本章學習目標
前一章我們處理可以數出來的隨機變項,例如副作用人數、急診到院數、抽到錯誤病歷數。這一章要進入連續機率分布 (continuous probability distribution):血壓、膽固醇、身高、等待時間、發炎指標等變項理論上可以在某個範圍內取非常多可能值。連續分布的世界不再問「剛好等於某個值」的機率,而是問「落在某個區間」的機率。
讀完本章後,你應該能夠:
說明連續隨機變項 (continuous random variable)、機率密度函數 (probability density function, PDF) 與累積分布函數 (cumulative distribution function, CDF)。
解釋常態分布 (normal distribution) 與標準常態分布 (standard normal distribution) 在生物醫學統計中的角色。
使用 z 分數 (z-score) 與百分位數 (percentile) 進行常態分布機率計算。
認識對數常態分布 (log-normal distribution) 與指數分布 (exponential distribution) 的臨床應用。
說明 t 分布 (t distribution)、卡方分布 (chi-square distribution) 與 F 分布 (F distribution) 為何會在後續推論統計中出現。
使用 Python 3.14 與 scipy.stats 計算並視覺化連續機率分布。
連續隨機變項與機率密度
連續隨機變項 (continuous random variable) 可以在某個區間內取無限多個可能值。例如收縮壓可能是 119.8、120.0、120.03 mmHg;真正測量時儀器會四捨五入,但概念上它是連續的。
對連續分布來說,單一精確值的機率是 0。也就是說,\(P(X = 120)\) 在數學上是 0;我們真正關心的是區間機率,例如:
\[
P(120 \le X \le 140)
\]
機率密度函數 (probability density function, PDF) 的曲線高度不是機率本身,而是密度。曲線下某段區間的面積才是機率。這點很重要,因為初學者很容易把曲線高度當成機率。請記得:連續分布看面積,不看單點高度。
累積分布函數 (cumulative distribution function, CDF) 定義為:
\[
F(x) = P(X \le x)
\]
它回答「小於或等於某值」的機率。若要算區間機率:
\[
P(a \le X \le b) = F(b) - F(a)
\]
常態分布:醫學統計的常客
常態分布 (normal distribution) 是最重要的連續分布之一。若隨機變項 \(X\) 服從平均值 \(\mu\) 、標準差 \(\sigma\) 的常態分布,記作:
\[
X \sim N(\mu, \sigma^2)
\]
常態分布有鐘形、對稱的形狀。平均值、中位數與眾數位於同一位置。約 68% 的資料落在平均值正負 1 個標準差內,約 95% 落在正負 2 個標準差內,約 99.7% 落在正負 3 個標準差內。這常被稱為 68-95-99.7 規則。
常態分布常用於近似身高、某些生理量、測量誤差,以及更重要的:許多估計量的抽樣分布 (sampling distribution)。後者會在估計與假設檢定章節成為主角。
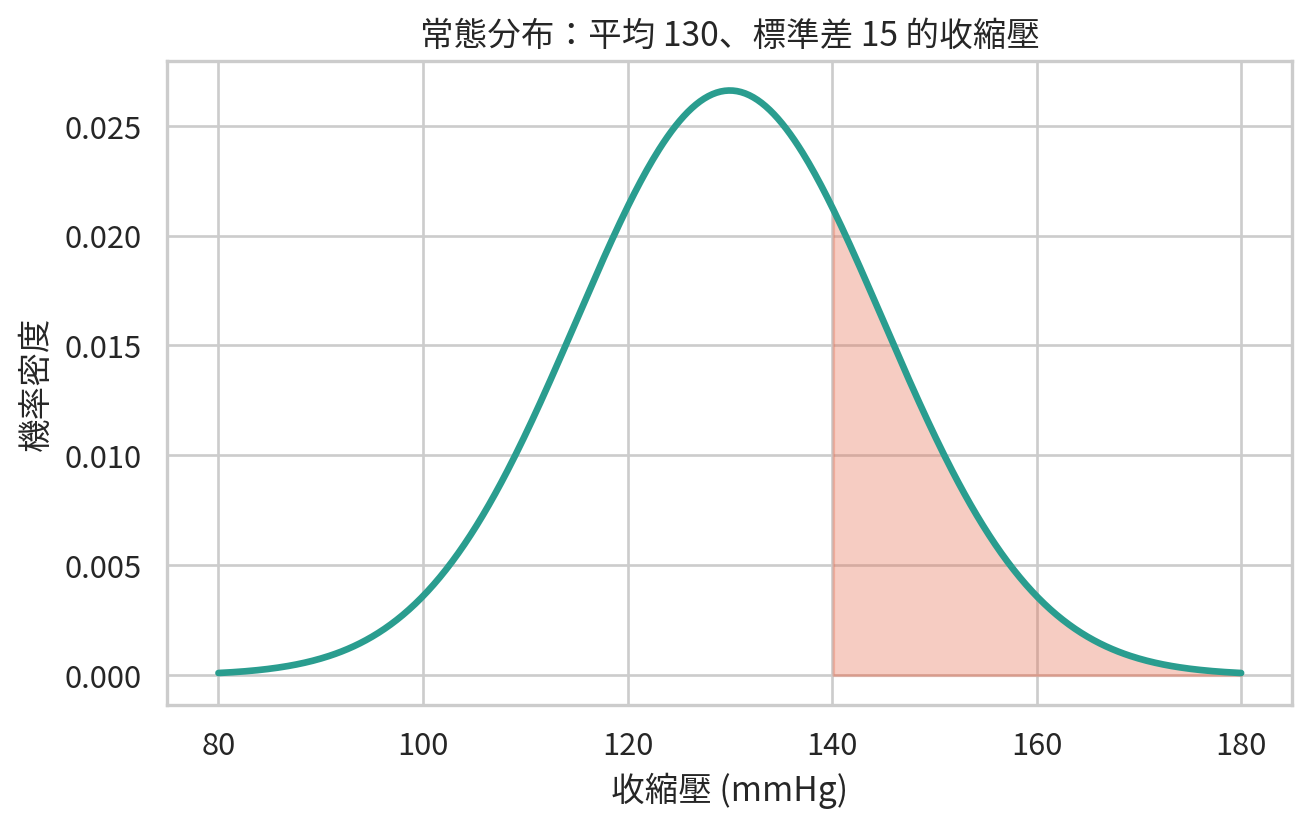
範例 1:收縮壓高於 140 mmHg 的機率
假設某門診族群的收縮壓近似常態分布,平均值 130 mmHg,標準差 15 mmHg。令 \(X\) 為收縮壓:
\[
X \sim N(130, 15^2)
\]
我們想知道收縮壓至少 140 mmHg 的機率。
= 130 = 15 = 140 = 1 - norm.cdf(threshold, loc= mean_sbp, scale= sd_sbp)= (threshold - mean_sbp) / sd_sbp"quantity" : ["z 分數" , "P(SBP >= 140)" ],"value" : [z_threshold, p_high_sbp],round (4 )
0
z 分數
0.6667
1
P(SBP >= 140)
0.2525
= np.linspace(80 , 180 , 500 )= pd.DataFrame("sbp" : sbp_grid,"density" : norm.pdf(sbp_grid, loc= mean_sbp, scale= sd_sbp),= (7 , 4.5 ))= sbp_df, x= "sbp" , y= "density" , color= "#2a9d8f" , linewidth= 2.5 )0 , sbp_df["density" ], where= sbp_grid >= threshold, color= "#e76f51" , alpha= 0.35 )"收縮壓 (mmHg)" )"機率密度" )"常態分布:平均 130、標準差 15 的收縮壓" )/ "ch05_normal_sbp_tail.png" , dpi= 300 )
這個機率約表示:若上述常態模型合理,隨機抽一位門診病人,其收縮壓至少 140 mmHg 的機率是多少。請注意,這不是說每 100 位病人中一定有固定人數超過 140,而是長期比例的模型描述。
標準常態分布與 z 分數
標準常態分布 (standard normal distribution) 是平均值 0、標準差 1 的常態分布,記作:
\[
Z \sim N(0, 1)
\]
任何常態變項 \(X \sim N(\mu, \sigma^2)\) 都可轉成 z 分數:
\[
Z = \frac{X - \mu}{\sigma}
\]
z 分數表示某觀察值距離平均值幾個標準差。例如上面的 140 mmHg:
\[
Z = \frac{140 - 130}{15} = 0.667
\]
也就是 140 mmHg 比平均值高 0.667 個標準差。z 分數可以把不同量尺的資料放到同一個標準常態架構中比較。
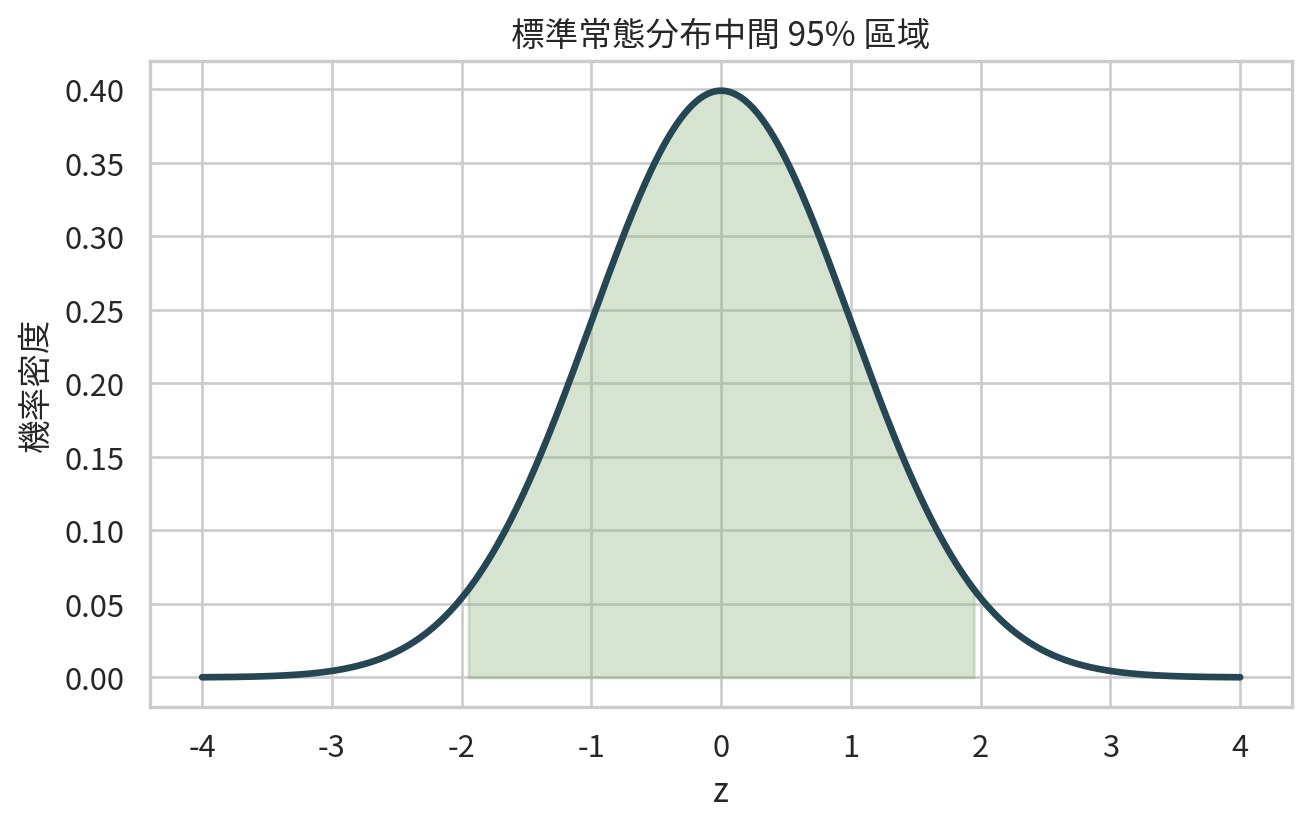
範例 2:標準常態中間 95%
標準常態分布中,約 95% 機率落在 -1.96 到 1.96 之間。這個數字會在信賴區間 (confidence interval) 中反覆出現。
= norm.cdf(1.96 ) - norm.cdf(- 1.96 )= norm.ppf([0.025 , 0.975 ])"quantity" : ["P(-1.96 <= Z <= 1.96)" , "第 2.5 百分位數" , "第 97.5 百分位數" ],"value" : [middle_95, central_limits[0 ], central_limits[1 ]],round (4 )
0
P(-1.96 <= Z <= 1.96)
0.95
1
第 2.5 百分位數
-1.96
2
第 97.5 百分位數
1.96
= np.linspace(- 4 , 4 , 500 )= pd.DataFrame({"z" : z_grid, "density" : norm.pdf(z_grid)})= (7 , 4.5 ))= z_df, x= "z" , y= "density" , color= "#264653" , linewidth= 2.5 )0 , z_df["density" ], where= (z_grid >= - 1.96 ) & (z_grid <= 1.96 ), color= "#8ab17d" , alpha= 0.35 )"z" )"機率密度" )"標準常態分布中間 95% 區域" )/ "ch05_standard_normal_95.png" , dpi= 300 )
醫學統計裡很多「95%」都不是神秘儀式,而是來自常態近似與長期覆蓋率的概念。它不是完美保證,但很好用;像聽診器一樣,不能回答所有問題,但值得放在口袋裡。
百分位數與參考區間
百分位數 (percentile) 在連續分布中也很常見。例如某檢驗值位於第 97.5 百分位數以上,可能被視為偏高。臨床檢驗常見的參考區間 (reference interval) 通常涵蓋健康族群中間 95% 的檢驗值,也就是第 2.5 到第 97.5 百分位數。
若某健康成人檢驗值近似常態分布,平均值 50、標準差 10,其中間 95% 約為:
= 50 = 10 = norm.ppf([0.025 , 0.975 ], loc= ref_mean, scale= ref_sd)"bound" : ["lower 2.5%" , "upper 97.5%" ],"value" : reference_interval,round (2 )
0
lower 2.5%
30.4
1
upper 97.5%
69.6
參考區間不是診斷標準的同義詞。落在參考區間外不一定有病,落在參考區間內也不保證健康。它只是描述參考族群分布的位置,臨床解釋仍要看症狀、風險、檢驗目的與測量誤差。
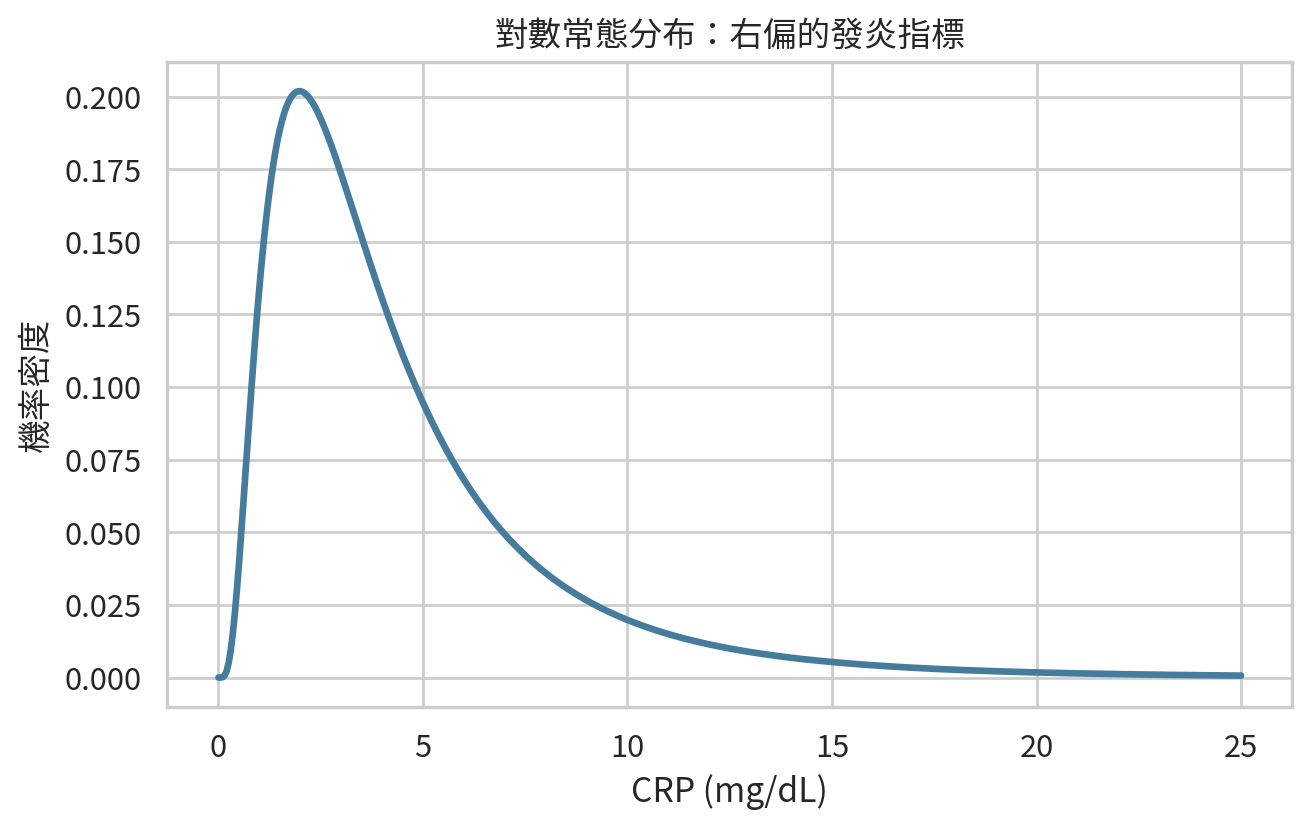
對數常態分布:右偏的生物標記
對數常態分布 (log-normal distribution) 常用於描述右偏且只能取正值的資料,例如 CRP、醫療費用、住院天數、某些生物標記濃度。若 \(Y = \log(X)\) 服從常態分布,則 \(X\) 服從對數常態分布。
這代表原始資料可能右偏,但取對數後比較接近對稱。許多臨床研究會對右偏變項做對數轉換 (log transformation),讓模型假設更合理。
= lognorm.median(s= 0.75 , scale= np.exp(1.25 ))= lognorm.mean(s= 0.75 , scale= np.exp(1.25 ))= lognorm.ppf(0.95 , s= 0.75 , scale= np.exp(1.25 ))"quantity" : ["中位數" , "平均值" , "第 95 百分位數" ],"CRP" : [crp_median, crp_mean, crp_p95],round (2 )
0
中位數
3.49
1
平均值
4.62
2
第 95 百分位數
11.98
= np.linspace(0.01 , 25 , 500 )= pd.DataFrame("crp" : crp_grid,"density" : lognorm.pdf(crp_grid, s= 0.75 , scale= np.exp(1.25 )),= (7 , 4.5 ))= crp_df, x= "crp" , y= "density" , color= "#457b9d" , linewidth= 2.5 )"CRP (mg/dL)" )"機率密度" )"對數常態分布:右偏的發炎指標" )/ "ch05_lognormal_crp.png" , dpi= 300 )
對數常態分布有一個臨床上很重要的提醒:右偏資料的平均值常大於中位數。若只報平均值,讀者可能以為典型病人的 CRP 比實際更高。這時中位數與四分位距常更容易解釋。
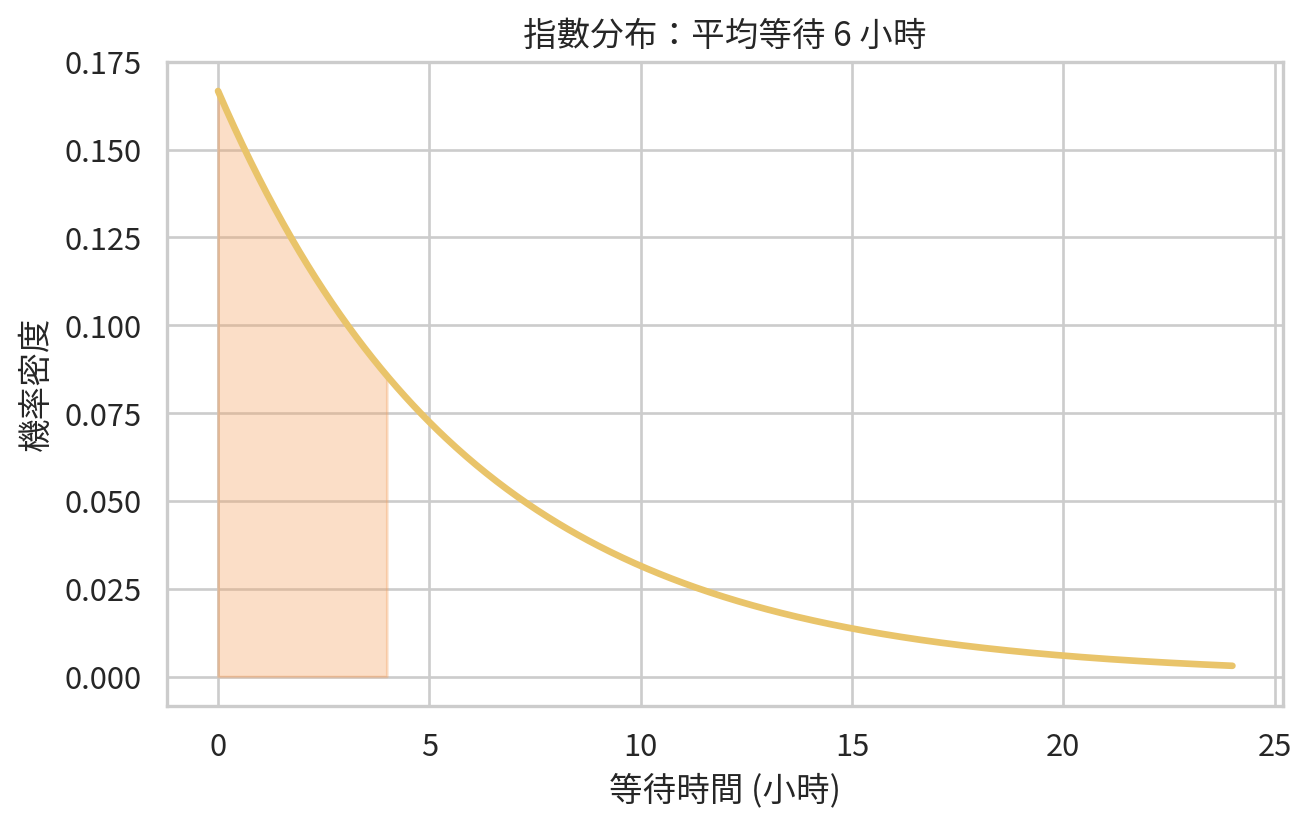
指數分布:等待下一個事件
指數分布 (exponential distribution) 常用來描述等待下一個事件發生的時間,例如等待下一位急診病人到院、等待下一次警報、等待某設備故障。若事件以穩定速率隨機發生,等待時間可用指數分布描述。
指數分布常以 rate 參數 \(\lambda\) 表示,平均等待時間為 \(1/\lambda\) 。在 scipy.stats.expon 中,常用 scale 表示平均等待時間。
範例 3:等待下一位急診病人
假設某時段平均每 6 小時出現 1 位需要隔離床的病人。令 \(T\) 為等待下一位此類病人的時間,若 \(T\) 服從平均 6 小時的指數分布,則 4 小時內出現的機率為:
= 6 = expon.cdf(4 , scale= mean_wait)= 1 - expon.cdf(12 , scale= mean_wait)"問題" : ["4 小時內出現" , "超過 12 小時才出現" ],"機率" : [p_within_4_hours, p_more_than_12_hours],round (4 )
0
4 小時內出現
0.4866
1
超過 12 小時才出現
0.1353
= np.linspace(0 , 24 , 500 )= pd.DataFrame({"hours" : wait_grid, "density" : expon.pdf(wait_grid, scale= mean_wait)})= (7 , 4.5 ))= wait_df, x= "hours" , y= "density" , color= "#e9c46a" , linewidth= 2.5 )0 , wait_df["density" ], where= wait_grid <= 4 , color= "#f4a261" , alpha= 0.35 )"等待時間 (小時)" )"機率密度" )"指數分布:平均等待 6 小時" )/ "ch05_exponential_waiting_time.png" , dpi= 300 )
指數分布具有無記憶性 (memoryless property):已經等了多久,不改變未來還要等多久的分布。這個性質在數學上漂亮,但在醫院現場未必完全成立,因為到院率可能受時段、天氣、假日與疫情影響。
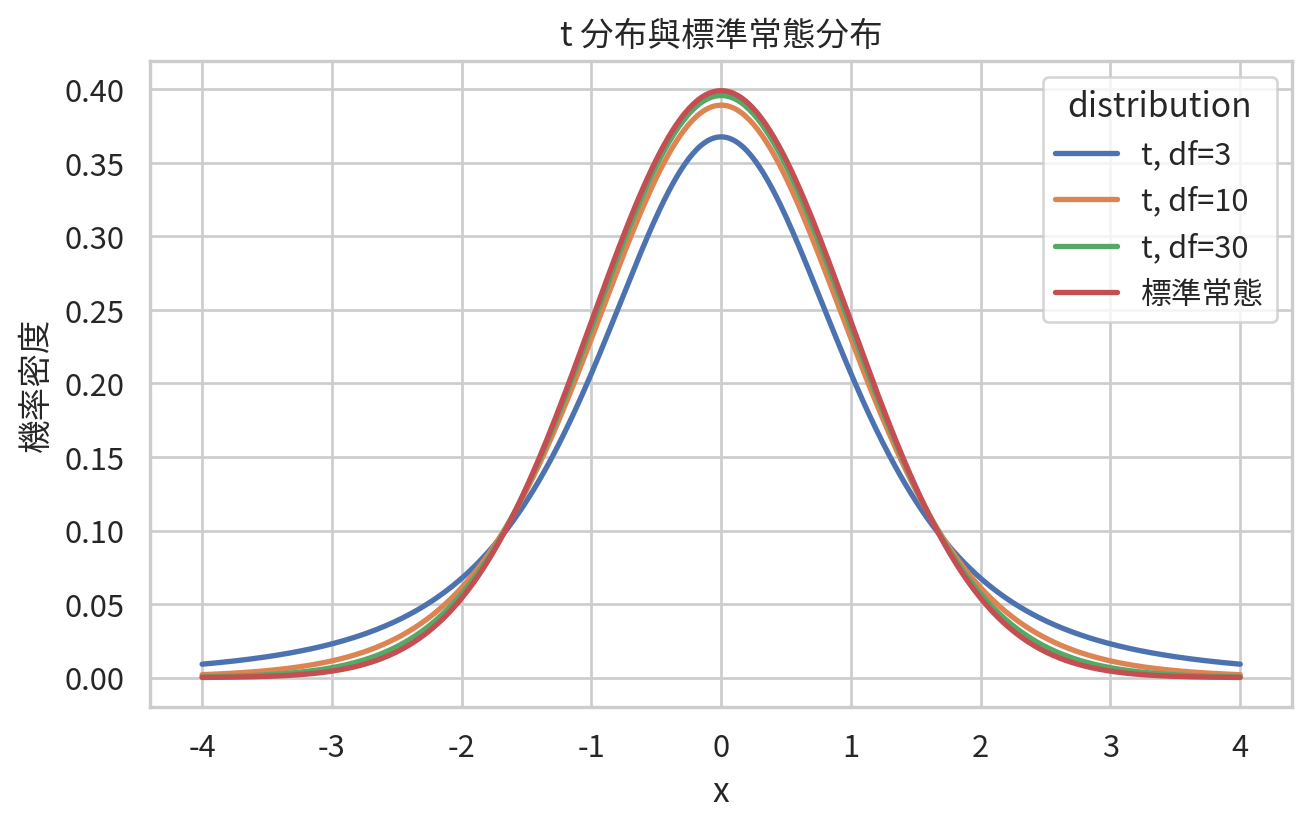
t 分布:小樣本平均值的不確定性
t 分布 (t distribution) 與常態分布相似,但尾端較厚。當樣本數較小、母群體標準差未知、我們用樣本標準差估計不確定性時,t 分布會自然出現。它是信賴區間與 t 檢定的重要基礎。
t 分布由自由度 (degrees of freedom) 控制。自由度越小,尾端越厚;自由度越大,t 分布越接近標準常態分布。
= np.linspace(- 4 , 4 , 500 )= []for df_value in [3 , 10 , 30 ]:"x" : x, "density" : t.pdf(x, df= df_value), "distribution" : f"t, df= { df_value} " }for x in x_grid"x" : x, "density" : norm.pdf(x), "distribution" : "標準常態" } for x in x_grid)= pd.DataFrame(dist_rows)= (7 , 4.5 ))= t_df, x= "x" , y= "density" , hue= "distribution" , linewidth= 2 )"x" )"機率密度" )"t 分布與標準常態分布" )/ "ch05_t_distribution_comparison.png" , dpi= 300 )
為什麼小樣本需要 t 分布?因為樣本標準差本身也有不確定性。樣本少時,我們對標準差估得比較不穩,於是分布尾端需要更保守一些。統計不是悲觀,它只是知道資料少時別太自信。
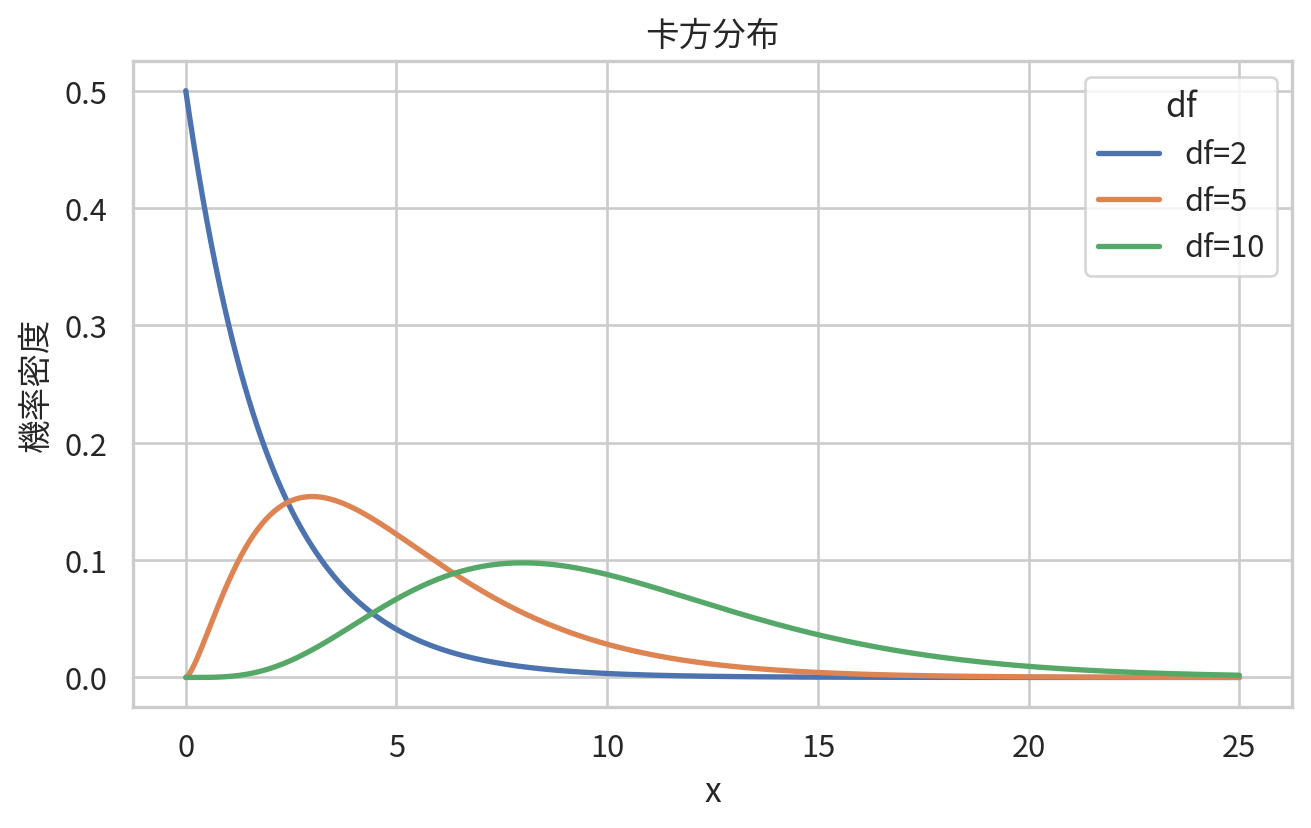
卡方分布與 F 分布
卡方分布 (chi-square distribution) 常用於變異數推論、類別資料檢定與適合度檢定。若多個獨立標準常態變項平方後相加,結果會服從卡方分布。卡方分布只取非負值,形狀由自由度決定。
= np.linspace(0 , 25 , 500 )= []for df_value in [2 , 5 , 10 ]:"x" : x, "density" : chi2.pdf(x, df= df_value), "df" : f"df= { df_value} " }for x in chi_grid= pd.DataFrame(chi_rows)= (7 , 4.5 ))= chi_df, x= "x" , y= "density" , hue= "df" , linewidth= 2 )"x" )"機率密度" )"卡方分布" )/ "ch05_chi_square_distributions.png" , dpi= 300 )
F 分布 (F distribution) 是兩個依自由度調整後的卡方變項比值,常出現在變異數分析 (analysis of variance, ANOVA) 與多組平均值比較。若你現在覺得它很抽象,完全正常。先記住它是「比較變異來源」的重要分布,Chapter 12 會更常見到它。
= pd.DataFrame("probability" : [0.90 , 0.95 , 0.975 ],"F(df1=3, df2=20)" : f.ppf([0.90 , 0.95 , 0.975 ], dfn= 3 , dfd= 20 ),round (3 )
0
0.900
2.380
1
0.950
3.098
2
0.975
3.859
如何選擇連續分布?
選擇分布時,先看資料的支持範圍、形狀與生成機制。
對稱、鐘形的生理量或估計量
常態分布
適合平均值附近對稱的資料或抽樣分布
右偏且只能為正的檢驗值或費用
對數常態分布
常搭配對數轉換
等待下一個事件的時間
指數分布
假設事件率穩定且具有無記憶性
小樣本平均值推論
t 分布
標準差未知時很常用
變異數與類別資料檢定
卡方分布
只取非負值,受自由度影響
變異數比例與 ANOVA
F 分布
常用於多組比較
分布不是資料的身分證,而是模型。模型可以幫我們思考,但也可能過度簡化。最好的習慣是:先畫圖、看摘要、理解資料來源,再決定分布假設是否合理。
常見陷阱
把密度當機率 :連續分布中,曲線高度不是機率,曲線下面積才是機率。假設所有資料都常態 :許多醫療資料明顯右偏,硬套常態會誤導。忘記單位與轉換 :對數轉換後的結果需小心解讀,不能直接當原始尺度。只看平均值不看分布形狀 :同樣平均值可能有完全不同的尾端風險。把參考區間當診斷門檻 :參考區間描述族群分布,不等於臨床診斷標準。
本章重點整理
連續隨機變項的單點機率為 0,區間機率由 PDF 曲線下面積表示。
CDF 可用來計算小於或等於某值的機率,區間機率可由兩個 CDF 相減。
常態分布是連續資料與抽樣分布的核心模型。
z 分數把常態變項標準化到平均 0、標準差 1 的尺度。
對數常態分布常用於右偏且為正值的醫療資料。
指數分布常用於等待時間與事件間隔。
t、卡方與 F 分布是後續估計、假設檢定與變異數分析的重要基礎。
小練習
若收縮壓 \(X \sim N(125, 12^2)\) ,計算 \(P(X \ge 140)\) 。
若 \(Z \sim N(0,1)\) ,計算 \(P(-1.64 \le Z \le 1.64)\) 。
某等待時間服從平均 8 小時的指數分布,計算 6 小時內發生事件的機率。
查出自由度 12 的 t 分布第 97.5 百分位數。
想一個右偏醫療資料例子,說明為何平均值可能不代表典型病人。
= 1 - norm.cdf(140 , loc= 125 , scale= 12 )= norm.cdf(1.64 ) - norm.cdf(- 1.64 )= expon.cdf(6 , scale= 8 )= t.ppf(0.975 , df= 12 )"問題" : ["P(SBP >= 140), mean=125, SD=12" ,"P(-1.64 <= Z <= 1.64)" ,"平均等待 8 小時時,6 小時內發生" ,"t(df=12) 第 97.5 百分位數" ,"數值" : [round (4 )
0
P(SBP >= 140), mean=125, SD=12
0.1056
1
P(-1.64 <= Z <= 1.64)
0.8990
2
平均等待 8 小時時,6 小時內發生
0.5276
3
t(df=12) 第 97.5 百分位數
2.1788
Glossary
連續機率分布
continuous probability distribution
描述連續隨機變項可能值與機率結構的分布。
連續隨機變項
continuous random variable
可在某區間內取無限多可能值的隨機變項。
機率密度函數
probability density function, PDF
描述連續分布密度的函數,曲線下面積代表機率。
累積分布函數
cumulative distribution function, CDF
給出隨機變項小於或等於某值機率的函數。
常態分布
normal distribution
對稱鐘形的連續分布,由平均值與標準差決定。
標準常態分布
standard normal distribution
平均值 0、標準差 1 的常態分布。
z 分數
z-score
觀察值距離平均值幾個標準差的標準化數值。
百分位數
percentile
分布中有特定比例低於或等於該值的位置。
參考區間
reference interval
通常涵蓋參考族群中間 95% 數值的區間。
對數常態分布
log-normal distribution
取對數後服從常態分布的正值變項分布。
對數轉換
log transformation
對資料取對數以改善右偏或模型假設的方法。
指數分布
exponential distribution
常用於等待下一個事件發生時間的連續分布。
無記憶性
memoryless property
已等待時間不改變未來等待分布的性質。
t 分布
t distribution
小樣本平均值推論常用、尾端較常態厚的分布。
自由度
degrees of freedom
分布或估計中可自由變動資訊量的參數。
卡方分布
chi-square distribution
非負連續分布,常用於變異數與類別資料檢定。
F 分布
F distribution
兩個變異估計比值相關的分布,常用於 ANOVA。
變異數分析
analysis of variance, ANOVA
比較多組平均值時常用的統計方法。
抽樣分布
sampling distribution
統計量在重複抽樣下形成的機率分布。