本章學習目標
前幾章我們學會描述資料、理解機率與常見機率分布。現在要進入推論統計的核心:估計 (estimation)。醫學研究通常無法觀察完整母群體,因此我們用樣本資料推估母群體的未知特徵。例如:台灣成人平均收縮壓是多少?某治療後平均 LDL-C 下降多少?某疫苗接種後嚴重不良事件比例是多少?
估計的精神不是假裝知道真相,而是用資料給出最合理的答案,並誠實描述不確定性。這句話很重要,因為統計最迷人的地方不是「算出一個數字」,而是「知道這個數字可能錯多少」。
讀完本章後,你應該能夠:
- 區分點估計 (point estimation) 與區間估計 (interval estimation)。
- 說明估計量 (estimator)、估計值 (estimate)、偏差 (bias)、精確度 (precision) 與均方誤差 (mean squared error, MSE)。
- 解釋標準誤 (standard error, SE) 與抽樣分布 (sampling distribution)。
- 建立母群體平均值 (population mean) 與母群體比例 (population proportion) 的信賴區間 (confidence interval, CI)。
- 解釋 95% 信賴區間的正確意義。
- 使用 bootstrap 方法建立估計不確定性的直覺。
估計是什麼?
估計是用樣本統計量推測母群體參數。參數 (parameter) 是母群體的未知真實值,例如全台高血壓病人的平均收縮壓 \(\mu\)。統計量 (statistic) 是由樣本計算出的數值,例如抽樣 200 位病人的平均收縮壓 \(\bar{x}\)。
點估計給出單一最佳猜測。例如樣本平均收縮壓為 132.4 mmHg,我們可用它估計母群體平均收縮壓。區間估計則給出一段合理範圍,例如 95% 信賴區間為 129.8 到 135.0 mmHg。點估計像地圖上的定位點,區間估計像定位圈;圈越小,代表估計越精確。
bp_sample = np.array([128, 142, 136, 150, 131, 145, 139, 155, 133, 148, 141, 137, 152, 130, 146])
bp_summary = pd.DataFrame(
{
"statistic": ["樣本數", "樣本平均值", "樣本標準差"],
"value": [len(bp_sample), bp_sample.mean(), bp_sample.std(ddof=1)],
}
)
bp_summary.round(2)
| 0 |
樣本數 |
15.00 |
| 1 |
樣本平均值 |
140.87 |
| 2 |
樣本標準差 |
8.40 |
這組資料可想像為 15 位門診病人的收縮壓。樣本平均值是母群體平均值的點估計,但我們知道它不會剛好等於真實母群體平均值。下一步就是量化這個不確定性。
估計量的好壞:偏差與精確度
估計量 (estimator) 是估計參數的方法或公式;估計值 (estimate) 是用特定樣本算出的結果。例如樣本平均值 \(\bar{X}\) 是估計量,而 141.2 mmHg 是某次樣本算出的估計值。
偏差 (bias) 是估計量長期平均與真實參數之間的差異。若一個血壓計每次都比真實值高 5 mmHg,它很穩定,但有偏差。精確度 (precision) 描述估計值在重複抽樣時的分散程度。若每次測量都差很多,即使平均沒有偏差,也不夠精確。
均方誤差 (mean squared error, MSE) 結合偏差與變異:
\[
\operatorname{MSE}(\hat{\theta}) = \operatorname{Var}(\hat{\theta}) + \operatorname{Bias}(\hat{\theta})^2
\]
這個公式提醒我們:好估計不只要平均來說不偏,也要不要太飄。臨床上也是如此,一個檢驗若今天高、明天低、後天又像抽籤,即使平均沒錯,也會讓人很想深呼吸。
抽樣分布與標準誤
抽樣分布是指在同一母群體中反覆抽樣,每次計算同一個統計量後形成的分布。例如每次抽 40 位病人計算平均收縮壓,重複 5000 次,這 5000 個樣本平均值就形成樣本平均值的抽樣分布。
標準誤 (standard error, SE) 是估計量抽樣分布的標準差。它描述估計值在重複抽樣中會波動多大。對樣本平均值而言:
\[
SE(\bar{X}) = \frac{\sigma}{\sqrt{n}}
\]
若母群體標準差 \(\sigma\) 未知,通常用樣本標準差 \(s\) 代替:
\[
\widehat{SE}(\bar{X}) = \frac{s}{\sqrt{n}}
\]
sample_mean = bp_sample.mean()
sample_sd = bp_sample.std(ddof=1)
sample_n = len(bp_sample)
se_mean = sample_sd / np.sqrt(sample_n)
pd.DataFrame(
{
"quantity": ["樣本平均值", "樣本標準差", "平均值標準誤"],
"value": [sample_mean, sample_sd, se_mean],
}
).round(3)
| 0 |
樣本平均值 |
140.867 |
| 1 |
樣本標準差 |
8.400 |
| 2 |
平均值標準誤 |
2.169 |
標準差描述個別病人的收縮壓有多分散;標準誤描述樣本平均值作為估計值有多不穩。這兩者不能混用。標準差是病人之間的差異,標準誤是估計的不確定性。
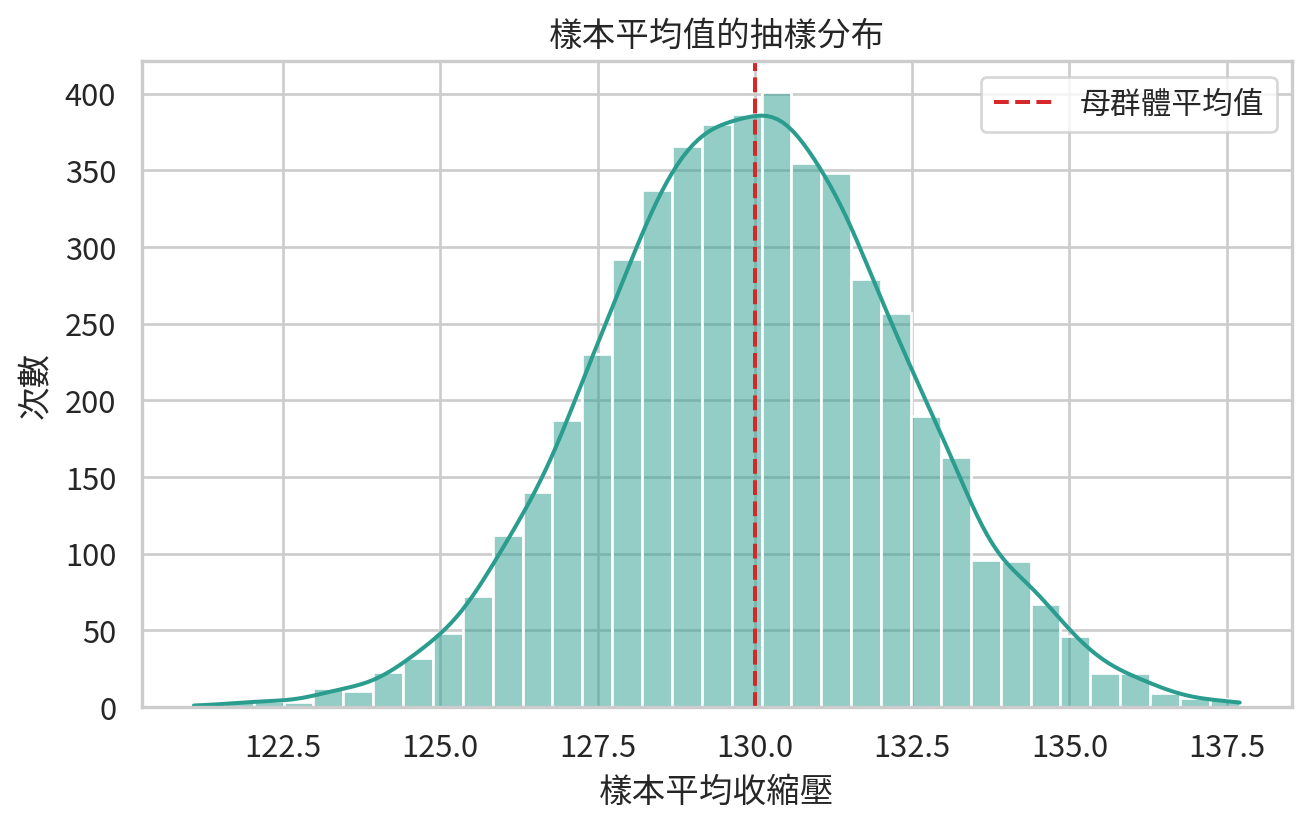
範例 1:樣本平均值的抽樣分布
假設某族群收縮壓平均值為 130 mmHg、標準差為 15 mmHg。每次抽 40 位病人並計算樣本平均值,重複 5000 次。
population_mean = 130
population_sd = 15
n = 40
sample_means = np.random.normal(population_mean, population_sd, size=(5000, n)).mean(axis=1)
sampling_df = pd.DataFrame({"sample_mean": sample_means})
sampling_df.describe().round(3)
| count |
5000.000 |
| mean |
129.946 |
| std |
2.409 |
| min |
121.086 |
| 25% |
128.313 |
| 50% |
129.944 |
| 75% |
131.538 |
| max |
137.705 |
plt.figure(figsize=(7, 4.5))
sns.histplot(data=sampling_df, x="sample_mean", bins=35, kde=True, color="#2a9d8f")
plt.axvline(population_mean, color="#d62828", linestyle="--", label="母群體平均值")
plt.xlabel("樣本平均收縮壓")
plt.ylabel("次數")
plt.title("樣本平均值的抽樣分布")
plt.legend()
plt.tight_layout()
plt.savefig(FIG_DIR / "ch06_sampling_distribution_mean.png", dpi=300)
plt.show()
圖中每個值都是一次研究可能得到的樣本平均值。它們集中在真實平均值附近,但每次都不一樣。這就是為什麼單一研究結果需要信賴區間,而不是只報一個看似篤定的數字。
中央極限定理
中央極限定理 (central limit theorem, CLT) 是統計推論的基石。粗略地說,只要樣本數夠大,樣本平均值的抽樣分布會趨近常態分布,即使原始資料本身不完全常態。
這個定理讓我們能用常態或 t 分布近似許多估計量的不確定性。它不是說「所有資料都會變常態」,而是說「許多統計量的抽樣分布會趨近常態」。這差別很重要,請不要讓原始資料被迫戴上常態分布的帽子。
中央極限定理也解釋了為什麼樣本數越大,估計越穩定:
\[
SE(\bar{X}) = \frac{\sigma}{\sqrt{n}}
\]
當 \(n\) 增加,標準誤會下降,但下降速度是平方根,不是線性。樣本數要變成 4 倍,標準誤才會減半。統計在這裡很實際:想要更窄的信賴區間,通常要付出不少樣本數。
信賴區間的基本想法
信賴區間是用來量化估計不確定性的區間。一般形式可寫成:
\[
\text{估計值} \pm \text{臨界值} \times \text{標準誤}
\]
對母群體平均值而言,若母群體標準差未知且樣本數不大,常使用 t 分布:
\[
\bar{x} \pm t_{0.975, n-1}\frac{s}{\sqrt{n}}
\]
其中 \(t_{0.975, n-1}\) 是自由度 \(n-1\) 的 t 分布第 97.5 百分位數。為什麼是 97.5?因為 95% 信賴區間把剩下 5% 分到兩端,每端 2.5%。
範例 2:平均收縮壓的 95% 信賴區間
alpha = 0.05
critical_t = t.ppf(1 - alpha / 2, df=sample_n - 1)
ci_lower = sample_mean - critical_t * se_mean
ci_upper = sample_mean + critical_t * se_mean
mean_ci_table = pd.DataFrame(
{
"quantity": ["樣本平均值", "標準誤", "t 臨界值", "95% CI 下限", "95% CI 上限"],
"value": [sample_mean, se_mean, critical_t, ci_lower, ci_upper],
}
)
mean_ci_table.round(3)
| 0 |
樣本平均值 |
140.867 |
| 1 |
標準誤 |
2.169 |
| 2 |
t 臨界值 |
2.145 |
| 3 |
95% CI 下限 |
136.215 |
| 4 |
95% CI 上限 |
145.518 |
這個信賴區間的正確解釋是:若我們用同樣方式重複抽樣並每次建立 95% 信賴區間,長期約 95% 的區間會涵蓋真實母群體平均值。它不是說「真實平均值有 95% 機率在這個已算出的區間內」。真實參數是固定的,會不會落在這個區間內已經是事實;不確定的是我們的抽樣過程。
這句話有點繞,初學時正常。信賴區間像釣魚網:95% 是指這種網長期撈到真魚的比例,不是指某一條已經撈上岸的魚有 95% 機率在網裡。
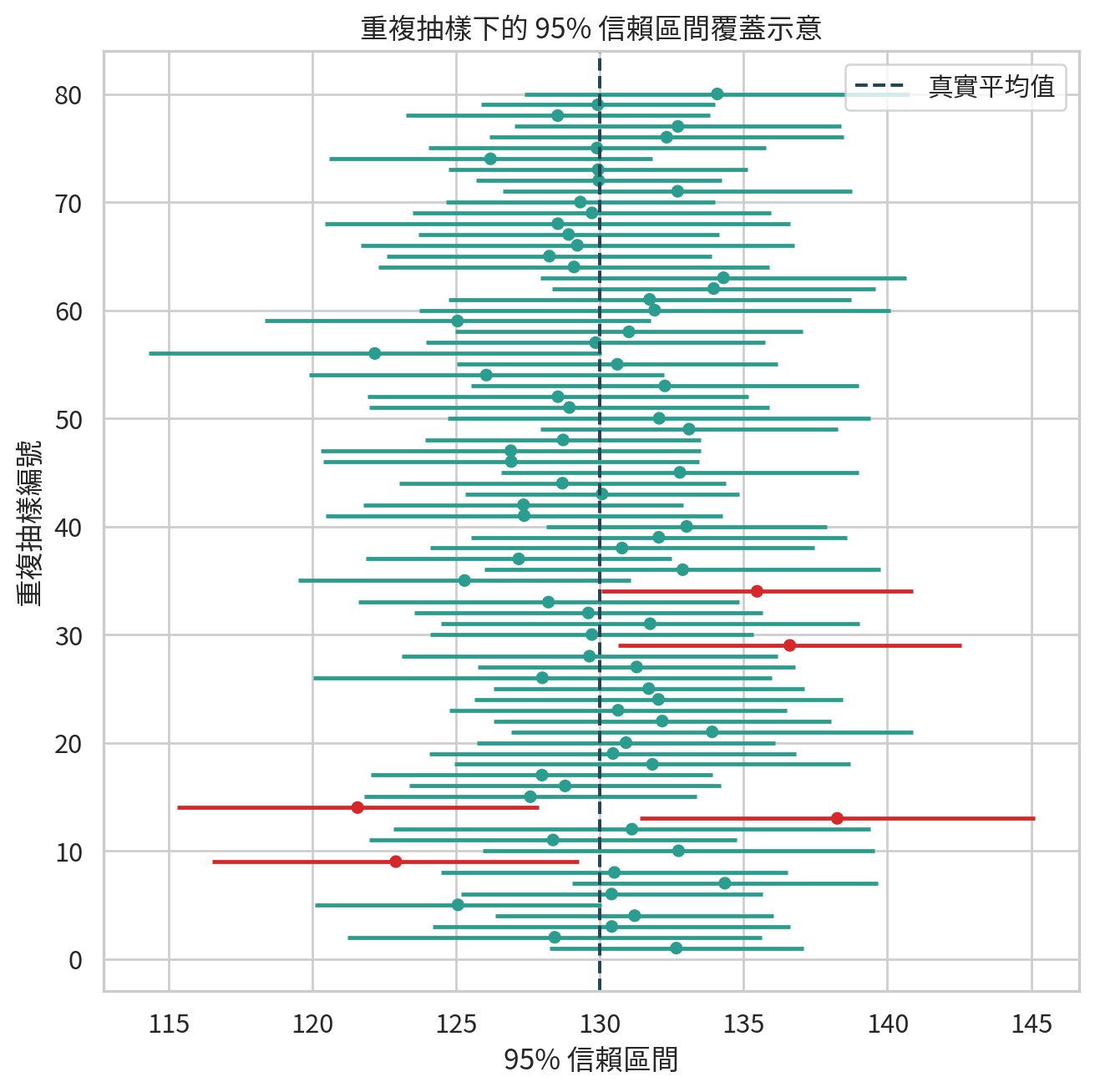
範例 3:信賴區間覆蓋率模擬
我們用模擬看看 95% 信賴區間的長期意義。每次從同一母群體抽 25 位病人,建立平均值的 95% 信賴區間,重複 80 次。
coverage_n = 25
sim_samples = np.random.normal(population_mean, population_sd, size=(80, coverage_n))
means = sim_samples.mean(axis=1)
sds = sim_samples.std(axis=1, ddof=1)
critical = t.ppf(0.975, df=coverage_n - 1)
lower = means - critical * sds / np.sqrt(coverage_n)
upper = means + critical * sds / np.sqrt(coverage_n)
coverage_df = pd.DataFrame(
{
"replicate": np.arange(1, 81),
"mean": means,
"lower": lower,
"upper": upper,
"covers": (lower <= population_mean) & (population_mean <= upper),
}
)
coverage_df["covers"].mean().round(3)
plt.figure(figsize=(7, 7))
colors = coverage_df["covers"].map({True: "#2a9d8f", False: "#d62828"})
plt.hlines(coverage_df["replicate"], coverage_df["lower"], coverage_df["upper"], color=colors, linewidth=1.8)
plt.scatter(coverage_df["mean"], coverage_df["replicate"], color=colors, s=22)
plt.axvline(population_mean, color="#264653", linestyle="--", label="真實平均值")
plt.xlabel("95% 信賴區間")
plt.ylabel("重複抽樣編號")
plt.title("重複抽樣下的 95% 信賴區間覆蓋示意")
plt.legend()
plt.tight_layout()
plt.savefig(FIG_DIR / "ch06_ci_coverage_simulation.png", dpi=300)
plt.show()
少數區間沒有涵蓋真實平均值,這不是錯誤,而是 95% 信賴區間的自然結果。若每個區間都涵蓋真值,那大概不是信賴區間太神,就是我們偷偷看了答案。
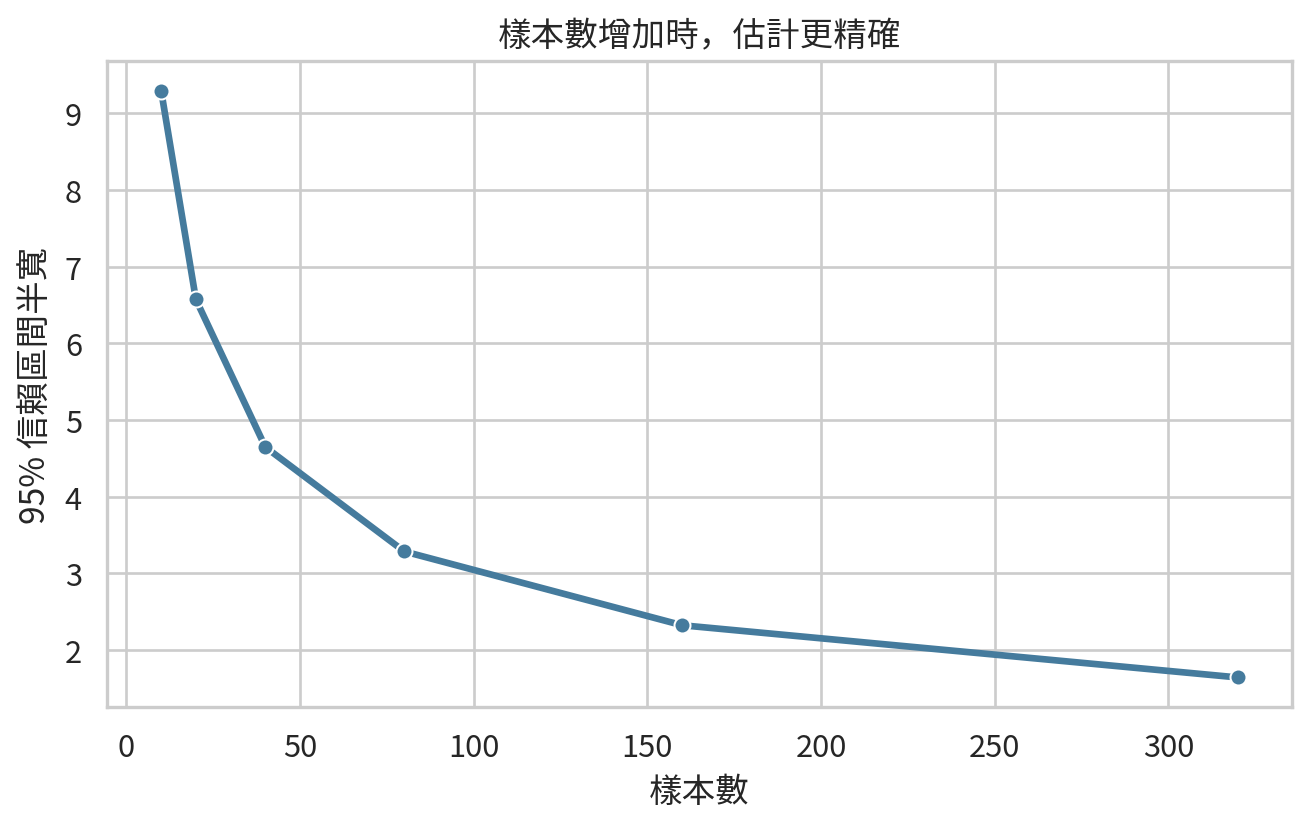
樣本數與信賴區間寬度
估計精確度與樣本數密切相關。對平均值來說,信賴區間半寬大約與 \(1/\sqrt{n}\) 成正比:
\[
\text{半寬} \approx 1.96 \frac{\sigma}{\sqrt{n}}
\]
sample_sizes = np.array([10, 20, 40, 80, 160, 320])
ci_width_df = pd.DataFrame(
{
"sample_size": sample_sizes,
"half_width": norm.ppf(0.975) * population_sd / np.sqrt(sample_sizes),
}
)
ci_width_df.round(2)
| 0 |
10 |
9.30 |
| 1 |
20 |
6.57 |
| 2 |
40 |
4.65 |
| 3 |
80 |
3.29 |
| 4 |
160 |
2.32 |
| 5 |
320 |
1.64 |
plt.figure(figsize=(7, 4.5))
sns.lineplot(data=ci_width_df, x="sample_size", y="half_width", marker="o", linewidth=2.5, color="#457b9d")
plt.xlabel("樣本數")
plt.ylabel("95% 信賴區間半寬")
plt.title("樣本數增加時,估計更精確")
plt.tight_layout()
plt.savefig(FIG_DIR / "ch06_ci_width_by_sample_size.png", dpi=300)
plt.show()
圖中可以看到,從 10 人增加到 40 人,信賴區間明顯縮小;但從 160 人增加到 320 人,改善幅度較小。這就是研究設計中常見的取捨:更多樣本通常更好,但成本、時間、倫理與可行性都要一起考量。
母群體比例的估計
許多醫學問題關心的是比例,例如 30 天再住院率、疫苗接種率、篩檢陽性率、治療反應率。若樣本中有 \(x\) 位發生事件,樣本數為 \(n\),母群體比例 \(p\) 的點估計為:
\[
\hat{p} = \frac{x}{n}
\]
當樣本數夠大時,樣本比例的標準誤可估為:
\[
SE(\hat{p}) = \sqrt{\frac{\hat{p}(1-\hat{p})}{n}}
\]
95% 信賴區間可近似為:
\[
\hat{p} \pm 1.96 SE(\hat{p})
\]
範例 4:30 天再住院率的信賴區間
假設某醫院追蹤 240 位出院病人,其中 38 位在 30 天內再住院。估計 30 天再住院率與其 95% 信賴區間。
readmitted = 38
total = 240
p_hat = readmitted / total
se_prop = np.sqrt(p_hat * (1 - p_hat) / total)
z_critical = norm.ppf(0.975)
prop_ci_lower = p_hat - z_critical * se_prop
prop_ci_upper = p_hat + z_critical * se_prop
pd.DataFrame(
{
"quantity": ["樣本比例", "標準誤", "95% CI 下限", "95% CI 上限"],
"value": [p_hat, se_prop, prop_ci_lower, prop_ci_upper],
}
).round(4)
| 0 |
樣本比例 |
0.1583 |
| 1 |
標準誤 |
0.0236 |
| 2 |
95% CI 下限 |
0.1121 |
| 3 |
95% CI 上限 |
0.2045 |
比例信賴區間有多種方法,例如 Wald、Wilson、exact binomial 等。上面是最直覺的 Wald 近似,但在樣本數小或比例接近 0 或 1 時表現不好。實務上常建議使用 Wilson 區間;我們在類別資料章節會再遇到。
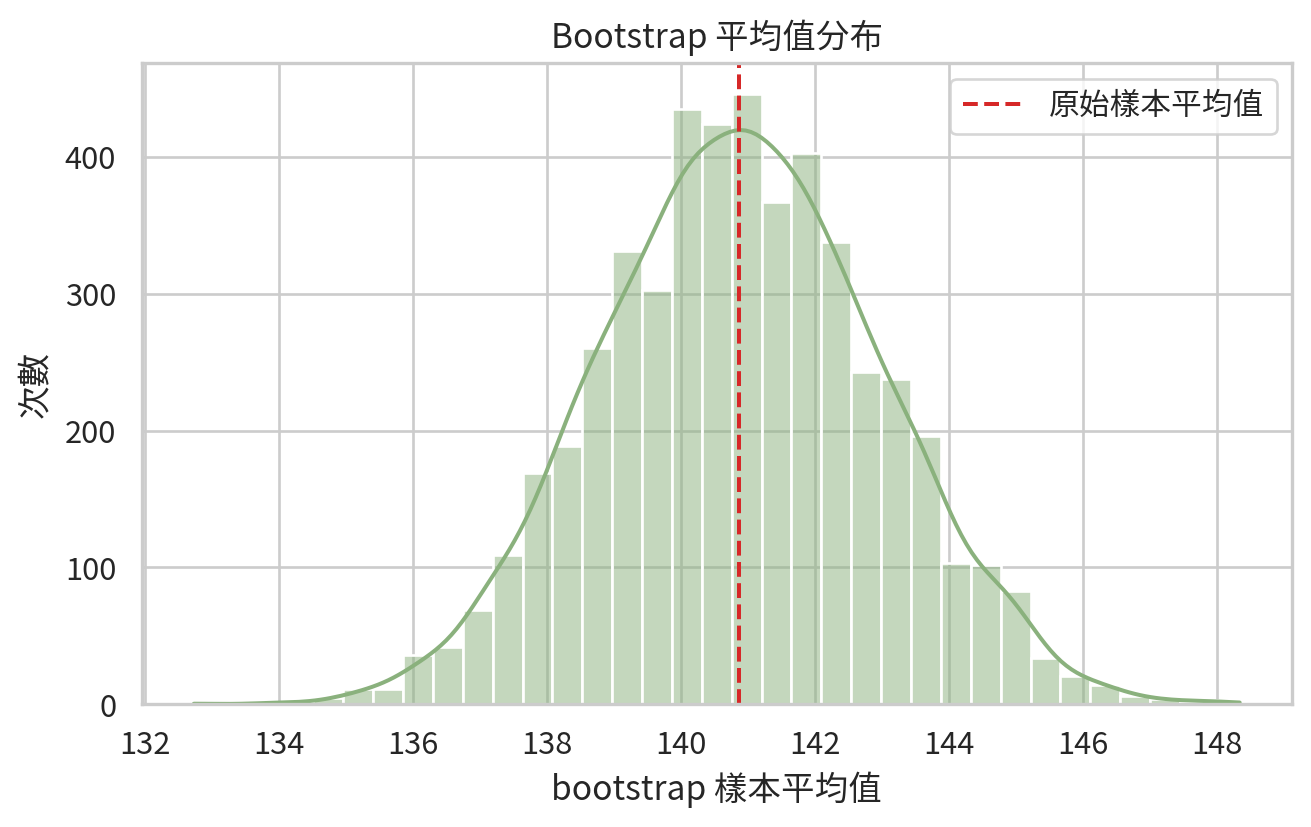
Bootstrap:讓資料自己說明不確定性
Bootstrap 是一種重抽樣 (resampling) 方法。它從原始樣本中「有放回」抽樣很多次,每次計算統計量,形成 bootstrap 分布。這個分布可用來估計標準誤或建立信賴區間。
Bootstrap 的直覺是:如果原始樣本是母群體的一個縮影,那麼從原始樣本反覆重抽樣,可以模擬「再做一次研究」時估計值可能如何變動。它很靈活,尤其適合統計量複雜或公式標準誤不容易推導的情境。
bootstrap_means = np.array(
[np.random.choice(bp_sample, size=len(bp_sample), replace=True).mean() for _ in range(5000)]
)
bootstrap_ci = np.quantile(bootstrap_means, [0.025, 0.975])
bootstrap_se = bootstrap_means.std(ddof=1)
pd.DataFrame(
{
"quantity": ["原始樣本平均值", "Bootstrap SE", "Bootstrap 95% CI 下限", "Bootstrap 95% CI 上限"],
"value": [bp_sample.mean(), bootstrap_se, bootstrap_ci[0], bootstrap_ci[1]],
}
).round(3)
| 0 |
原始樣本平均值 |
140.867 |
| 1 |
Bootstrap SE |
2.078 |
| 2 |
Bootstrap 95% CI 下限 |
136.933 |
| 3 |
Bootstrap 95% CI 上限 |
144.935 |
bootstrap_df = pd.DataFrame({"bootstrap_mean": bootstrap_means})
plt.figure(figsize=(7, 4.5))
sns.histplot(data=bootstrap_df, x="bootstrap_mean", bins=35, kde=True, color="#8ab17d")
plt.axvline(bp_sample.mean(), color="#d62828", linestyle="--", label="原始樣本平均值")
plt.xlabel("bootstrap 樣本平均值")
plt.ylabel("次數")
plt.title("Bootstrap 平均值分布")
plt.legend()
plt.tight_layout()
plt.savefig(FIG_DIR / "ch06_bootstrap_mean_distribution.png", dpi=300)
plt.show()
Bootstrap 不是萬能藥。如果原始樣本很小、抽樣偏差很嚴重,bootstrap 只會很認真地重複原始樣本的問題。它像影印機:可以幫你複製資料中的不確定性,但不能把模糊的原稿變成高清照片。
信賴區間常見誤解
信賴區間是醫學論文中最常見也最常被誤解的工具之一。請特別注意:
- 95% 信賴區間不是「真實值有 95% 機率在此區間內」。
- 信賴區間窄不代表研究沒有偏差;它只表示隨機誤差較小。
- 信賴區間包含臨床上不重要的效果時,即使統計顯著也要小心解讀。
- 信賴區間很寬通常代表資料不足、變異大,或估計不穩。
- 信賴區間是估計工具,不是單純拿來取代 p 值的裝飾品。
好的研究報告不只說「有差」或「沒差」,而是說差多少、可能範圍多大、這個範圍在臨床上是否重要。
本章重點整理
- 估計是用樣本資料推測母群體參數。
- 點估計提供單一最佳猜測;區間估計提供合理範圍。
- 標準誤描述估計量在重複抽樣下的波動程度。
- 信賴區間的一般形式是估計值加減臨界值乘以標準誤。
- 95% 信賴區間的長期意義是重複抽樣下約 95% 的區間涵蓋真實參數。
- 樣本數越大,標準誤通常越小,但改善速度與平方根有關。
- Bootstrap 可用重抽樣方式估計不確定性,但無法修正原始抽樣偏差。
小練習
- 某研究 25 位病人的平均 LDL-C 為 118 mg/dL,標準差 30 mg/dL,建立平均 LDL-C 的 95% t 信賴區間。
- 某篩檢計畫 600 人中 72 人陽性,估計陽性率與近似 95% 信賴區間。
- 若母群體標準差固定,樣本數從 50 增加到 200,標準誤會變成原來的幾倍?
- 解釋「信賴區間很窄但估計有偏差」可能代表什麼情況。
- 用 bootstrap 對
bp_sample 的中位數建立 95% 百分位信賴區間。
ldl_mean = 118
ldl_sd = 30
ldl_n = 25
ldl_se = ldl_sd / np.sqrt(ldl_n)
ldl_critical = t.ppf(0.975, df=ldl_n - 1)
ldl_ci = (ldl_mean - ldl_critical * ldl_se, ldl_mean + ldl_critical * ldl_se)
positive = 72
screened = 600
positive_rate = positive / screened
positive_se = np.sqrt(positive_rate * (1 - positive_rate) / screened)
positive_ci = (
positive_rate - norm.ppf(0.975) * positive_se,
positive_rate + norm.ppf(0.975) * positive_se,
)
se_ratio = np.sqrt(50 / 200)
bootstrap_medians = np.array(
[np.median(np.random.choice(bp_sample, size=len(bp_sample), replace=True)) for _ in range(5000)]
)
median_ci = np.quantile(bootstrap_medians, [0.025, 0.975])
pd.DataFrame(
{
"問題": [
"LDL-C 平均值 95% CI 下限",
"LDL-C 平均值 95% CI 上限",
"篩檢陽性率",
"陽性率 95% CI 下限",
"陽性率 95% CI 上限",
"n=200 相對 n=50 的 SE 倍數",
"收縮壓中位數 bootstrap CI 下限",
"收縮壓中位數 bootstrap CI 上限",
],
"數值": [
ldl_ci[0],
ldl_ci[1],
positive_rate,
positive_ci[0],
positive_ci[1],
se_ratio,
median_ci[0],
median_ci[1],
],
}
).round(4)
| 0 |
LDL-C 平均值 95% CI 下限 |
105.6166 |
| 1 |
LDL-C 平均值 95% CI 上限 |
130.3834 |
| 2 |
篩檢陽性率 |
0.1200 |
| 3 |
陽性率 95% CI 下限 |
0.0940 |
| 4 |
陽性率 95% CI 上限 |
0.1460 |
| 5 |
n=200 相對 n=50 的 SE 倍數 |
0.5000 |
| 6 |
收縮壓中位數 bootstrap CI 下限 |
136.0000 |
| 7 |
收縮壓中位數 bootstrap CI 上限 |
148.0000 |
Glossary
| 估計 |
estimation |
用樣本資料推測母群體參數的統計程序。 |
| 點估計 |
point estimation |
用單一數值估計母群體參數。 |
| 區間估計 |
interval estimation |
用一段區間估計母群體參數可能範圍。 |
| 估計量 |
estimator |
用來估計參數的統計方法或公式。 |
| 估計值 |
estimate |
由特定樣本計算出的估計結果。 |
| 參數 |
parameter |
描述母群體特性的未知真實值。 |
| 統計量 |
statistic |
由樣本資料計算出的數值。 |
| 偏差 |
bias |
估計量長期平均與真實參數之間的差異。 |
| 精確度 |
precision |
估計值在重複抽樣中分散程度的概念。 |
| 均方誤差 |
mean squared error, MSE |
結合估計量變異與偏差平方的誤差指標。 |
| 抽樣分布 |
sampling distribution |
統計量在重複抽樣下形成的機率分布。 |
| 標準誤 |
standard error, SE |
估計量抽樣分布的標準差。 |
| 母群體平均值 |
population mean |
母群體中連續變項的真實平均值。 |
| 母群體比例 |
population proportion |
母群體中具有某特徵的真實比例。 |
| 中央極限定理 |
central limit theorem, CLT |
樣本數夠大時,樣本平均值抽樣分布趨近常態的定理。 |
| 信賴區間 |
confidence interval, CI |
用來量化參數估計不確定性的區間。 |
| 臨界值 |
critical value |
建立信賴區間或檢定時使用的分布分位數。 |
| 覆蓋率 |
coverage probability |
重複抽樣下信賴區間涵蓋真實參數的長期比例。 |
| 重抽樣 |
resampling |
從既有資料反覆抽樣以評估統計量不確定性的方法。 |
| Bootstrap |
bootstrap |
從原始樣本有放回重抽樣以估計不確定性的方法。 |
| 百分位信賴區間 |
percentile confidence interval |
使用 bootstrap 統計量分位數建立的信賴區間。 |