本章學習目標
上一章我們學到機率是描述不確定性的語言。這一章要進一步問:如果隨機結果可以被「數出來」,它會遵守什麼樣的機率規律?例如 10 位病人中有幾位發生副作用、每小時急診來幾位發燒兒童、抽查 10 份病歷會抓到幾份用藥紀錄錯誤。這些問題都牽涉離散機率分布 (discrete probability distribution)。
讀完本章後,你應該能夠:
- 說明隨機變項 (random variable)、離散隨機變項 (discrete random variable)、機率質量函數 (probability mass function, PMF) 與累積分布函數 (cumulative distribution function, CDF)。
- 判斷二項分布 (binomial distribution) 的適用條件,並計算其平均值與變異數。
- 使用卜瓦松分布 (Poisson distribution) 描述單位時間或單位空間內的事件計數。
- 使用超幾何分布 (hypergeometric distribution) 描述有限母群體、不放回抽樣的成功次數。
- 使用幾何分布 (geometric distribution) 描述第一次成功前需要的試驗次數。
- 用 Python 3.14 與
scipy.stats 計算並視覺化離散機率分布。
從機率到機率分布
隨機變項 (random variable) 是把隨機結果轉成數值的規則。若某藥物可能造成噁心,我們可以定義 \(X\) 為「10 位用藥病人中發生噁心的人數」。\(X\) 可能是 0、1、2,一直到 10。因為 \(X\) 的可能值可以一個一個列出來,所以它是離散隨機變項。
離散機率分布描述每個可能值對應的機率。例如 \(P(X = 2)\) 表示 10 位病人中剛好 2 位發生噁心的機率。所有可能值的機率必須介於 0 與 1 之間,而且總和必須等於 1。這就像醫院排班:每個班別都要有人接,但總人力不能憑空多出來。
機率質量函數 (probability mass function, PMF) 給出離散隨機變項取特定值的機率:
\[
P(X = x)
\]
累積分布函數 (cumulative distribution function, CDF) 則給出隨機變項小於或等於某值的機率:
\[
F(x) = P(X \le x)
\]
在臨床研究中,PMF 適合問「剛好幾人發生事件」,CDF 適合問「至多幾人發生事件」或「至少幾人發生事件」。
二項分布:固定人數中的成功次數
二項分布 (binomial distribution) 描述固定次數、每次只有成功或失敗、且每次成功機率相同的情況。若 \(X\) 服從參數為 \(n\) 與 \(p\) 的二項分布,記作:
\[
X \sim \text{Binomial}(n, p)
\]
其中 \(n\) 是試驗次數,\(p\) 是每次成功機率。其 PMF 為:
\[
P(X = k) = {n \choose k}p^k(1-p)^{n-k}, \quad k = 0, 1, \ldots, n
\]
二項分布的平均值與變異數為:
\[
E(X) = np
\]
\[
\operatorname{Var}(X) = np(1-p)
\]
這裡的「成功」不一定是好事。在副作用研究中,成功可以代表「發生副作用」。統計的成功有時候很冷酷,像值班電話響起來一樣,不一定令人開心。
範例 1:10 位病人中有幾位發生副作用?
假設某藥物造成皮疹的機率為 20%。若門診連續追蹤 10 位使用此藥的病人,令 \(X\) 為發生皮疹的人數,則:
\[
X \sim \text{Binomial}(10, 0.20)
\]
n_patients = 10
p_rash = 0.20
binom_df = pd.DataFrame({"k": np.arange(0, n_patients + 1)})
binom_df["probability"] = binom.pmf(binom_df["k"], n=n_patients, p=p_rash)
binom_df["cumulative_probability"] = binom.cdf(binom_df["k"], n=n_patients, p=p_rash)
binom_df.round(4)
| 0 |
0 |
0.1074 |
0.1074 |
| 1 |
1 |
0.2684 |
0.3758 |
| 2 |
2 |
0.3020 |
0.6778 |
| 3 |
3 |
0.2013 |
0.8791 |
| 4 |
4 |
0.0881 |
0.9672 |
| 5 |
5 |
0.0264 |
0.9936 |
| 6 |
6 |
0.0055 |
0.9991 |
| 7 |
7 |
0.0008 |
0.9999 |
| 8 |
8 |
0.0001 |
1.0000 |
| 9 |
9 |
0.0000 |
1.0000 |
| 10 |
10 |
0.0000 |
1.0000 |
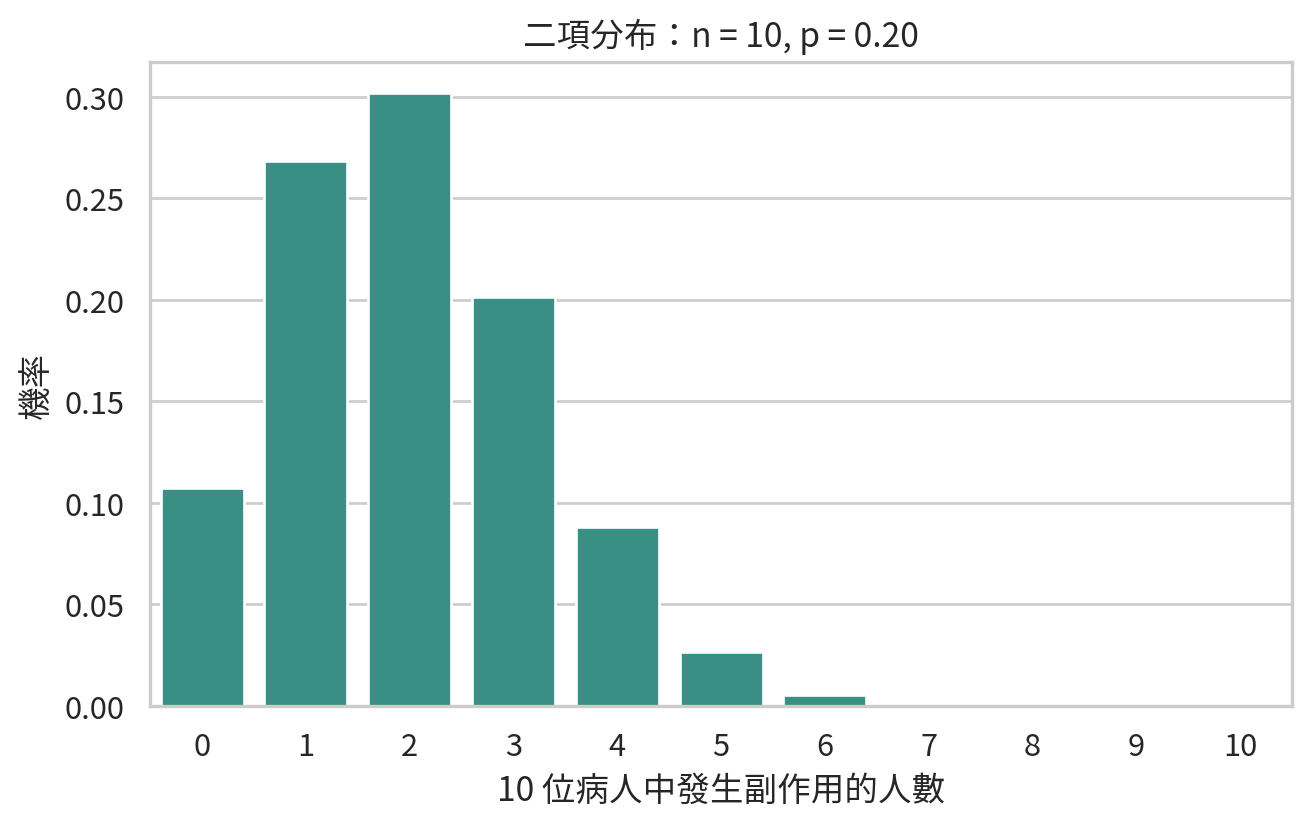
plt.figure(figsize=(7, 4.5))
sns.barplot(data=binom_df, x="k", y="probability", color="#2a9d8f")
plt.xlabel("10 位病人中發生副作用的人數")
plt.ylabel("機率")
plt.title("二項分布:n = 10, p = 0.20")
plt.tight_layout()
plt.savefig(FIG_DIR / "ch04_binomial_adverse_events.png", dpi=300)
plt.show()
這張圖顯示最可能的結果大約落在 1 到 3 人。平均發生人數為 \(np = 10 \times 0.20 = 2\)。但請注意,平均值是長期平均,不代表每 10 位病人都剛好 2 位發生皮疹。
若想知道「至少 3 位發生皮疹」的機率,可用:
\[
P(X \ge 3) = 1 - P(X \le 2)
\]
p_at_least_3 = 1 - binom.cdf(2, n=n_patients, p=p_rash)
p_exactly_2 = binom.pmf(2, n=n_patients, p=p_rash)
pd.DataFrame(
{
"問題": ["剛好 2 位發生皮疹", "至少 3 位發生皮疹"],
"機率": [p_exactly_2, p_at_least_3],
}
).round(4)
| 0 |
剛好 2 位發生皮疹 |
0.3020 |
| 1 |
至少 3 位發生皮疹 |
0.3222 |
二項分布的適用條件
使用二項分布前,請檢查四個條件:
- 試驗次數固定。
- 每次試驗只有兩種結果,例如發生或未發生。
- 每次成功機率相同。
- 各次試驗相互獨立。
醫療資料常常會挑戰這些條件。例如同一病房病人可能接受相似照護流程,副作用並不完全獨立;不同年齡或共病病人的副作用機率也未必相同。模型是地圖,不是地形本身。先問條件合不合理,再讓分布上場。
卜瓦松分布:單位時間內的事件數
卜瓦松分布 (Poisson distribution) 常用於描述某段時間、某個空間或某個族群中事件發生的次數。例如每小時急診到院人數、每月院內跌倒事件數、每 1000 導管日的感染數。
若 \(X\) 服從平均事件數為 \(\lambda\) 的卜瓦松分布,記作:
\[
X \sim \text{Poisson}(\lambda)
\]
其 PMF 為:
\[
P(X = k) = \frac{e^{-\lambda}\lambda^k}{k!}, \quad k = 0, 1, 2, \ldots
\]
卜瓦松分布有一個很有特色的性質:
\[
E(X) = \lambda,\quad \operatorname{Var}(X) = \lambda
\]
也就是平均值等於變異數。真實醫療資料若變異數遠大於平均值,稱為過度離散 (overdispersion),可能需要其他模型,例如負二項分布;這部分後面談迴歸時會再遇到。
範例 2:每小時急診到院人數
假設某兒科急診在夜班時段,平均每小時有 4 位發燒兒童到院。令 \(X\) 為某一小時內到院人數,則:
\[
X \sim \text{Poisson}(4)
\]
lambda_ed = 4
poisson_df = pd.DataFrame({"k": np.arange(0, 16)})
poisson_df["probability"] = poisson.pmf(poisson_df["k"], mu=lambda_ed)
poisson_df["cumulative_probability"] = poisson.cdf(poisson_df["k"], mu=lambda_ed)
poisson_df.round(4)
| 0 |
0 |
0.0183 |
0.0183 |
| 1 |
1 |
0.0733 |
0.0916 |
| 2 |
2 |
0.1465 |
0.2381 |
| 3 |
3 |
0.1954 |
0.4335 |
| 4 |
4 |
0.1954 |
0.6288 |
| 5 |
5 |
0.1563 |
0.7851 |
| 6 |
6 |
0.1042 |
0.8893 |
| 7 |
7 |
0.0595 |
0.9489 |
| 8 |
8 |
0.0298 |
0.9786 |
| 9 |
9 |
0.0132 |
0.9919 |
| 10 |
10 |
0.0053 |
0.9972 |
| 11 |
11 |
0.0019 |
0.9991 |
| 12 |
12 |
0.0006 |
0.9997 |
| 13 |
13 |
0.0002 |
0.9999 |
| 14 |
14 |
0.0001 |
1.0000 |
| 15 |
15 |
0.0000 |
1.0000 |
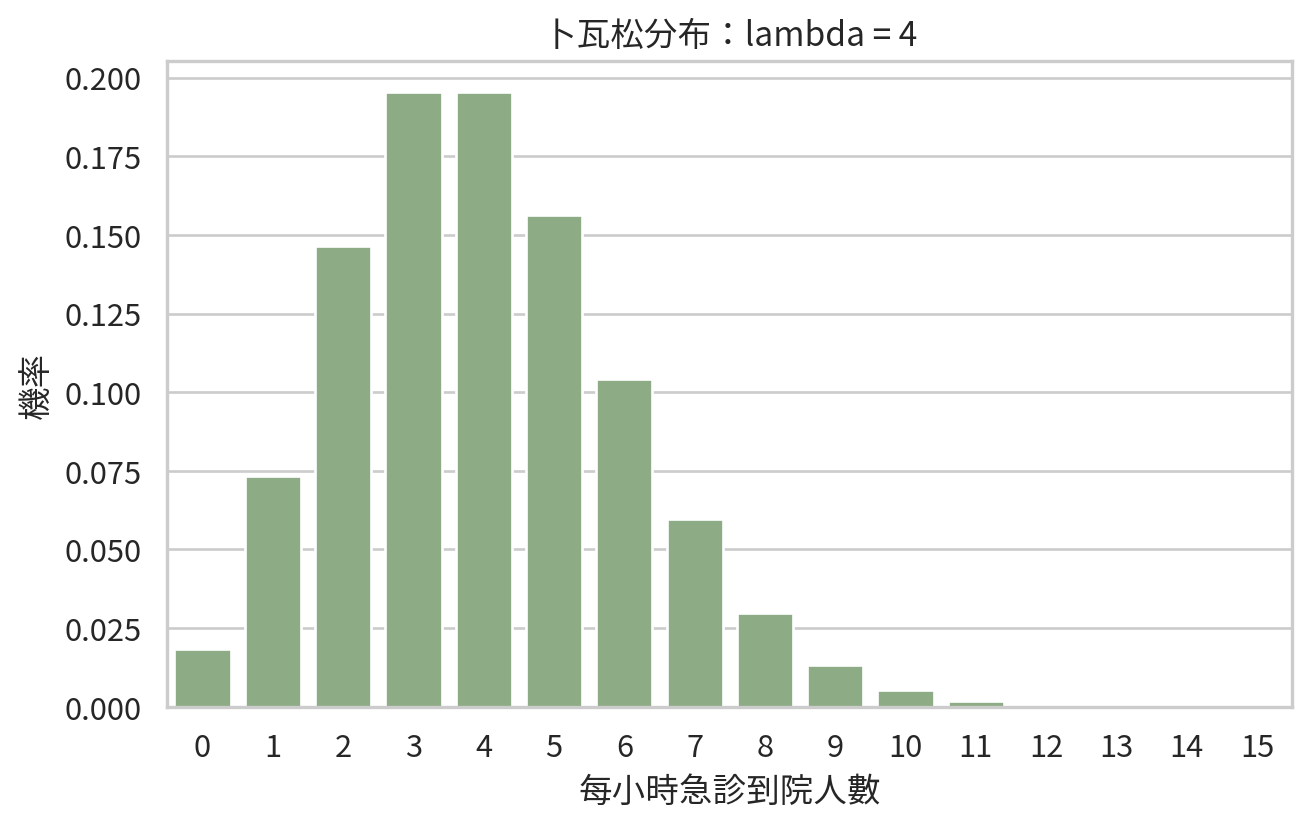
plt.figure(figsize=(7, 4.5))
sns.barplot(data=poisson_df, x="k", y="probability", color="#8ab17d")
plt.xlabel("每小時急診到院人數")
plt.ylabel("機率")
plt.title("卜瓦松分布:lambda = 4")
plt.tight_layout()
plt.savefig(FIG_DIR / "ch04_poisson_ed_arrivals.png", dpi=300)
plt.show()
如果急診護理長想知道「某小時來 8 位以上發燒兒童」的機率,可以計算:
\[
P(X \ge 8) = 1 - P(X \le 7)
\]
p_eight_or_more = 1 - poisson.cdf(7, mu=lambda_ed)
p_zero = poisson.pmf(0, mu=lambda_ed)
pd.DataFrame(
{
"問題": ["某小時沒有發燒兒童到院", "某小時 8 位以上發燒兒童到院"],
"機率": [p_zero, p_eight_or_more],
}
).round(4)
| 0 |
某小時沒有發燒兒童到院 |
0.0183 |
| 1 |
某小時 8 位以上發燒兒童到院 |
0.0511 |
卜瓦松分布常被用於醫療品質監測,但要注意事件率是否穩定。流感季、連假、天氣變化與醫院周邊診所休診,都可能讓到院率改變。統計模型很勤勞,但它不會自動知道今天是除夕夜。
二項分布與卜瓦松近似
當二項分布的 \(n\) 很大、\(p\) 很小,且 \(np = \lambda\) 適中時,卜瓦松分布可近似二項分布。這在罕見事件研究中很常見,例如某疫苗嚴重不良事件發生率很低,但接種人數很多。
假設嚴重不良事件機率為 0.001,追蹤 2000 位接種者,則 \(np = 2\)。二項分布可用 \(\text{Poisson}(2)\) 近似。
k_values = np.arange(0, 9)
approx_df = pd.DataFrame(
{
"k": k_values,
"二項分布": binom.pmf(k_values, n=2000, p=0.001),
"卜瓦松近似": poisson.pmf(k_values, mu=2),
}
)
approx_df.round(5)
| 0 |
0 |
0.13520 |
0.13534 |
| 1 |
1 |
0.27067 |
0.27067 |
| 2 |
2 |
0.27081 |
0.27067 |
| 3 |
3 |
0.18054 |
0.18045 |
| 4 |
4 |
0.09022 |
0.09022 |
| 5 |
5 |
0.03605 |
0.03609 |
| 6 |
6 |
0.01200 |
0.01203 |
| 7 |
7 |
0.00342 |
0.00344 |
| 8 |
8 |
0.00085 |
0.00086 |
近似不是魔法,是在特定條件下很方便的工具。現代電腦計算力強,多數時候直接使用正確分布即可;但理解近似能幫助你讀懂傳統流行病學與生物統計文獻。
超幾何分布:不放回抽樣
超幾何分布 (hypergeometric distribution) 用於有限母群體中不放回抽樣的成功次數。例如病歷稽核時,50 份病歷中有 8 份用藥紀錄錯誤,稽核人員抽查 10 份,抽到幾份錯誤?
二項分布假設每次試驗成功機率固定且獨立;但不放回抽樣時,每抽走一份病歷,剩下母群體組成就改變,因此試驗不獨立。這時超幾何分布比較合適。
若母群體大小為 \(N\),其中有 \(K\) 個成功,抽樣數為 \(n\),則抽到 \(k\) 個成功的機率為:
\[
P(X = k) = \frac{{K \choose k}{N-K \choose n-k}}{{N \choose n}}
\]
範例 3:病歷用藥紀錄稽核
population_size = 50
error_records = 8
sample_size = 10
hypergeom_df = pd.DataFrame({"k": np.arange(0, 6)})
hypergeom_df["probability"] = hypergeom.pmf(
hypergeom_df["k"],
M=population_size,
n=error_records,
N=sample_size,
)
hypergeom_df["cumulative_probability"] = hypergeom.cdf(
hypergeom_df["k"],
M=population_size,
n=error_records,
N=sample_size,
)
hypergeom_df.round(4)
| 0 |
0 |
0.1432 |
0.1432 |
| 1 |
1 |
0.3473 |
0.4905 |
| 2 |
2 |
0.3217 |
0.8122 |
| 3 |
3 |
0.1471 |
0.9593 |
| 4 |
4 |
0.0357 |
0.9950 |
| 5 |
5 |
0.0046 |
0.9997 |
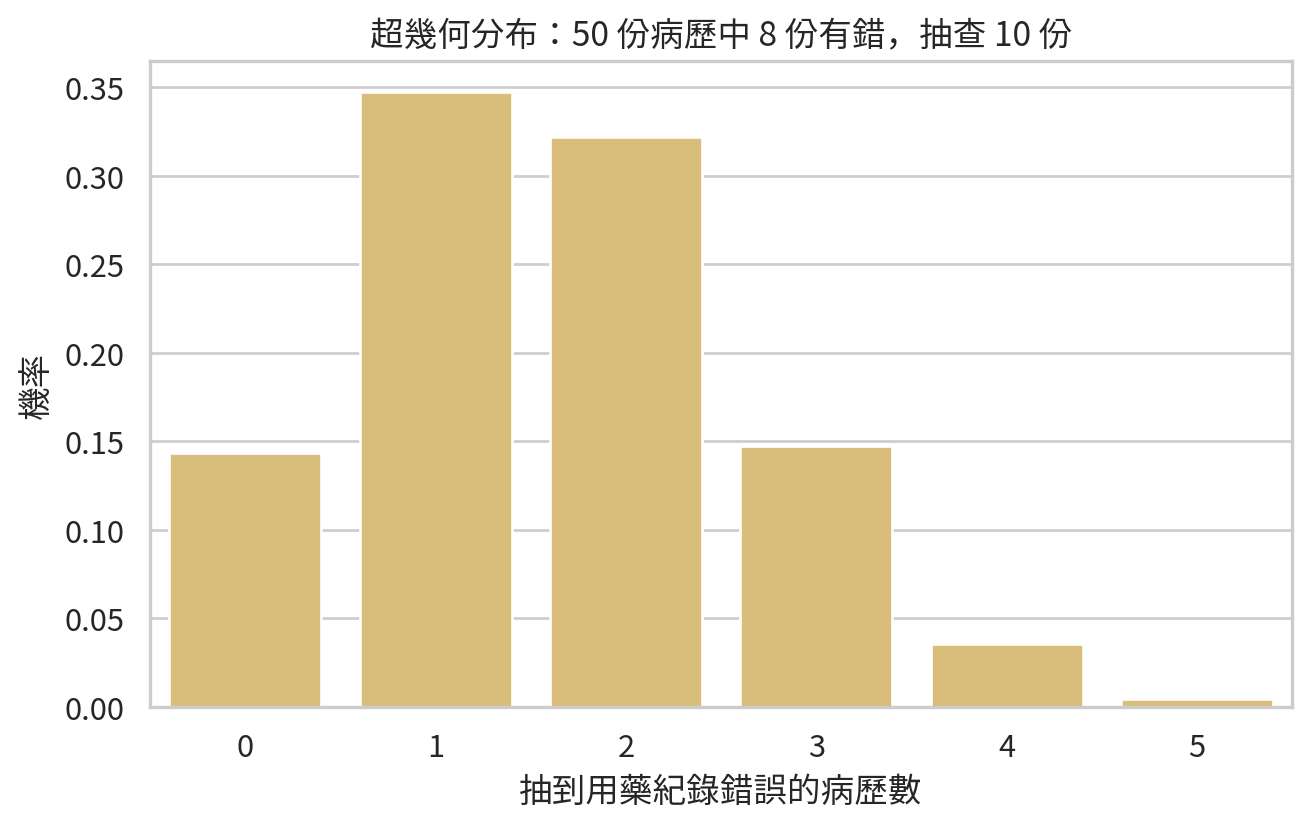
plt.figure(figsize=(7, 4.5))
sns.barplot(data=hypergeom_df, x="k", y="probability", color="#e9c46a")
plt.xlabel("抽到用藥紀錄錯誤的病歷數")
plt.ylabel("機率")
plt.title("超幾何分布:50 份病歷中 8 份有錯,抽查 10 份")
plt.tight_layout()
plt.savefig(FIG_DIR / "ch04_hypergeometric_chart_audit.png", dpi=300)
plt.show()
若想知道「至少抽到 2 份錯誤病歷」的機率:
p_at_least_2_errors = 1 - hypergeom.cdf(
1,
M=population_size,
n=error_records,
N=sample_size,
)
pd.DataFrame(
{
"問題": ["至少抽到 2 份錯誤病歷"],
"機率": [p_at_least_2_errors],
}
).round(4)
這類計算可以協助品質管理者設計抽查策略。若抽查太少,可能很難發現問題;若抽查太多,行政負擔又會增加。統計在這裡扮演一種務實的平衡工具。
幾何分布:等到第一次成功
幾何分布 (geometric distribution) 描述重複獨立試驗中,第一次成功出現在第幾次。若每次成功機率為 \(p\),令 \(X\) 為第一次成功所需試驗次數,則:
\[
P(X = k) = (1-p)^{k-1}p,\quad k = 1, 2, 3, \ldots
\]
其平均值為:
\[
E(X) = \frac{1}{p}
\]
幾何分布有一個重要特性,稱為無記憶性 (memoryless property):若前面幾次都沒成功,未來等待時間的分布不會因為已經等過而改變。這個概念很有趣,但現實醫療情境中「每次機率都一樣」未必成立,因此仍要小心使用。
範例 4:第幾位病人首次發現副作用?
假設某罕見但需追蹤的副作用,每位病人發生機率為 12%。門診連續追蹤新使用藥物的病人,令 \(X\) 為第一次觀察到此副作用時的病人序號。
p_event = 0.12
geom_df = pd.DataFrame({"trial": np.arange(1, 16)})
geom_df["probability"] = geom.pmf(geom_df["trial"], p=p_event)
geom_df["cumulative_probability"] = geom.cdf(geom_df["trial"], p=p_event)
geom_df.round(4)
| 0 |
1 |
0.1200 |
0.1200 |
| 1 |
2 |
0.1056 |
0.2256 |
| 2 |
3 |
0.0929 |
0.3185 |
| 3 |
4 |
0.0818 |
0.4003 |
| 4 |
5 |
0.0720 |
0.4723 |
| 5 |
6 |
0.0633 |
0.5356 |
| 6 |
7 |
0.0557 |
0.5913 |
| 7 |
8 |
0.0490 |
0.6404 |
| 8 |
9 |
0.0432 |
0.6835 |
| 9 |
10 |
0.0380 |
0.7215 |
| 10 |
11 |
0.0334 |
0.7549 |
| 11 |
12 |
0.0294 |
0.7843 |
| 12 |
13 |
0.0259 |
0.8102 |
| 13 |
14 |
0.0228 |
0.8330 |
| 14 |
15 |
0.0200 |
0.8530 |
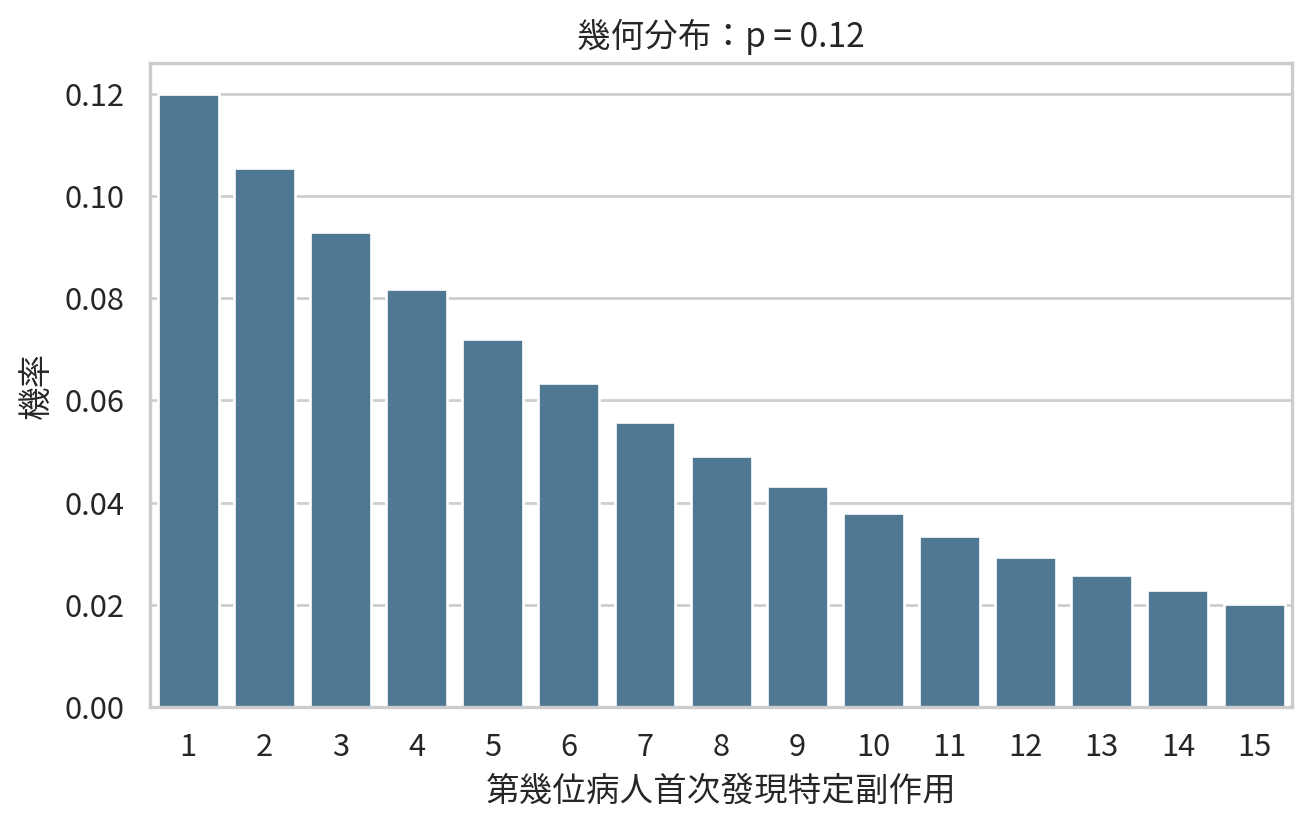
plt.figure(figsize=(7, 4.5))
sns.barplot(data=geom_df, x="trial", y="probability", color="#457b9d")
plt.xlabel("第幾位病人首次發現特定副作用")
plt.ylabel("機率")
plt.title("幾何分布:p = 0.12")
plt.tight_layout()
plt.savefig(FIG_DIR / "ch04_geometric_first_event.png", dpi=300)
plt.show()
平均等待病人數為 \(1 / 0.12 \approx 8.33\)。但平均不代表第 8 位一定會發生;有時候第 1 位就遇到,有時候等很久都沒有。臨床監測需要耐心,也需要別把運氣誤認成趨勢。
p_within_5 = geom.cdf(5, p=p_event)
p_after_10 = 1 - geom.cdf(10, p=p_event)
pd.DataFrame(
{
"問題": ["前 5 位病人內首次發現副作用", "超過 10 位病人才首次發現副作用"],
"機率": [p_within_5, p_after_10],
}
).round(4)
| 0 |
前 5 位病人內首次發現副作用 |
0.4723 |
| 1 |
超過 10 位病人才首次發現副作用 |
0.2785 |
如何選擇離散分布?
選擇分布時,先問資料生成機制,而不是先問軟體有哪些按鈕。
| 固定人數中有幾人發生事件 |
二項分布 |
固定 \(n\)、二元結果、相同 \(p\)、獨立 |
| 單位時間或空間內事件數 |
卜瓦松分布 |
事件率穩定、事件可視為獨立 |
| 有限母群體不放回抽樣 |
超幾何分布 |
母群體大小固定、抽樣不放回 |
| 等到第一次事件發生 |
幾何分布 |
重複獨立試驗、相同成功機率 |
如果資料不符合條件,不代表不能分析,而是要選擇更合適的模型或調整研究設計。例如病人群聚在同一醫師或同一病房下,獨立性可能被破壞;若事件率隨時間改變,單一卜瓦松率可能太簡化。
常見陷阱
- 把二項分布用在不固定試驗次數的問題:若觀察時間不同,可能需要事件率或人時概念。
- 忽略獨立性:同一家庭、同一病房或同一醫師照護下的病人可能彼此相關。
- 把卜瓦松分布套在變異過大的資料上:若變異數遠大於平均值,可能有過度離散。
- 忘記不放回抽樣會改變機率:有限母群體抽樣稽核常需超幾何分布。
- 只報最可能值,不報尾端機率:臨床風險管理常關心少見但嚴重的尾端事件。
本章重點整理
- 離散機率分布描述可數隨機變項的可能值與其機率。
- PMF 給出 \(P(X = x)\);CDF 給出 \(P(X \le x)\)。
- 二項分布適用於固定試驗次數中的成功次數。
- 卜瓦松分布適用於單位時間或空間中的事件數。
- 超幾何分布適用於有限母群體的不放回抽樣。
- 幾何分布適用於第一次成功所需的試驗次數。
- 分布選擇應根據資料生成機制,而不是只根據資料長得像什麼。
小練習
- 某藥物副作用機率為 0.15,20 位病人中剛好 4 位發生副作用的機率是多少?
- 同一情境下,至少 5 位發生副作用的機率是多少?
- 某加護病房平均每天有 2.5 次呼吸器警報,某天超過 5 次的機率是多少?
- 80 份病歷中 12 份有缺漏,抽查 15 份,至少抽到 3 份缺漏的機率是多少?
- 若每位病人特定副作用機率為 0.08,首次發現副作用出現在第 10 位以前的機率是多少?
practice_exact_4 = binom.pmf(4, n=20, p=0.15)
practice_at_least_5 = 1 - binom.cdf(4, n=20, p=0.15)
practice_alarm_gt_5 = 1 - poisson.cdf(5, mu=2.5)
practice_missing_at_least_3 = 1 - hypergeom.cdf(2, M=80, n=12, N=15)
practice_first_by_10 = geom.cdf(10, p=0.08)
pd.DataFrame(
{
"問題": [
"20 位中剛好 4 位副作用",
"20 位中至少 5 位副作用",
"每天呼吸器警報超過 5 次",
"抽查 15 份至少 3 份缺漏",
"第 10 位以前首次發現副作用",
],
"機率": [
practice_exact_4,
practice_at_least_5,
practice_alarm_gt_5,
practice_missing_at_least_3,
practice_first_by_10,
],
}
).round(4)
| 0 |
20 位中剛好 4 位副作用 |
0.1821 |
| 1 |
20 位中至少 5 位副作用 |
0.1702 |
| 2 |
每天呼吸器警報超過 5 次 |
0.0420 |
| 3 |
抽查 15 份至少 3 份缺漏 |
0.3983 |
| 4 |
第 10 位以前首次發現副作用 |
0.5656 |
Glossary
| 離散機率分布 |
discrete probability distribution |
描述離散隨機變項各可能值與其機率的分布。 |
| 隨機變項 |
random variable |
將隨機結果轉換為數值的規則。 |
| 離散隨機變項 |
discrete random variable |
可能值可數或可列舉的隨機變項。 |
| 機率質量函數 |
probability mass function, PMF |
給出離散隨機變項取特定值機率的函數。 |
| 累積分布函數 |
cumulative distribution function, CDF |
給出隨機變項小於或等於某值機率的函數。 |
| 二項分布 |
binomial distribution |
描述固定次數獨立二元試驗中成功次數的分布。 |
| 試驗次數 |
number of trials |
二項或相關分布中重複試驗的固定次數。 |
| 成功機率 |
success probability |
每次試驗中成功事件發生的機率。 |
| 期望值 |
expected value |
隨機變項的長期平均值。 |
| 變異數 |
variance |
隨機變項分散程度的量化指標。 |
| 卜瓦松分布 |
Poisson distribution |
描述固定時間或空間內事件計數的分布。 |
| 事件率 |
event rate |
單位時間、空間或人時中事件發生的平均頻率。 |
| 過度離散 |
overdispersion |
計數資料變異數大於模型預期變異數的現象。 |
| 卜瓦松近似 |
Poisson approximation |
在大樣本、小機率條件下用卜瓦松分布近似二項分布。 |
| 超幾何分布 |
hypergeometric distribution |
描述有限母群體中不放回抽樣成功次數的分布。 |
| 不放回抽樣 |
sampling without replacement |
抽出的個體不再放回母群體的抽樣方式。 |
| 幾何分布 |
geometric distribution |
描述第一次成功所需試驗次數的分布。 |
| 無記憶性 |
memoryless property |
已等待時間不改變未來等待分布的性質。 |
| 尾端機率 |
tail probability |
分布極端區域事件發生的機率。 |