變項太多,模型會變得不穩;如果放入中介變項或碰撞變項,也可能讓解釋偏掉。模型不是抽屜,不是什麼都塞進去就會變整齊。
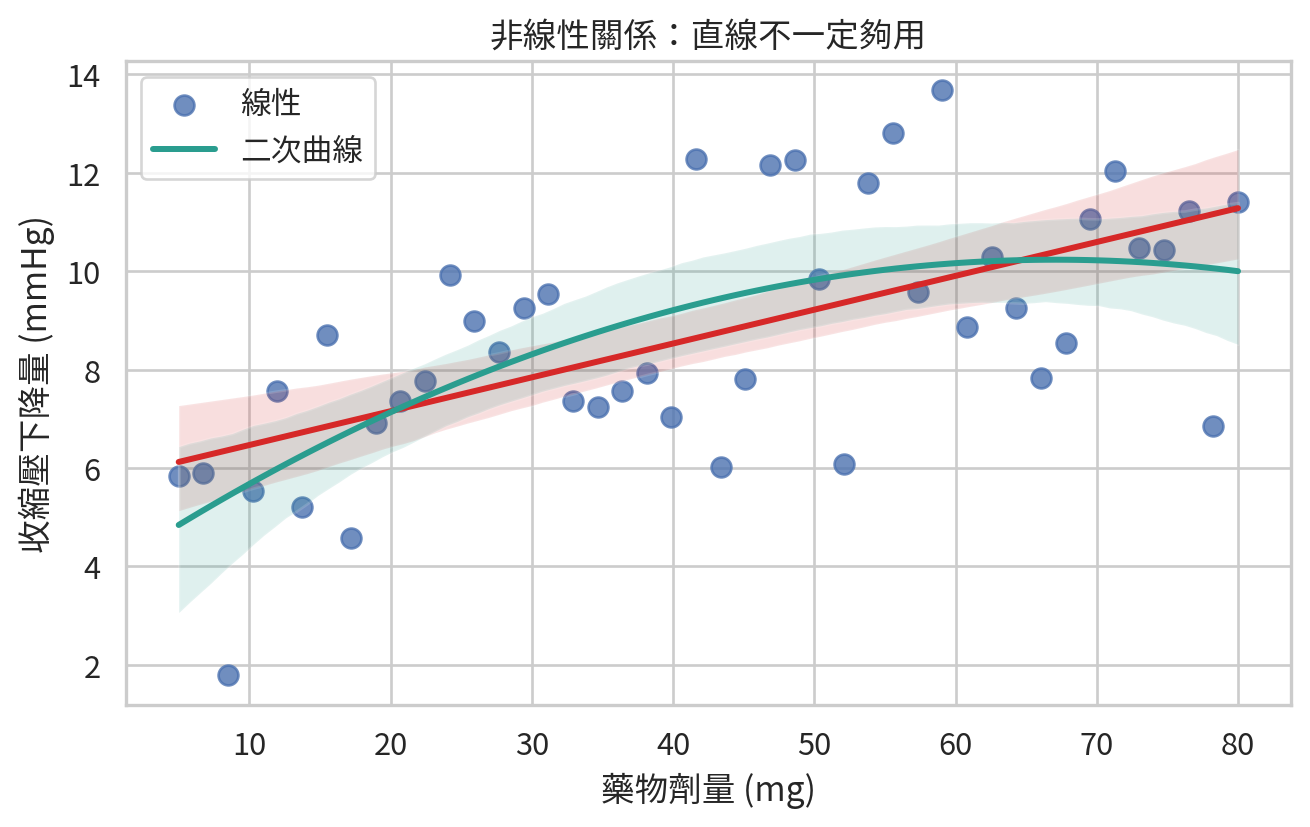
非線性關係
線性迴歸的「線性」指的是模型參數的線性,不表示所有醫學關係都真的是直線。劑量反應可能有平台期、U 型關係或閾值效應。若散佈圖顯示曲線,硬套直線會讓模型看起來很有紀律,但其實在裝鎮定。
med_n = 44
dose = np.linspace(5, 80, med_n)
sbp_drop = 3 + 0.22 * dose - 0.0018 * dose**2 + np.random.normal(0, 2.1, med_n)
dose_df = pd.DataFrame({"dose": dose, "sbp_drop": sbp_drop})
dose_df.head()
| 0 |
5.000000 |
5.837845 |
| 1 |
6.744186 |
5.907471 |
| 2 |
8.488372 |
1.783980 |
| 3 |
10.232558 |
5.535284 |
| 4 |
11.976744 |
7.565777 |
plt.figure(figsize=(7, 4.5))
sns.regplot(
data=dose_df,
x="dose",
y="sbp_drop",
order=1,
scatter_kws={"s": 55},
line_kws={"color": "#d62828"},
label="線性",
)
sns.regplot(
data=dose_df,
x="dose",
y="sbp_drop",
order=2,
scatter=False,
line_kws={"color": "#2a9d8f"},
label="二次曲線",
)
plt.xlabel("藥物劑量 (mg)")
plt.ylabel("收縮壓下降量 (mmHg)")
plt.title("非線性關係:直線不一定夠用")
plt.legend()
plt.tight_layout()
plt.savefig(FIG_DIR / "ch11_nonlinear_dose_response.png", dpi=300)
plt.show()
遇到非線性時,可考慮轉換變項、加入多項式項、使用 splines,或改用更適合的模型。重點不是追求複雜,而是讓模型尊重資料形狀。
解釋、預測與因果
迴歸可以服務不同目的。若目標是解釋,我們關心係數大小、方向與臨床意義。若目標是預測,我們關心模型對新病人的預測準確度。若目標是因果推論,就需要研究設計、時間順序、混雜控制與因果假設。
同一個迴歸表在不同目的下,解讀方式會不同。把預測模型的係數拿來當因果效果,或把因果模型拿來吹噓預測能力,都是常見的分析誤會。
常見錯誤
第一個錯誤是看到相關就說因果。BMI 與 HbA1c 相關,不代表單靠觀察資料就能證明 BMI 改變會導致 HbA1c 改變。
第二個錯誤是不看散佈圖。相關係數可能被離群值、非線性或分群資料誤導。
第三個錯誤是只報告 p 值,不報告係數與信賴區間。迴歸最有價值的是「每增加一單位,平均改變多少」。
第四個錯誤是把調整後係數解讀成「完全控制所有差異」。多變項迴歸只能調整模型中有放入、且測量品質足夠的變項。
第五個錯誤是忽略樣本數與模型複雜度。資料少、變項多,模型就容易不穩,信賴區間也會變寬。
本章重點整理
相關描述兩個變項一起變動的方向與強度;迴歸描述一個或多個解釋變項與結果變項之間的平均關係。Pearson correlation 適合線性關係,Spearman correlation 適合單調關係。簡單線性迴歸給出截距、斜率、殘差與 \(R^2\);多變項迴歸可以在模型內調整其他變項。
不論模型多漂亮,都要回到研究問題、資料圖形與臨床意義。迴歸不是把資料送進機器後自動吐出真理;它比較像一份很有用但需要人類監督的病歷摘要。
小練習
- 使用一組包含年齡與收縮壓的資料,畫散佈圖並計算 Pearson correlation。
- 若散佈圖呈現單調但非線性關係,你會選 Pearson 還是 Spearman?為什麼?
- 建立「LDL-C = 截距 + BMI」的簡單線性迴歸,解釋 BMI 係數。
- 在上述模型加入年齡與性別後,BMI 係數變小。請提出兩個可能原因。
- 殘差圖出現漏斗形狀時,可能代表什麼問題?
- 請用自己的話說明「預測模型表現好」與「模型係數有因果意義」為何不同。
Glossary
| 相關 |
correlation |
描述兩個變項一起變動方向與強度的統計概念。 |
| Pearson 相關 |
Pearson correlation |
衡量兩個連續變項線性關係的相關係數。 |
| Spearman 等級相關 |
Spearman rank correlation |
以排序衡量兩個變項單調關係的相關係數。 |
| 迴歸 |
regression |
用一個或多個解釋變項描述或預測結果變項的方法。 |
| 簡單線性迴歸 |
simple linear regression |
只有一個解釋變項的線性迴歸。 |
| 多變項線性迴歸 |
multiple linear regression |
包含多個解釋變項的線性迴歸。 |
| 截距 |
intercept |
解釋變項為 0 時,模型預測的結果值。 |
| 斜率 |
slope |
解釋變項增加一單位時,結果變項平均改變的量。 |
| 殘差 |
residual |
觀察值與模型預測值的差。 |
| \(R^2\) |
\(R^2\) |
模型解釋結果變異比例的摘要指標。 |
| 混雜因子 |
confounder |
同時與暴露及結果相關、可能扭曲關係估計的變項。 |
| 預測 |
prediction |
使用模型估計新觀察值的結果。 |
| 因果推論 |
causal inference |
評估某暴露或介入是否造成結果改變的推論框架。 |